5.2 多变量回归:预测红酒口感
正如第 2 章所讨论的,红酒口感数据集来源于 UC Irvine 数据仓库(http://archive.ics.uci.edu/ml/datasets/Wine+Quality])数据集包含 1599 种红酒的化学分析以及每种红酒的平均口感得分(通过多人品尝)。预测问题是给定化学成分来预测口感。化学成分数据包含 11 种不同的化学属性值:酒精内容、pH 以及柠檬酸等,可以到第 2 章或者UC Irvine 的网站去了解该数据集的更多细节。
预测红酒口感是一个回归问题,因为问题目标是预测质量得分,质量得分为 0 ~ 10的整数。数据集只包括得分为 3 ~ 8 的样例。因为只给出了整数得分,所以理论上也可以将该问题转换为多分类问题,即该问题包含 6 种可能的类别(整数 3 ~ 8)。
但是作为分类问题会忽略不同得分之间存在的顺序关系(如 5 比 6 差,但比 4 好),所以回归是一个更自然的解决方法,因为它的预测很好地保留了顺序关系。
定义问题的另一种方式是从错误指标出发,这些指标关联到回归问题或者是多分类问题。回归的错误函数是均方误差。当实际的口感得分为 3 时,预测值为 5 要比预测值为 4对累积错误的贡献更大。多分类问题的错误指标是被误分的样本数目。使用该错误指标,如果实际的口感为 3,预测 5 或者 4 对于预测错误的贡献相同。回归显得更加自然,但是没有更好的办法证明它的性能更优。唯一能确定哪种方法效果更好的方式是两种都尝试一下。在“多类别分类:分类犯罪场景下的玻璃样本”,会学习如何处理多类问题。接着可以再回来尝试多分类方法,看看使用分类,效果会变好还是变差。实际你会用哪种错误指标?
5.2.1 构建并测试模型以预测红酒口感
构建模型的第一步是通过样本外的性能来判断模型能否满足性能要求。代码清单 5-1展示了执行 10 折交叉验证的效果并绘制了图形。代码的第 1 节从 UCI 网站读入数据,转化为列表的列表,然后对属性以及标签进行归一化。接着将列表转换为 numpy 数组X(属性矩阵)以及数组 Y(标签向量)。回归存在 2 个版本的定义。其中一个版本使用归一化的数值,另一个版本使用非归一化的数值。不论哪种定义,都可以将对应的非归一化版本注释掉,重新运行代码看对属性或者标签进行归一化的实际效果。使用一行代码定义交叉验证的数据份数(10),并且对模型进行了训练。然后程序在 10 份数据的每一份上绘制错误随 α 变化的曲线,同时绘制在 10 份数据上的错误平均值。
图 5-1 ~图 5-3 为使用不同归一化版本的预测效果,这 3 个例子对应的归一化情况如下。
(1)X 做归一,Y 不做归一。
(2)X 和 Y 都做归一。
(3)X 和 Y 都不做归一。
代码清单 5-1 在红酒口感数据集上,使用交叉验证来估计套索模型的样本外错误
__author__ = 'mike-bowles'
import urllib2
import numpy
from sklearn import datasets, linear_model
from sklearn.linear_model import LassoCV
from math import sqrt
import matplotlib.pyplot as plot
#read data into iterable
target_url = ("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv")
data = urllib2.urlopen(target_url)
xList = []
labels = []
names = []
firstLine = True
for line in data:
if firstLine:
names = line.strip().split(";")
firstLine = False
else:
#split on semi-colon
row = line.strip().split(";")
#put labels in separate array
labels.append(float(row[-1]))
#remove label from row
row.pop()
#convert row to floats
floatRow = [float(num) for num in row]
xList.append(floatRow)
#Normalize columns in x and labels
#Note: be careful about normalization. Some penalized
#regression packages include it and some don't.
nrows = len(xList)
ncols = len(xList[0])
#calculate means and variances
xMeans = []
xSD = []
for i in range(ncols):
col = [xList[j][i] for j in range(nrows)]
mean = sum(col)/nrows
xMeans.append(mean)
colDiff = [(xList[j][i] - mean) for j in range(nrows)]
sumSq = sum([colDiff[i] * colDiff[i] for i in range(nrows)])
stdDev = sqrt(sumSq/nrows)
xSD.append(stdDev)
#use calculate mean and standard deviation to normalize xList
xNormalized = []
for i in range(nrows):
rowNormalized = [(xList[i][j] - xMeans[j])/xSD[j] \
for j in range(ncols)]
xNormalized.append(rowNormalized)
#Normalize labels
meanLabel = sum(labels)/nrows
sdLabel = sqrt(sum([(labels[i] - meanLabel) * (labels[i] -
meanLabel) for i in range(nrows)])/nrows)
labelNormalized = [(labels[i] - meanLabel)/sdLabel \
for i in range(nrows)]
#Convert list of list to np array for input to sklearn packages
#Unnormalized labels
Y = numpy.array(labels)
#normalized lables
Y = numpy.array(labelNormalized)
#Unnormalized X's
X = numpy.array(xList)
#Normalized Xss
X = numpy.array(xNormalized)
#Call LassoCV from sklearn.linear_model
wineModel = LassoCV(cv=10).fit(X, Y)
# Display results
plot.figure()
plot.plot(wineModel.alphas_, wineModel.mse_path_, ':')
plot.plot(wineModel.alphas_, wineModel.mse_path_.mean(axis=-1),
label='Average MSE Across Folds', linewidth=2)
plot.axvline(wineModel.alpha_, linestyle='--',
label='CV Estimate of Best alpha')
plot.semilogx()
plot.legend()
ax = plot.gca()
ax.invert_xaxis()
plot.xlabel('alpha')
plot.ylabel('Mean Square Error')
plot.axis('tight')
plot.show()
#print out the value of alpha that minimizes the Cv-error
print("alpha Value that Minimizes CV Error ",wineModel.alpha_)
print("Minimum MSE ", min(wineModel.mse_path_.mean(axis=-1)))
Printed Output: Normalized X, Un-normalized Y
('alpha Value that Minimizes CV Error ', 0.010948337166040082)
('Minimum MSE ', 0.433801987153697)
Printed Output: Normalized X and Y
('alpha Value that Minimizes CV Error ', 0.013561387700964642)
('Minimum MSE ', 0.66558492060028562)
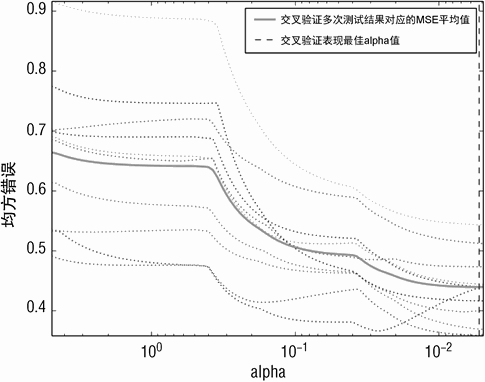
Printed Output: Un-normalized X and Y
('alpha Value that Minimizes CV Error ', 0.0052692947038249062)
('Minimum MSE ', 0.43936035436777832)
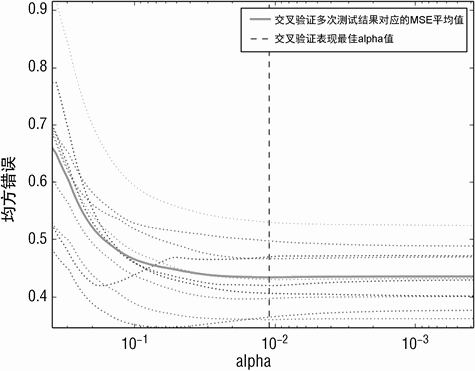
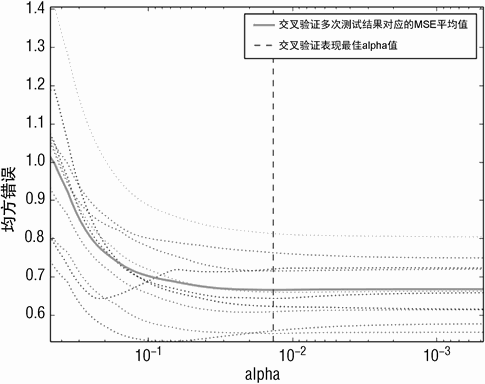
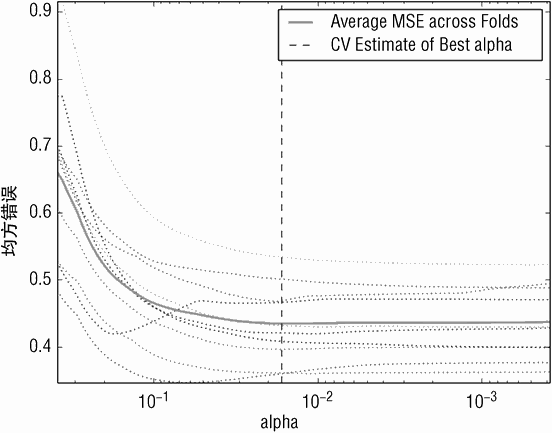
代码清单 5-1 最下边的输出展示了使用归一化 Y 带来的 MSE 的显著增长。相比之下,图 5-1 以及图 5-2 形状类似。它们之间的唯一差别是 Y 轴的数据尺度。参照代码清单 2-13 可以看到非归一化的红酒质量得分的标准偏差为 0.81。这意味着归一化到标准偏差 1.0 需要大概乘以 1.2。这会导致 MSE 增长 1.22 倍。对标签进行归一化会使 MSE 失去与原始数据的关联。抽取 MSE 平方根并转换回标签原始尺度,这些实现都是现成的。在本例中,MSE(基于归一化的 Y)为 0.433。平方根约为 0.64。
这意味着 +/-sigma 的错误大约在 1.3 倍个单位口感得分范围内。所以,Y 做归一化并不会对结果有本质差异。X 做归一化的效果如何? X 做归一化是会提高,还是降低性能呢?
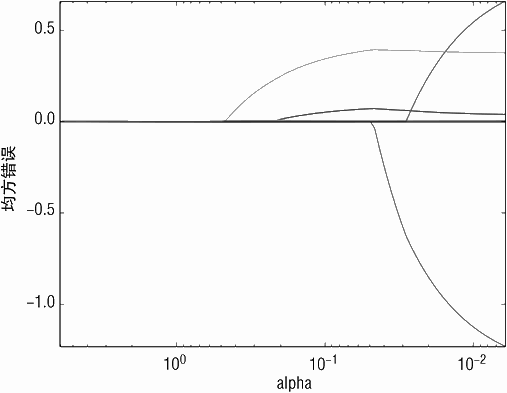
代码清单 5-1 中的数字集合展示了 X 不做归一化导致 MSE 轻微增长。然而在图 5-3 中,CV 错误随 alpha 的变化关系与图 5-1 和图 5-2 相比存在显著差异。图上的扇形变化是由 X特征尺度混乱(未做归一化)导致,算法挑选了尺度大的变量进行预测,对应的系数很小。
这种情况发生的条件是如果变量与 Y 的关联很大,或者变量与 Y 关联很小,但是特征尺度很大。算法使用一个较差的变量进行若干次迭代,直到 α(之前用 λ 代替)变得足够小以引入一个更好的变量,这时错误才会陡然下降。这个例子的教训就是需要对 X 做归一化,X 不做归一化一定要足够警惕。
5.2.2 部署前在整个数据集上进行训练
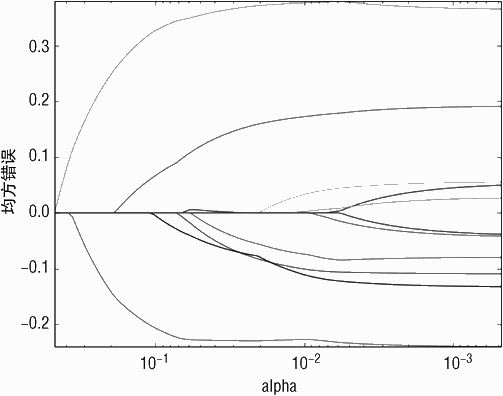
代码清单 5-2 为在整个数据集上进行训练的代码。正如之前提到的,在整个数据集上进行训练是为了获得部署使用的最佳权重系数。交叉验证可以对模型性能进行评估,同时获得性能最好的 α 参数值。将数据从 UC Irvine 数据仓库读入并且归一化后,程序将数据转换为 numpy array 类型,然后调用 lasso_path 方法来生成 α 值(即惩罚项权重)以及对应的特征系数。系数的变化轨迹如图 5-4 所示。
代码清单 5-2 在完整数据集上训练套索模型 -wineLassoCoefCurves.py
__author__ = 'mike-bowles'
import urllib2
import numpy
from sklearn import datasets, linear_model
from sklearn.linear_model import LassoCV
from math import sqrt
import matplotlib.pyplot as plot
#read data into iterable
target_url = "http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
data = urllib2.urlopen(target_url)
xList = []
labels = []
names = []
firstLine = True
for line in data:
if firstLine:
names = line.strip().split(";")
firstLine = False
else:
#split on semi-colon
row = line.strip().split(";")
#put labels in separate array
labels.append(float(row[-1]))
#remove label from row
row.pop()
#convert row to floats
floatRow = [float(num) for num in row]
xList.append(floatRow)
#Normalize columns in x and labels
#Note: be careful about normalization. Some penalized regression
#packages include it and some don't.
nrows = len(xList)
ncols = len(xList[0])
#calculate means and variances
xMeans = []
xSD = []
for i in range(ncols):
col = [xList[j][i] for j in range(nrows)]
mean = sum(col)/nrows
xMeans.append(mean)
colDiff = [(xList[j][i] - mean) for j in range(nrows)]
sumSq = sum([colDiff[i] * colDiff[i] for i in range(nrows)])
stdDev = sqrt(sumSq/nrows)
xSD.append(stdDev)
#use calculate mean and standard deviation to normalize xList
xNormalized = []
for i in range(nrows):
rowNormalized = [(xList[i][j] - xMeans[j])/xSD[j] for j in
range(ncols)]
xNormalized.append(rowNormalized)
#Normalize labels
meanLabel = sum(labels)/nrows
sdLabel = sqrt(sum([(labels[i] - meanLabel) * (labels[i] - meanLabel)
for i in range(nrows)])/nrows)
labelNormalized = [(labels[i] - meanLabel)/sdLabel for i in
range(nrows)]
#Convert list of list to np array for input to sklearn packages
#Unnormalized labels
Y = numpy.array(labels)
#normalized lables
Y = numpy.array(labelNormalized)
#Unnormalized X's
X = numpy.array(xList)
#Normalized Xss
X = numpy.array(xNormalized)
alphas, coefs, _ = linear_model.lasso_path(X, Y, return_models=False)
plot.plot(alphas,coefs.T)
plot.xlabel('alpha')
plot.ylabel('Coefficients')
plot.axis('tight')
plot.semilogx()
ax = plot.gca()
ax.invert_xaxis()
plot.show()
nattr, nalpha = coefs.shape
#find coefficient ordering
nzList = []
for iAlpha in range(1,nalpha):
coefList = list(coefs[: ,iAlpha])
nzCoef = [index for index in range(nattr) if coefList[index] != 0.0]
for q in nzCoef:
if not(q in nzList):
nzList.append(q)
nameList = [names[nzList[i]] for i in range(len(nzList))]
print("Attributes Ordered by How Early They Enter the Model", nameList)
#find coefficients corresponding to best alpha value. alpha value
# corresponding to normalized X and normalized Y is 0.013561387700964642
alphaStar = 0.013561387700964642
indexLTalphaStar = [index for index in range(100) if alphas[index] >
alphaStar]
indexStar = max(indexLTalphaStar)
#here's the set of coefficients to deploy
coefStar = list(coefs[:,indexStar])
print("Best Coefficient Values ", coefStar)
#The coefficients on normalized attributes give another slightly
#different ordering
absCoef = [abs(a) for a in coefStar]
#sort by magnitude
coefSorted = sorted(absCoef, reverse=True)
idxCoefSize = [absCoef.index(a) for a in coefSorted if not(a == 0.0)]
namesList2 = [names[idxCoefSize[i]] for i in range(len(idxCoefSize))]
print("Attributes Ordered by Coef Size at Optimum alpha", namesList2)
Printed Output w. Normalized X:
('Attributes Ordered by How Early They Enter the Model',
['"alcohol"', '"volatile acidity"', '"sulphates"',
'"total sulfur dioxide"', '"chlorides"', '"fixed acidity"', '"pH"',
'"free sulfur dioxide"', '"residual sugar"', '"citric acid"',
'"density"'])
('Best Coefficient Values ',
[0.0, -0.22773815784738916, -0.0, 0.0, -0.094239023363375404,
0.022151948563542922, -0.099036391332770576, -0.0,
-0.067873612822590218, 0.16804102141830754, 0.37509573430881538])
('Attributes Ordered by Coef Size at Optimum alpha',
['"alcohol"', '"volatile acidity"', '"sulphates"',
'"total sulfur dioxide"', '"chlorides"', '"pH"',
'"free sulfur dioxide"'])
Printed Output w. Un-normalized X:
('Attributes Ordered by How Early They Enter the Model',
['"total sulfur dioxide"', '"free sulfur dioxide"', '"alcohol"',
'"fixed acidity"', '"volatile acidity"', '"sulphates"'])
('Best Coefficient Values ', [0.044339055570034182, -1.0154179864549988,
0.0, 0.0, -0.0, 0.0064112885435006822, -0.0038622920281433199, -0.0,
-0.0, 0.41982634135945091, 0.37812720947996975])
('Attributes Ordered by Coef Size at Optimum alpha',
['"volatile acidity"', '"sulphates"', '"alcohol"', '"fixed acidity"',
'"free sulfur dioxide"', '"total sulfur dioxide"'])
上述程序对 α 值进行硬编码,使用交叉验证中效果最好的 α 值。代码使用的版本是基于归一化属性以及标签的最佳 alpha 值。如果属性取非归一化的值,对应的最佳的 α 值也会改变。Y 不做归一化,α 值会乘以 1.2,因为归一化后的 Y 的偏差为 1.0(参照之前讨论的标签归一化以及不归一化对 MSE 差异的影响)。使用硬编码的 α 值来计算对应于最佳交叉验证结果的系数向量。
代码清单 5-2 展示了 3 种设置的输出:基于归一化属性以及非归一化的标签、全部归一化、全部非归一化。每种设置的打印输出包含一列属性,这些属性是随 α 降低,逐步挑选出来加入模型中的属性(Python 包中的 α 值对应于第 4 章中的惩罚项 λ)。打印输出展示了对应于硬编码的 α 值的特征系数。打印输出的第三个元素是根据系数大小得到的属性排序(使用指定的 α 值)。属性系数取值是另一种反映属性重要性的方式,这种排序只有当属性归一化后才有意义。注意到使用归一化属性,前面讨论的为属性重要性赋值的2 种方法生成的属性顺序基本一致,在不太重要的属性上可能存在一些差异。如果使用非归一化的属性,则得到的结果离正确值差之甚远。
正如前面提到的,变量进入解的顺序(随着 α 减少)受属性是否归一化影响较大。如果一个变量没有被归一化,属性的数值量级而不是属性的内在价值会决定属性的使用情况。通过比较基于归一化属性的变量顺序与非归一化属性的变量顺序可以很明显地发现这个问题。
图 5-4 和图 5-5 分别为基于归一化属性以及非归一化属性,套索模型的系数曲线。基于非归一化属性的系数曲线相较于归一化属性的系数曲线更加无序。几个早期进入解的系数相对于后续进入解的系数更接近于 0。这种现象正好证明了系数进入模型的顺序与最佳解的系数尺度的顺序存在本质不同。
5.2.3 基扩展:基于原始属性扩展新属性来改进性能
第 4 章讨论了在原始属性通过函数来扩展新属性。这么做的目的是提高性能。代码清单 5-3 展示了如何添加 2 个新属性到红酒数据上。
代码清单 5-3 使用样本外错误来评估新属性对红酒品质的预测效果 -wineExpaned LassoCV.py
__author__ = 'mike-bowles'
import urllib2
import numpy
from sklearn import datasets, linear_model
from sklearn.linear_model import LassoCV
from math import sqrt
import matplotlib.pyplot as plot
#read data into iterable
target_url = ("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv")
data = urllib2.urlopen(target_url)
xList = []
labels = []
names = []
firstLine = True
for line in data:
if firstLine:
names = line.strip().split(";")
firstLine = False
else:
#split on semi-colon
row = line.strip().split(";")
#put labels in separate array
labels.append(float(row[-1]))
#remove label from row
row.pop()
#convert row to floats
floatRow = [float(num) for num in row]
xList.append(floatRow)
#append square of last term (alcohol)
for i in range(len(xList)):
alcElt = xList[i][-1]
volAcid = xList[i][1]
temp = list(xList[i])
temp.append(alcElt*alcElt)
temp.append(alcElt*volAcid)
xList[i] = list(temp)
#add new name to variable list
names[-1] = "alco^2"
names.append("alco*volAcid")
#Normalize columns in x and labels
#Note: be careful about normalization. Some penalized regression
packages include it and some don't.
nrows = len(xList)
ncols = len(xList[0])
#calculate means and variances
xMeans = []
xSD = []
for i in range(ncols):
col = [xList[j][i] for j in range(nrows)]
mean = sum(col)/nrows
xMeans.append(mean)
colDiff = [(xList[j][i] - mean) for j in range(nrows)]
sumSq = sum([colDiff[i] * colDiff[i] for i in range(nrows)])
stdDev = sqrt(sumSq/nrows)
xSD.append(stdDev)
#use calculate mean and standard deviation to normalize xList
xNormalized = []
for i in range(nrows):
rowNormalized = [(xList[i][j] - xMeans[j])/xSD[j] \
for j in range(ncols)]
xNormalized.append(rowNormalized)
#Normalize labels
meanLabel = sum(labels)/nrows
sdLabel = sqrt(sum([(labels[i] - meanLabel) * (labels[i] - meanLabel) \
for i in range(nrows)])/nrows)
labelNormalized = [(labels[i] - meanLabel)/sdLabel \
for i in range(nrows)]
#Convert list of list to np array for input to sklearn packages
#Unnormalized labels
Y = numpy.array(labels)
#normalized labels
#Y = numpy.array(labelNormalized)
#Unnormalized X's
X = numpy.array(xList)
#Normalized Xss
X = numpy.array(xNormalized)
#Call LassoCV from sklearn.linear_model
wineModel = LassoCV(cv=10).fit(X, Y)
# Display results
plot.figure()
plot.plot(wineModel.alphas_, wineModel.mse_path_, ':')
plot.plot(wineModel.alphas_, wineModel.mse_path_.mean(axis=-1),
label='Average MSE Across Folds', linewidth=2)
plot.axvline(wineModel.alpha_, linestyle='--',
label='CV Estimate of Best alpha')
plot.semilogx()
plot.legend()
ax = plot.gca()
ax.invert_xaxis()
plot.xlabel('alpha')
plot.ylabel('Mean Square Error')
plot.axis('tight')
plot.show()
#print out the value of alpha that minimizes the CV-error
print("alpha Value that Minimizes CV Error ",wineModel.alpha_)
print("Minimum MSE ", min(wineModel.mse_path_.mean(axis=-1)))
Printed Output: [filename - wineLassoExpandedCVPrintedOutput.txt]
('alpha Value that Minimizes CV Error ', 0.016640498998569835)
('Minimum MSE ', 0.43452874043020256)
属性读入后的关键步骤是将属性值转换为浮点数值。前面的很多行代码都是用于读入属性行,将其中的酒精以及挥发酸属性值读出来,然后添加酒精的平方以及酒精乘以挥发酸这两个新属性,这么做是因为这些属性对于解非常重要。为了进一步提高性能有可能需要对重要变量进行多次组合,进行多次尝试。
结果显示添加这些新变量会轻微降低性能。有时稍作尝试就可能发现部分变量会导致完全不同的结果。对于本例,可以通过系数曲线来观察新的变量能否取代最优值对应的原始变量。这些信息可以帮助移除原始变量,使用新创建的变量。
图 5-6 为基于扩展属性集生成的交叉验证的错误曲线。新的交叉验证曲线与基于原始特征的交叉验证曲线并没有本质区别。
本节介绍了在包含实数输出的问题上(回归问题)应用惩罚回归方法的过程。下一节将介绍输出为二值情况下的惩罚线性回归方法。代码类似于本节所看到的,其中一些技术(如基扩展)可以用在分类问题上,主要差别在于对性能的度量计算不同。





本书评论