5.4 多类别分类 - 分类犯罪现场的玻璃样本
上一节看到的岩石水雷问题称作 2 分类问题,即预测只能取两种可能值中的 1 种(即返回的声纳是来自于岩石,还是水雷的反射?)如果预测标签不止两个值,那么问题称作多类别分类问题。本节使用惩罚线性回归来解决玻璃样本分类问题,正如第2章讨论的,玻璃样本包含 9个物理化学指标(基于其化学组成的折射率)、6 种类型玻璃,共 214 个样本。问题是使用物理化学指标来确定给定样本属于 6 种类型的哪一种。实际应用于犯罪或者车祸现场的法医分析。数据来源于 UCI 数据集,相关页面提供了一篇使用支持向量机求解问题的论文。在阅读完解决该问题的代码后,本节将对惩罚线性回归方法以及支持向量机的方法进行性能比较。
代码清单 5-7 为解决该问题的代码。
代码清单 5-7 使用惩罚线性回归的多类别分类 - 分类犯罪现场的玻璃样本 - glass ENetRegCV.py
import urllib2
from math import sqrt, fabs, exp
import matplotlib.pyplot as plot
from sklearn.linear_model import enet_path
from sklearn.metrics import roc_auc_score, roc_curve
import numpy
target_url = ("https://archive.ics.uci.edu/ml/machine-learning-databases/glass/glass.data")
data = urllib2.urlopen(target_url)
#arrange data into list for labels and list of lists for attributes
xList = []
for line in data:
#split on comma
row = line.strip().split(",")
xList.append(row)
names = ['RI', 'Na', 'Mg', 'Al', 'Si', 'K', 'Ca', 'Ba', 'Fe', 'Type']
#Separate attributes and labels
xNum = []
labels = []
for row in xList:
labels.append(row.pop())
l = len(row)
#eliminate ID
attrRow = [float(row[i]) for i in range(1, l)]
xNum.append(attrRow)
#number of rows and columns in x matrix
nrow = len(xNum)
ncol = len(xNum[1])
#create one versus all label vectors
#get distinct glass types and assign index to each
yOneVAll = []
labelSet = set(labels)
labelList = list(labelSet)
labelList.sort()
nlabels = len(labelList)
for i in range(nrow):
yRow = [0.0]*nlabels
index = labelList.index(labels[i])
yRow[index] = 1.0
yOneVAll.append(yRow)
#calculate means and variances
xMeans = []
xSD = []
for i in range(ncol):
col = [xNum[j][i] for j in range(nrow)]
mean = sum(col)/nrow
xMeans.append(mean)
colDiff = [(xNum[j][i] - mean) for j in range(nrow)]
sumSq = sum([colDiff[i] * colDiff[i] for i in range(nrow)])
stdDev = sqrt(sumSq/nrow)
xSD.append(stdDev)
#use calculate mean and standard deviation to normalize xNum
xNormalized = []
for i in range(nrow):
rowNormalized = [(xNum[i][j] - xMeans[j])/xSD[j] \
for j in range(ncol)]
xNormalized.append(rowNormalized)
#normalize y's to center
yMeans = []
ySD = []
for i in range(nlabels):
col = [yOneVAll[j][i] for j in range(nrow)]
mean = sum(col)/nrow
yMeans.append(mean)
colDiff = [(yOneVAll[j][i] - mean) for j in range(nrow)]
sumSq = sum([colDiff[i] * colDiff[i] for i in range(nrow)])
stdDev = sqrt(sumSq/nrow)
ySD.append(stdDev)
yNormalized = []
for i in range(nrow):
rowNormalized = [(yOneVAll[i][j] - yMeans[j])/ySD[j] \
for j in range(nlabels)]
yNormalized.append(rowNormalized)
#number of cross-validation folds
nxval = 10
nAlphas=200
misClass = [0.0] * nAlphas
for ixval in range(nxval):
#Define test and training index sets
idxTest = [a for a in range(nrow) if a%nxval == ixval%nxval]
idxTrain = [a for a in range(nrow) if a%nxval != ixval%nxval]
#Define test and training attribute and label sets
xTrain = numpy.array([xNormalized[r] for r in idxTrain])
xTest = numpy.array([xNormalized[r] for r in idxTest])
yTrain = [yNormalized[r] for r in idxTrain]
yTest = [yNormalized[r] for r in idxTest]
labelsTest = [labels[r] for r in idxTest]
#build model for each column in yTrain
models = []
lenTrain = len(yTrain)
lenTest = nrow - lenTrain
for iModel in range(nlabels):
yTemp = numpy.array([yTrain[j][iModel]
for j in range(lenTrain)])
models.append(enet_path(xTrain, yTemp,l1_ratio=1.0,
fit_intercept=False, eps=0.5e-3, n_alphas=nAlphas ,
return_models=False))
for iStep in range(1,nAlphas):
#Assemble the predictions for all the models, find largest
#prediction and calc error
allPredictions = []
for iModel in range(nlabels):
_, coefs, _ = models[iModel]
predTemp = list(numpy.dot(xTest, coefs[:,iStep]))
#un-normalize the prediction for comparison
predUnNorm = [(predTemp[j]*ySD[iModel] + yMeans[iModel]) \
for j in range(len(predTemp))]
allPredictions.append(predUnNorm)
predictions = []
for i in range(lenTest):
listOfPredictions = [allPredictions[j][i] \
for j in range(nlabels) ]
idxMax = listOfPredictions.index(max(listOfPredictions))
if labelList[idxMax] != labelsTest[i]:
misClass[iStep] += 1.0
misClassPlot = [misClass[i]/nrow for i in range(1, nAlphas)]
plot.plot(misClassPlot)
plot.xlabel("Penalty Parameter Steps")
plot.ylabel(("Misclassification Error Rate"))
plot.show()
代码第一部分用于从 UCI 网站读取数据,同时将属性与标签分离开。属性以常见的方式进行归一化。使用“一对所有”进行多类别分类的方法在标签处理上存在一些差异。
“一对所有”方法针对每个标签生成一个要预测的标签向量。回归和 2 分类问题只包含一个标签向量,而玻璃问题存在 6 个标签,所以对应生成 6 个标签向量。这么做的原因是:
如果将数据点划分为两组,一个平面就可以做到。如果问题是将数据点划分为 6 组,那么需要多个平面。
“一对所有”训练的分类器个数与标签个数相同。这些不同分类器针对不同的标签向量训练得到。代码清单 5-7 展示了如何基于给定问题的原始类别标签来构建新的标签。
方法非常类似于第 4 章看到的方法,用于将类别变量转换为数值变量。代码清单使用Python 集合来提取不同标签,按从小到大的顺序排列(不是完全必须的,但对保持代码条理性很有帮助),形成了一个标签列表;对于每一行数据,使用一个新的标签行来表示原始标签,如果原始标签取第一个标签值,那么新标签行的第一列为 1 ;如果原始标签取第 2 个标签值,那么新标签行的第 2 列为 1,以此类推。你可以看到为什么被称作“一对所有”了。第一列的标签会产生一个 2 分类器,用于预测样本是否取第 1 个标签值。6 个分类器的每一个都需要做类似的二分类决策。
继续往下,沿着我们熟悉的线路,代码构建一个交叉验证循环。一个较小的差别是原始标签也被切分为测试集,用于后续误分类错误的度量。模型训练存在一个明显差异,每次交叉验证会训练 6 个模型,这些模型被存储在一个列表中便于后续使用。enet_path 的调用也有一些变化。一个是 eps 参数被设置为默认 1e-3 的一半,eps 作为惩罚参数值,可以任意设置。第 4 章提到使用坐标下降方法通过减少惩罚参数来选择 eps。实际上,eps参数告诉算法进行到什么程度停止。eps 输入是惩罚参数的结束值除以起始值的比例。参数 n_alphas 控制参数更新步数。注意如果步数太大,可能算法不会收敛。如果算法收敛失败会给出警告信息。可以接着稍微调大 eps,使惩罚参数不会在每步大幅下降,或者可以调大 n_alphas 来增加步长,使得每个单独步长变小。
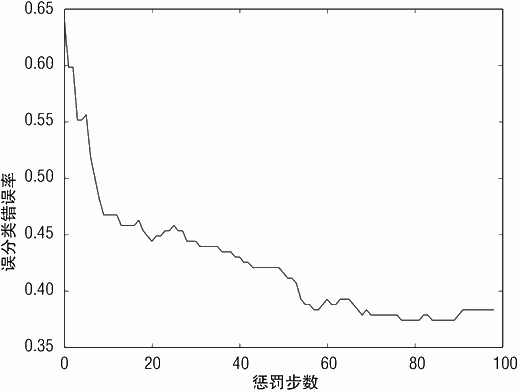
另一个注意事项是是否绘制了曲线的完整内容。图 5-12 展示了最小值非常接近于图的右侧边缘。此时要尽可能地往外延升曲线,以确保最小值被纳入视线范围。减少 eps 会继续向右绘制曲线。
训练得到的 6 个模型用于生成 6 个预测结果。代码然后检测 6 个预测结果的哪个结果有最大的数值输出,最终选择输出最大的预测。预测值接着和实际值比较,并对错误进行累加。
图 5-12 展示了误分类错误随惩罚参数减少的变化情况。图示展现了从左边的最简单模型开始,向右推进,错误最小值显著下降。误分类错误的最小值大约为 35%。该值要好于基于线性核的支持向量机。论文使用非线性核获得的误分类错误约为 35%,对于某些线性核,误分类错误低至 30%。在支持向量机中使用非线性核约等价于使用基扩展(正如本章前面红酒品质预测的例子)。基扩展在红酒品质预测中并不有效,但使用非线性核带来的性能提升预示着在玻璃分类问题也可能取得好的效果。





本书评论