5.3 二分类:使用惩罚线性回归来检测未爆炸的水雷
第 4 章讨论了如何使用惩罚线性回归方法来解决分类问题,并且给出了岩石 - 水雷问题的求解过程。本节将详细介绍如何使用惩罚线性回归来求解二分类问题,具体使用Python 的 ElasticNet 包。第 4 章讲到 ElasticNet 引入了一个更普通的惩罚函数,套索以及岭回归的惩罚函数只是该函数的一个特殊情形。随着更换惩罚函数,可以看到分类器的性能的变化。以下是求解的步骤。
(1)将二分类问题转换为回归问题。构建一个包含实数标签的向量,将其中一个类别输出设为 0,另一个类别输出设为 1。
(2)执行交叉验证。因为需要对每一份数据计算错误,交叉验证稍微复杂。Scikit-learn 包含一些便捷的功能来将这些计算流水化。
第一步(正如第 4 章所述)是将二分类问题转换为回归问题:通过将类别标签转换为实数值。岩石 - 水雷问题的目标是构建一个系统,该系统使用声纳来检测海床上的水雷。
回忆第 2 章对该数据集的介绍,该数据集包含从岩石以及形状类似水雷的金属柱返回的数字信号。目标是构建一个预测系统,该系统可以对数字信号进行处理来正确识别对象是岩石还是水雷。数据集包含 208 次实验,其中 111 次实验对应的结果是水雷,97 次实验对应的结果是岩石。数据集包含 61 列。前面 60 列是数字声纳,最后 1 列是岩石或者水雷,对应取值为M或者R。前面60列是用于预测的属性。最后1列标签需要使用数值来表示(即使回归也需要数值表示)。第 4 章通过将数字 1 赋给其中一个标签、将 0 赋给另一个标签来构建数值标签。代码清单 5-4 初始化了一个空的标签列表,将每个 M 行的标签值设为 1,将每个 R 行的标签值设为 0。
有了数值属性以及数值标签,就可以使用回归版本的惩罚线性回归方法了。下一步是执行交叉验证,以获得对模型在样本外数据上的性能估计,并找到最佳的惩罚项参数 α。对于这个问题,交叉验证需要构建一个交叉验证循环来封装训练集以及测试集。为什么要构建一个交叉验证循环,而不是使用 Python 中现成的交叉验证包(类似于本章前面提到的红酒品质预测的例子)?
面向回归的交叉验证基于MSE。MSE对于回归问题是合理的,但对于分类问题则不是。
正如第 3 章所讨论的,分类问题与回归问题使用的性能度量指标不同。第 3 章讨论了度量性能几种方法。一种自然的度量方式是计算误分类样本所占的比例。另一种方式是度量 AUC。参照第 3 章或者 Wikipedia 页面 http://en.wikipedia.org/wiki/Receiver_operating_characteristic 来回顾 AUC 指标的计算方法。为了计算指标,需要访问交叉验证中的每一份数据,并获取其中的所有预测值以及实际值。不能只基于一份数据的 MSE 来评估误分类错误。
交叉验证循环将数据切分为训练集以及测试集,然后调用 Python 的 enet_path 方法在训练数据上完成训练。程序的两个输入与默认输入不同。一个是 l1_ratio,该值被设置为0.8。该参数决定了系数绝对值和的惩罚项占所有惩罚项的权重比例。0.8 代表惩罚项使用80% 的绝对值和以及 20% 的均方误差和。另一个需要指定的参数是 fit_intercept,该值被设置为 False。代码使用归一化的标签以及归一化的属性。因为所有这些属性都是 0 均值的,所以不需要计算插值项。只有属性以及标签期望存在偏差时,才需要增加一个常数插值项。
使用归一化标签来消除插值项会使预测计算更加清晰,但也会使对应 MSE 的意义不直观。
不过对于分类问题,我们不会使用 MSE 来度量性能。
对每一折验证,训练得到的系数用于在测试数据上生成预测,对应代码实现使用numpy 点乘函数、使用样本外数据的属性值以及当前训练得到的系数。2 个 numpy 数组相乘得到另外一个二维数组,该数组的行对应样本外的测试数据,该数组的列对应由enet_path(对应于系数向量序列以及 α 序列)生成的模型序列。每一折交叉验证对应的预测矩阵被拼接到一起(视觉上相当于把一个矩阵叠加到另一个矩阵上)作为样本外数据的标签。在运行的最后,这些按折生成的样本外数据的预测结果可以被高效处理,用于生成每个模型的性能指标,从中可以挑选一个合适的复杂度(α)对应的模型进行部署。
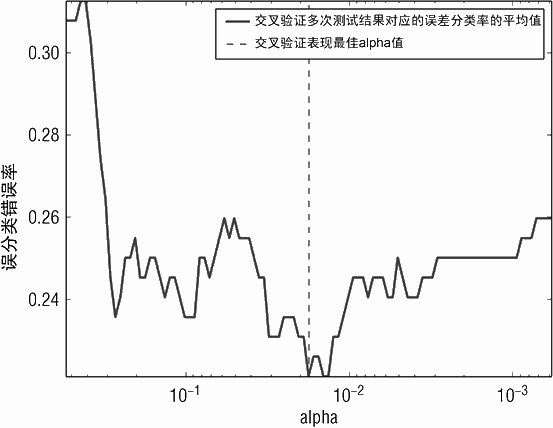
代码清单 5-4 给出了基于两种指标的对比结果。第一个指标是误分类错误。第二个指标是信号接收曲线的曲线下的面积(即 ROC)。预测矩阵的每一列代表使用一组模型系数在样本外数据上运算得到的预测结果。预测数据表示为 1 列是因为每次交叉验证会预留出一行数据。误分类计算使用生成的预测类别以及对应的实际标签类别(代码中称作 yOut)比较,其中生成的预测类别是通过比较预测值和固定阈值(本例中的 0.0)得到的。通过比较预测类别和实际标签 yOut,可以确定预测是否正确。图 5-7 展示了性能取到相同最小值的几个点。在性能随 α 变化的图上,选择离左边较远的点往往是一个不错方案。因为右侧的点更容易充分拟合数据。选择离左边较远的解是相对保守的方案,在这种情况下,很有可能部署错误与交叉验证的错误程度一致。
度量分类器性能的另一种方式是 AUC。AUC 的优势是通过最大化 AUC,能获得最佳性能并且与应用场景无关,不论是为不同错误类型设置权重,还是重点关注某类数据的分类正确率。严格来讲,最大化 AUC 不能确保在一个特定的错误率上获得最优性能。
通过对比 AUC 选择的模型、通过最小化错误率得到的模型以及观察曲线形状会帮助获得对解的信心,同时能了解到通过彻底的优化性能指标,还能在多大程度上提高性能。
代码清单 5-4 中 AUC 的计算使用来自 sklearn 的 roc_curve 以及 roc_auc_score 程序。
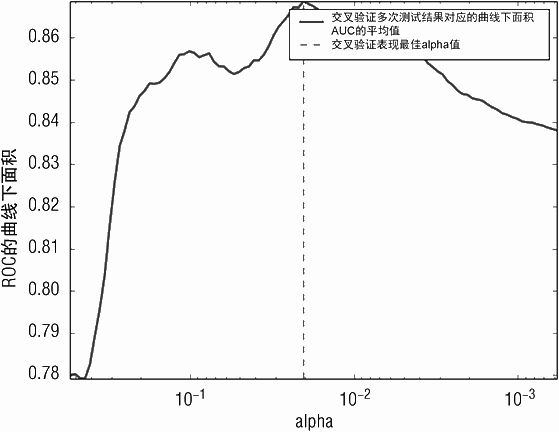
生成 AUC 随 α 变化的曲线类似于计算误分类错误的过程,不同在于模型生成的预测值以及真正的标签值被传送给 roc_auc_score 程序来计算 AUC。图 5-8 绘制了这些 AUC的值。生成的曲线从上往下看类似于误分类错误曲线,从上到下是因为 AUC 的值越大越好,误分类错误越小越好。代码清单 5-4 的打印输出显示基于误分类错误的最优模型与基于 AUC 的最优模型不完全相同,但它们距离不大。图 5-9 为最大化 AUC 分类器的ROC 曲线。

在这个问题中,一些错误相对于其他错误的可能代价更大,你想使预测结果离代价大的错误更远。对于岩石水雷问题,如果将未爆炸的水雷作为岩石,可能比将岩石误分类为水雷代价更大。
处理这类问题的一种系统性的方法是使用混淆矩阵(如第 3 章讨论的)。基于 roc_curve 程序输出很容易构建混淆矩阵。ROC 曲线上的点对应于不同的阈值。点(1,1)对应一个极端情况,即阈值设置为最低值,所有点都被分类为水雷。这使得真正率和假负率等于 1。分类器使所有的正例在右边,但同时也错分了所有负例。将阈值设置为比所有点都高,生成了图形的另一角。为了获得点在困惑矩阵不同方框内的移动细节需要挑一些阈值然后打印结果。代码清单 5-4 展示了 3 个阈值,这些阈值对应所有阈值的分位点阈值(不包含最后点)。设置高阈值导致低的假正率和高的假负率。设置低阈值产生相反效果。
将阈值设为中间值更接近于对两类错误进行平衡。
可以为每类错误赋权重、最小化总代价来获得最佳阈值。输出的 3 个混淆矩阵可以作为一个例子来说明背后的工作原理。如果假正样本和假负样本都会花费 1 美元,中间表(对应于阈值 -0.0455)给出的总代价为 46 美元,更高阈值对应的代价为 68 美元,更低阈值代价为 54 美元。然而,如果假正的代价为 10 美元,假负的代价为 1 美元,更高阈值对应代价为 113 美元,中间阈值对应的代价为 226 美元,较低阈值对应的代价为 504 美元。
此时,你会希望在更细粒度上测试阈值。总体上,为了达到好的效果,需要合理设置代价,同时要确保训练集的正例与负例的比例与实际情况相一致。岩石水雷问题的样本数据来源于实验环境,可能并不完全代表港口中实际的岩石水雷数字。这个很容易通过对其中一个类别进行抽样来修复,即复制一个类别的部分样本使该类样本数占总体样本数的比例与实际部署环境中的比例相一致。
对于岩石水雷数据,对应的训练集是均衡的,即正例和负例样本数几乎相同。在一些数据集中,可能其中一个类别的样本数要更多。例如,因特网广告的点击率只占所有展示广告很小的比例,远小于 1%。通过增强样本数较少的类别,使二类比例相接近可以获得更好的训练结果。可以通过复制样本数较少的类别样本或者移除样本数较多的类别样本来达到上述目的。
代码清单 5-4 使用 ElasticNet 回归构建二分类器 -rocksVMinesENetRegCV.py
__author__ = 'mike_bowles'
import urllib2
from math import sqrt, fabs, exp
import matplotlib.pyplot as plot
from sklearn.linear_model import enet_path
from sklearn.metrics import roc_auc_score, roc_curve
import numpy
#read data from uci data repository
target_url = ("https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data")
data = urllib2.urlopen(target_url)
#arrange data into list for labels and list of lists for attributes
xList = []
for line in data:
#split on comma
row = line.strip().split(",")
xList.append(row)
#separate labels from attributes, convert from attributes from string
#to numeric and convert "M" to 1 and "R" to 0
xNum = []
labels = []
for row in xList:
lastCol = row.pop()
if lastCol == "M":
labels.append(1.0)
else:
labels.append(0.0)
attrRow = [float(elt) for elt in row]
xNum.append(attrRow)
#number of rows and columns in x matrix
nrow = len(xNum)
ncol = len(xNum[1])
alpha = 1.0
#calculate means and variances
xMeans = []
xSD = []
for i in range(ncol):
col = [xNum[j][i] for j in range(nrow)]
mean = sum(col)/nrow
xMeans.append(mean)
colDiff = [(xNum[j][i] - mean) for j in range(nrow)]
sumSq = sum([colDiff[i] * colDiff[i] for i in range(nrow)])
stdDev = sqrt(sumSq/nrow)
xSD.append(stdDev)
#use calculate mean and standard deviation to normalize xNum
xNormalized = []
for i in range(nrow):
rowNormalized = [(xNum[i][j] - xMeans[j])/xSD[j] \
for j in range(ncol)]
xNormalized.append(rowNormalized)
#normalize labels to center
#Normalize labels
meanLabel = sum(labels)/nrow
sdLabel = sqrt(sum([(labels[i] - meanLabel) * (labels[i] - meanLabel) \
for i in range(nrow)])/nrow)
labelNormalized = [(labels[i] - meanLabel)/sdLabel for i in range(nrow)]
#number of cross-validation folds
nxval = 10
for ixval in range(nxval):
#Define test and training index sets
idxTest = [a for a in range(nrow) if a%nxval == ixval%nxval]
idxTrain = [a for a in range(nrow) if a%nxval != ixval%nxval]
#Define test and training attribute and label sets
xTrain = numpy.array([xNormalized[r] for r in idxTrain])
xTest = numpy.array([xNormalized[r] for r in idxTest])
labelTrain = numpy.array([labelNormalized[r] for r in idxTrain])
labelTest = numpy.array([labelNormalized[r] for r in idxTest])
alphas, coefs, _ = enet_path(xTrain, labelTrain,l1_ratio=0.8,
fit_intercept=False, return_models=False)
#apply coefs to test data to produce predictions and accumulate
if ixval == 0:
pred = numpy.dot(xTest, coefs)
yOut = labelTest
else:
#accumulate predictions
yTemp = numpy.array(yOut)
yOut = numpy.concatenate((yTemp, labelTest), axis=0)
#accumulate predictions
predTemp = numpy.array(pred)
pred = numpy.concatenate((predTemp, numpy.dot(xTest, coefs)),
axis = 0)
#calculate misclassification error
misClassRate = []
_,nPred = pred.shape
for iPred in range(1, nPred):
predList = list(pred[:, iPred])
errCnt = 0.0
for irow in range(nrow):
if (predList[irow] < 0.0) and (yOut[irow] >= 0.0):
errCnt += 1.0
elif (predList[irow] >= 0.0) and (yOut[irow] < 0.0):
errCnt += 1.0
misClassRate.append(errCnt/nrow)
#find minimum point for plot and for print
minError = min(misClassRate)
idxMin = misClassRate.index(minError)
plotAlphas = list(alphas[1:len(alphas)])
plot.figure()
plot.plot(plotAlphas, misClassRate,
label='Misclassification Error Across Folds', linewidth=2)
plot.axvline(plotAlphas[idxMin], linestyle='--',
label='CV Estimate of Best alpha')
plot.legend()
plot.semilogx()
ax = plot.gca()
ax.invert_xaxis()
plot.xlabel('alpha')
plot.ylabel('Misclassification Error')
plot.axis('tight')
plot.show()
#calculate AUC.
idxPos = [i for i in range(nrow) if yOut[i] > 0.0]
yOutBin = [0] * nrow
for i in idxPos: yOutBin[i] = 1
auc = []
for iPred in range(1, nPred):
predList = list(pred[:, iPred])
aucCalc = roc_auc_score(yOutBin, predList)
auc.append(aucCalc)
maxAUC = max(auc)
idxMax = auc.index(maxAUC)
plot.figure()
plot.plot(plotAlphas, auc, label='AUC Across Folds', linewidth=2)
plot.axvline(plotAlphas[idxMax], linestyle='--',
label='CV Estimate of Best alpha')
plot.legend()
plot.semilogx()
ax = plot.gca()
ax.invert_xaxis()
plot.xlabel('alpha')
plot.ylabel('Area Under the ROC Curve')
plot.axis('tight')
plot.show()
#plot best version of ROC curve
fpr, tpr, thresh = roc_curve(yOutBin, list(pred[:, idxMax]))
ctClass = [i*0.01 for i in range(101)]
plot.plot(fpr, tpr, linewidth=2)
plot.plot(ctClass, ctClass, linestyle=':')
plot.xlabel('False Positive Rate')
plot.ylabel('True Positive Rate')
plot.show()
print('Best Value of Misclassification Error = ', misClassRate[idxMin])
print('Best alpha for Misclassification Error = ', plotAlphas[idxMin])
print('')
print('Best Value for AUC = ', auc[idxMax])
print('Best alpha for AUC = ', plotAlphas[idxMax])
print('')
print('Confusion Matrices for Different Threshold Values')
#pick some points along the curve to print. There are 208 points.
#The extremes aren't useful
#Sample at 52, 104 and 156. Use the calculated values of tpr and fpr
#along with definitions and threshold values.
#Some nomenclature (e.g. see wikipedia "receiver operating curve")
#P = Positive cases
P = len(idxPos)
#N = Negative cases
N = nrow - P
#TP = True positives = tpr * P
TP = tpr[52] * P
#FN = False negatives = P - TP
FN = P - TP
#FP = False positives = fpr * N
FP = fpr[52] * N
#TN = True negatives = N - FP
TN = N - FP
print('Threshold Value = ', thresh[52])
print('TP = ', TP, 'FP = ', FP)
print('FN = ', FN, 'TN = ', TN)
TP = tpr[104] * P; FN = P - TP; FP = fpr[104] * N; TN = N - FP
print('Threshold Value = ', thresh[104])
print('TP = ', TP, 'FP = ', FP)
print('FN = ', FN, 'TN = ', TN)
TP = tpr[156] * P; FN = P - TP; FP = fpr[156] * N; TN = N - FP
print('Threshold Value = ', thresh[156])
print('TP = ', TP, 'FP = ', FP)
print('FN = ', FN, 'TN = ', TN)
Printed Output: [filename - rocksVMinesENetRegCVPrintedOutput.txt]
('Best Value of Misclassification Error = ', 0.22115384615384615)
('Best alpha for Misclassification Error = ', 0.017686244720179375)
('Best Value for AUC = ', 0.86867279650784812)
('Best alpha for AUC = ', 0.020334883589342503)
Confusion Matrices for Different Threshold Values
('Threshold Value = ', 0.37952298245219962)
('TP = ', 48.0, 'FP = ', 5.0)
('FN = ', 63.0, 'TN = ', 92.0)
('Threshold Value = ', -0.045503481125357965)
('TP = ', 85.0, 'FP = ', 20.0)
('FN = ', 26.0, 'TN = ', 77.0)
('Threshold Value = ', -0.4272522354395466)
('TP = ', 107.0, 'FP = ', 49.999999999999993)
('FN = ', 4.0, 'TN = ', 47.000000000000007)
交叉验证给你一个稳定的性能估计,可以据此了解实际应用系统的性能。如果交叉验证给出的性能不够好,需要努力提升。例如,可以尝试使用基扩展(如“多变量回归:预测红酒口感”对应的基扩展)。也可以查看性能表现最差的样本,看能否发现问题,如数据预处理错误,如某个特征对错误的影响最大。如果发现的错误刚好解决了你的问题,那么就应该利用整个数据集来训练部署模型。我们将在下一节介绍该过程。
5.3.1 构建部署用的岩石水雷分类器
对于红酒品质预测案例,完成 alpha 选择后,下一步是在全部数据集上重新训练模型,学习最佳 alpha 对应的权重系数。最佳 alpha 是指能够最小化样本外错误的参数,本例通过交叉验证进行估计。代码清单 5-5 为完成该过程的代码。
代码清单 5-5 在岩石水雷数据上训练 ElasticNet 模型的系数曲线 - rocksVMinesCoef Curves.py
__author__ = 'mike_bowles'
import urllib2
from math import sqrt, fabs, exp
import matplotlib.pyplot as plot
from sklearn.linear_model import enet_pathsh
from sklearn.metrics import roc_auc_score, roc_curve
import numpy
#read data from uci data repository
target_url = ("https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data")
data = urllib2.urlopen(target_url)
#arrange data into list for labels and list of lists for attributes
xList = []
for line in data:
#split on comma
row = line.strip().split(",")
xList.append(row)
#separate labels from attributes, convert attributes from
#string to numeric and convert "M" to 1 and "R" to 0
xNum = []
labels = []
for row in xList:
lastCol = row.pop()
if lastCol == "M":
labels.append(1.0)
else:
labels.append(0.0)
attrRow = [float(elt) for elt in row]
xNum.append(attrRow)
#number of rows and columns in x matrix
nrow = len(xNum)
ncol = len(xNum[1])
alpha = 1.0
#calculate means and variances
xMeans = []
xSD = []
for i in range(ncol):
col = [xNum[j][i] for j in range(nrow)]
mean = sum(col)/nrow
xMeans.append(mean)
colDiff = [(xNum[j][i] - mean) for j in range(nrow)]
sumSq = sum([colDiff[i] * colDiff[i] for i in range(nrow)])
stdDev = sqrt(sumSq/nrow)
xSD.append(stdDev)
#use calculate mean and standard deviation to normalize xNum
xNormalized = []
for i in range(nrow):
rowNormalized = [(xNum[i][j] - xMeans[j])/xSD[j] \
for j in range(ncol)]
xNormalized.append(rowNormalized)
#normalize labels to center
meanLabel = sum(labels)/nrow
sdLabel = sqrt(sum([(labels[i] - meanLabel) * (labels[i] - meanLabel) \
for i in range(nrow)])/nrow)
labelNormalized = [(labels[i] - meanLabel)/sdLabel for i in range(nrow)]
#Convert normalized labels to numpy array
Y = numpy.array(labelNormalized)
#Convert normalized attributes to numpy array
X = numpy.array(xNormalized)
alphas, coefs, _ = enet_path(X, Y,l1_ratio=0.8, fit_intercept=False,
return_models=False)
plot.plot(alphas,coefs.T)
plot.xlabel('alpha')
plot.ylabel('Coefficients')
plot.axis('tight')
plot.semilogx()
ax = plot.gca()
ax.invert_xaxis()
plot.show()
nattr, nalpha = coefs.shape
#find coefficient ordering
nzList = []
for iAlpha in range(1,nalpha):
coefList = list(coefs[: ,iAlpha])
nzCoef = [index for index in range(nattr) if coefList[index] != 0.0]
for q in nzCoef:
if not(q in nzList):
nzList.append(q)
#make up names for columns of X
names = ['V' + str(i) for i in range(ncol)]
nameList = [names[nzList[i]] for i in range(len(nzList))]
print("Attributes Ordered by How Early They Enter the Model")
print(nameList)
print('')
#find coefficients corresponding to best alpha value. alpha value
corresponding to normalized X and normalized Y is 0.020334883589342503
alphaStar = 0.020334883589342503
indexLTalphaStar = [index for index in range(100) if \
alphas[index] > alphaStar]
indexStar = max(indexLTalphaStar)
#here's the set of coefficients to deploy
coefStar = list(coefs[:,indexStar])
print("Best Coefficient Values ")
print(coefStar)
print('')
#The coefficients on normalized attributes give another slightly
#different ordering
absCoef = [abs(a) for a in coefStar]
#sort by magnitude
coefSorted = sorted(absCoef, reverse=True)
idxCoefSize = [absCoef.index(a) for a in coefSorted if not(a == 0.0)]
namesList2 = [names[idxCoefSize[i]] for i in range(len(idxCoefSize))]
print("Attributes Ordered by Coef Size at Optimum alpha")
print(namesList2)
Printed Output: [filename - rocksVMinesCoefCurvesPrintedOutput.txt]
Attributes Ordered by How Early They Enter the Model
['V10', 'V48', 'V11', 'V44', 'V35', 'V51', 'V20', 'V3', 'V21', 'V45',
'V43', 'V15', 'V0', 'V22', 'V27', 'V50', 'V53', 'V30', 'V58', 'V56',
'V28', 'V39', 'V46', 'V19', 'V54', 'V29', 'V57', 'V6', 'V8', 'V7',
'V49', 'V2', 'V23', 'V37', 'V55', 'V4', 'V13', 'V36', 'V38', 'V26',
'V31', 'V1', 'V34', 'V33', 'V24', 'V16', 'V17', 'V5', 'V52', 'V41',
'V40', 'V59', 'V12', 'V9', 'V18', 'V14', 'V47', 'V42']
Best Coefficient Values
[0.082258256813766639, 0.0020619887220043702, -0.11828642590855878,
0.16633956932499627, 0.0042854388193718004, -0.0, -0.04366252474594004,
-0.07751510487942842, 0.10000054356323497, 0.0, 0.090617207036282038,
0.21210870399915693, -0.0, -0.010655386149821946, -0.0,
-0.13328659558143779, -0.0, 0.0, 0.0, 0.052814854501417867,
0.038531154796719078, 0.0035515348181877982, 0.090854714680378215,
0.030316113904025031, -0.0, 0.0, 0.0086195542357481014, 0.0, 0.0,
0.17497679257272536, -0.2215687804617206, 0.012614243827937584,
0.0, -0.0, 0.0, -0.17160601809439849, -0.080450013824209077,
0.078096790041518344, 0.022035287616766441, -0.072184409273692227,
0.0, -0.0, 0.0, 0.057018816876250704, 0.096478265685721556,
0.039917367637236176, 0.049158231541622875, 0.0, 0.22671917920123755,
-0.096272735479951091, 0.0, 0.078886784332226484, 0.0,
0.062312821755756878, -0.082785510713295471, 0.014466967172068596,
-0.074326527525632721, 0.068096475974257331,
0.070488864435477847, 0.0]
Attributes Ordered by Coef Size at Optimum alpha
['V48', 'V30', 'V11', 'V29', 'V35', 'V3', 'V15', 'V2', 'V8', 'V44',
'V49', 'V22', 'V10', 'V54', 'V0', 'V36', 'V51', 'V37', 'V7', 'V56',
'V39', 'V58', 'V57', 'V53', 'V43', 'V19', 'V46', 'V6', 'V45', 'V20',
'V23', 'V38', 'V55', 'V31', 'V13', 'V26', 'V4', 'V21', 'V1']
代码清单 5-5 的结构类似于代码清单 5-4,除了不包括交叉验证循环。alpha 的值是直接从代码清单 5-4 硬编码生成的,具体包括 2 个 alpha 值:一个是最小化误分类错误的alpha 值,一个是最大化 AUC 的 alpha 值。最大化 AUC 的 alpha 值稍大并且更加保守,更加保守是因为该 alpha 比最小化分类错误的 alpha 值更靠近左边。程序打印系数显示在代码的最下边。对于 60 个系数,约有 20 个系数值为 0。对于此运行(交叉验证),l1_ratio变量设为 0.8,这会比 l1_ratio 变量设为 1 的套索回归生成更多系数。
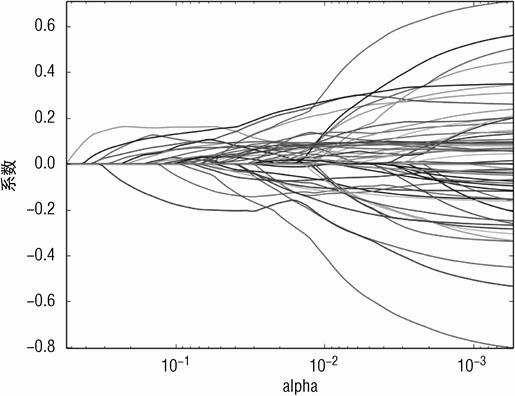
关于变量重要性的指标在代码的最后打印出来。衡量变量重要性的一个指标是随着alpha 减少,进入解的变量顺序。另一个指标是根据最优解的特征系数大小得到的排序。
正如红酒质量数据所讨论的,这些顺序只有当属性归一化以后才有意义。上述两种不同的变量顺序存在一定的一致性,但它们也并不完全相同。例如,变量 V48、V11、V35、V44 和 V3 在两个列表中的排名都很高,但是 V10 出现在第一个排序的开始,基于系数大小排序,V10 排名非常靠后。显然,当系数惩罚项很大时,算法只允许一个属性加入,此时 V10 很重要,但是当系数惩罚项收缩到所有属性被包含进来的对应点时,V10 属性的重要性就变得平稳,而且随着其他属性被添加进来,重要性也下降。
典型地,物体对与其同等波长级别的电磁波的反射能力最强。水雷(金属圆柱体)有长度和直径,和岩石比起来反射波波长可能较短也可能较长,性质表现更加不规则,反射的波长范围也更广。因为数据的所有属性值为正(代表功率级别),你可以预计低频波长的权重为正,高频波长的权重为负。你也可以发现这种差异如何会导致数据过拟合,即构建的模型在训练数据上表现良好,但泛化性能较差。交叉验证过程确保只要训练数据同实际部署数据类似,模型就不会过拟合。交叉验证错误与实际部署错误应该一致,即部署时的岩石 - 水雷数比例应该与训练数据中的比例一致。
图 5-10 为使用 ElasticNet 回归模型在完整的岩石水雷数据集上的系数曲线。曲线展示了模型复杂度以及属性的相对重要性的变化情况。
正如第 4 章提到的,另一种使用惩罚线性回归模型进行分类的方法是使用惩罚逻辑回归。代码清单 5-5 为使用惩罚逻辑回归来构建岩石水雷分类器的实现代码。代码以及结果展示了两种方法的相同和不同之处。算法差异可以从迭代的结果中发现。逻辑回归方法使用特征的线性函数来计算每个训练样本属于岩石还是水雷的概率或者似然(可以到 http://en.wikipedia.org/wiki/Logistic_regression 寻找更多关于逻辑回归的背景,以及相关的偏导计算)。不含惩罚项的逻辑回归算法称作迭代重加权最小二乘法(IRLS)。名字来源于算法的本质(参照 http://en.wikipedia.org/wiki/Iteratively_reweighted_least_squares)。算法利用训练样本的概率估计来计算权重。给定权重,问题变为加权的最小二乘法问题。该过程不断迭代直到概率收敛(对应权重不再改变)。
基本上,逻辑回归的 IRLS 算法相当于为第 4 章的惩罚线性回归算法(非逻辑回归)添加了另一层迭代。
将数据读入并归一化后,程序对权重及概率进行初始化,这些权重及概率是逻辑回归以及惩罚版本的逻辑回归的核心。这些概率及权重随着惩罚参数的减少同系数β一起计算,对于每次迭代,IRLS 字母被附加到一些变量名称上,目的是表明这些变量是和 IRLS 相关的变量。对概率估计的迭代通过循环进行,循环目的是降低 λ 以及对 β 的坐标下降进行封装。
逻辑回归的更新细节相较于普通的惩罚线性回归(非逻辑回归)更加复杂。复杂性一方面体现在 IRLS 中权重的相关计算,每来一个样本,权重及概率计算一遍。代码使用变量w 和 p 来代表权重和概率。算法也需要收集权重(weights)对于乘积和(Sum of products)的效果,典型乘积包括属性乘以残差以及属性值平方。上述乘积和在代码里使用 sum Wxx变量来定义,具体地,sum Wxx 是一个 list 对象,每个元素为权重乘以对应属性值平方。复杂性的另一方面体现在残差是标签、概率以及属性值以及相关系数(β)的函数。
代码生成了变量重要性顺序及系数曲线,目的是与使用非逻辑回归生成的变量顺序及曲线进行比较。逻辑转换使得直接进行系数比较存在问题,因为逻辑函数对应非线性变化。普通线性回归以及逻辑回归都会生成一个系数向量,然后乘以属性值,最后和阈值比较。阈值设置相对次要,因为它可以在训练完成后来确定。所以 β 的整体尺度和各个特征值的相对大小比较并不重要。一种判断相对大小的方法是查看两种方法引入新变量的顺序。通过比较代码清单 5-5 和代码清单 5-4 的打印结果,两种方法对排序最高的前 8 个属性的判断是一致的。
对于接下来的 8 个变量,有 7 个变量同时出现在两个列表中,尽管也有很小的区别。接下来的 8 个变量也几乎相同。这说明两种方法对属性重要性顺序的判断非常一致。
另一个问题是哪种方法性能更好,回答这个问题需要对惩罚逻辑回归运行交叉验证,好在你已经有相关的工具及代码来开展工作。代码清单 5-6 没有从速度角度进行优化,但在岩石水雷问题上运行应该不会花费太多时间。
代码清单 5-6 在岩石水雷数据上训练惩罚逻辑回归模型 - rocksVMinesGlmnet.py
__author__ = 'mike_bowles'
import urllib2
import sys
from math import sqrt, fabs, exp
import matplotlib.pyplot as plot
def S(z,gamma):
if gamma >= fabs(z):
return 0.0
if z > 0.0:
return z - gamma
else:
return z + gamma
def Pr(b0,b,x):
n = len(x)
sum = b0
for i in range(n):
sum += b[i]*x[i]
if sum < -100: sum = -100
return 1.0/(1.0 + exp(-sum))
#read data from uci data repository
target_url = ("https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data")
data = urllib2.urlopen(target_url)
#arrange data into list for labels and list of lists for attributes
xList = []
for line in data:
#split on comma
row = line.strip().split(",")
xList.append(row)
#separate labels from attributes, convert from attributes from string
#to numeric and convert "M" to 1 and "R" to 0
xNum = []
labels = []
for row in xList:
lastCol = row.pop()
if lastCol == "M":
labels.append(1.0)
else:
labels.append(0.0)
attrRow = [float(elt) for elt in row]
xNum.append(attrRow)
#number of rows and columns in x matrix
nrow = len(xNum)
ncol = len(xNum[1])
alpha = 0.8
#calculate means and variances
xMeans = []
xSD = []
for i in range(ncol):
col = [xNum[j][i] for j in range(nrow)]
mean = sum(col)/nrow
xMeans.append(mean)
colDiff = [(xNum[j][i] - mean) for j in range(nrow)]
sumSq = sum([colDiff[i] * colDiff[i] for i in range(nrow)])
stdDev = sqrt(sumSq/nrow)
xSD.append(stdDev)
#use calculate mean and standard deviation to normalize xNum
xNormalized = []
for i in range(nrow):
rowNormalized = [(xNum[i][j] - xMeans[j])/xSD[j] \
for j in range(ncol)]
xNormalized.append(rowNormalized)
#Do Not Normalize labels but do calculate averages
meanLabel = sum(labels)/nrow
sdLabel = sqrt(sum([(labels[i] - meanLabel) * (labels[i] - meanLabel) \
for i in range(nrow)])/nrow)
#initialize probabilities and weights
sumWxr = [0.0] * ncol
sumWxx = [0.0] * ncol
sumWr = 0.0
sumW = 0.0
#calculate starting points for betas
for iRow in range(nrow):
p = meanLabel
w = p * (1.0 - p)
#residual for logistic
r = (labels[iRow] - p) / w
x = xNormalized[iRow]
sumWxr = [sumWxr[i] + w * x[i] * r for i in range(ncol)]
sumWxx = [sumWxx[i] + w * x[i] * x[i] for i in range(ncol)]
sumWr = sumWr + w * r
sumW = sumW + w
avgWxr = [sumWxr[i]/nrow for i in range(ncol)]
avgWxx = [sumWxx[i]/nrow for i in range(ncol)]
maxWxr = 0.0
for i in range(ncol):
val = abs(avgWxr[i])
if val > maxWxr:
maxWxr = val
#calculate starting value for lambda
lam = maxWxr/alpha
#this value of lambda corresponds to beta = list of 0's
#initialize a vector of coefficients beta
beta = [0.0] * ncol
beta0 = sumWr/sumW
#initialize matrix of betas at each step
betaMat = []
betaMat.append(list(beta))
beta0List = []
beta0List.append(beta0)
#begin iteration
nSteps = 100
lamMult = 0.93 #100 steps gives reduction by factor of 1000 in lambda
#(recommended by authors)
nzList = []
for iStep in range(nSteps):
#decrease lambda
lam = lam * lamMult
#Use incremental change in betas to control inner iteration
#set middle loop values for betas = to outer values
#values are used for calculating weights and probabilities
#inner values are used for calculating penalized regression updates
#take pass through data to calculate averages over data required
#for iteration
#initilize accumulators
betaIRLS = list(beta)
beta0IRLS = beta0
distIRLS = 100.0
#Middle loop to calculate new betas with fixed IRLS weights and
#probabilities
iterIRLS = 0
while distIRLS > 0.01:
iterIRLS += 1
iterInner = 0.0
betaInner = list(betaIRLS)
beta0Inner = beta0IRLS
distInner = 100.0
while distInner > 0.01:
iterInner += 1
if iterInner > 100: break
#cycle through attributes and update one-at-a-time
#record starting value for comparison
betaStart = list(betaInner)
for iCol in range(ncol):
sumWxr = 0.0
sumWxx = 0.0
sumWr = 0.0
sumW = 0.0
for iRow in range(nrow):
x = list(xNormalized[iRow])
y = labels[iRow]
p = Pr(beta0IRLS, betaIRLS, x)
if abs(p) < 1e-5:
p = 0.0
w = 1e-5
elif abs(1.0 - p) < 1e-5:
p = 1.0
w = 1e-5
else:
w = p * (1.0 - p)
z = (y - p) / w + beta0IRLS + sum([x[i] *
betaIRLS[i] for i in range(ncol)])
r = z - beta0Inner - sum([x[i] * betaInner[i]
for i in range(ncol)])
sumWxr += w * x[iCol] * r
sumWxx += w * x[iCol] * x[iCol]
sumWr += w * r
sumW += w
avgWxr = sumWxr / nrow
avgWxx = sumWxx / nrow
beta0Inner = beta0Inner + sumWr / sumW
uncBeta = avgWxr + avgWxx * betaInner[iCol]
betaInner[iCol] = S(uncBeta, lam * alpha) / (avgWxx +
lam * (1.0 - alpha))
sumDiff = sum([abs(betaInner[n] - betaStart[n]) \
for n in range(ncol)])
sumBeta = sum([abs(betaInner[n]) for n in range(ncol)])
distInner = sumDiff/sumBeta
#print number of steps for inner and middle loop convergence
#to monitor behavior
#print(iStep, iterIRLS, iterInner)
#if exit inner while loop, then set betaMiddle = betaMiddle
#and run through middle loop again.
#Check change in betaMiddle to see if IRLS is converged
a = sum([abs(betaIRLS[i] - betaInner[i]) for i in range(ncol)])
b = sum([abs(betaIRLS[i]) for i in range(ncol)])
distIRLS = a / (b + 0.0001)
dBeta = [betaInner[i] - betaIRLS[i] for i in range(ncol)]
gradStep = 1.0
temp = [betaIRLS[i] + gradStep * dBeta[i] for i in range(ncol)]
betaIRLS = list(temp)
beta = list(betaIRLS)
beta0 = beta0IRLS
betaMat.append(list(beta))
beta0List.append(beta0)
nzBeta = [index for index in range(ncol) if beta[index] != 0.0]
for q in nzBeta:
if not(q in nzList):
nzList.append(q)
#make up names for columns of xNum
names = ['V' + str(i) for i in range(ncol)]
nameList = [names[nzList[i]] for i in range(len(nzList))]
print("Attributes Ordered by How Early They Enter the Model")
print(nameList)
for i in range(ncol):
#plot range of beta values for each attribute
coefCurve = [betaMat[k][i] for k in range(nSteps)]
xaxis = range(nSteps)
plot.plot(xaxis, coefCurve)
plot.xlabel("Steps Taken")
plot.ylabel("Coefficient Values")
plot.show()
Printed Output: [filename - rocksVMinesGlmnetPrintedOutput.txt]
Attributes Ordered by How Early They Enter the Model
['V10', 'V48', 'V11', 'V44', 'V35', 'V51', 'V20', 'V3', 'V50', 'V21',
'V43', 'V47', 'V15', 'V27', 'V0', 'V22', 'V36', 'V30', 'V53', 'V56',
'V58', 'V6', 'V19', 'V28', 'V39', 'V49', 'V7', 'V23', 'V54', 'V8',
'V14', 'V2', 'V29', 'V38', 'V57', 'V45', 'V13', 'V32', 'V31', 'V42',
'V16', 'V37', 'V59', 'V52', 'V25', 'V18', 'V1', 'V33', 'V4', 'V55',
'V17', 'V46', 'V26', 'V12', 'V40', 'V34', 'V5', 'V24', 'V41', 'V9']
图 5-11 展示了使用惩罚逻辑回归的岩石水雷系数曲线。正如所标记的,系数尺度与普通惩罚线性回归尺度不同,因为两种方法使用的逻辑函数不同。普通回归尝试为目标 0和 1 拟合一条直线,逻辑回归通过拟合一条“对数奇数比”的直线来预测类别成员的概率。
假设 p 是样本属于水雷类别的概率,然后奇数比等于 p/1 – p。对数奇数比是奇数比的自然对数。只要 p 的范围是 0 ~ 1,对数奇数比的范围就是 −∞~∞。对数奇数比非常大并且为正表明预测样本属于水雷类的结论非常确定。负的较大的数值对应于岩石类别。
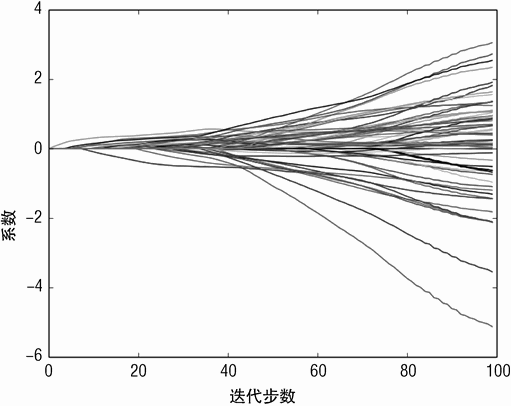
因为两种方法的预测差异非常大,所以生成的预测尺度不同,对应属性的系数也不同。
但正如两种程序打印输出所表现的,变量出现在解的顺序非常类似,这可以通过系数曲线中出现的前几个属性印证得到。





本书评论