2.3 对数据建模
让我们开始使用一个和两个卧室的数据集。我们将观察邮政编码和卧室数量对于出租价格的影响。这里将使用两个包:第一个是 statsmodels,我们在前一章简要讨论过,而第二个包:patsy (https://patsy.readthedocs.org/en/latest/index.html) 和statsmodels 搭档使用,使工作更轻松。在运行回归的时候,Patsy 让我们可以使用 R 风格的公式。
让我们现在开始吧。
import patsy
import statsmodels.api as sm
f = 'Rent ~ Zip + Beds'
y, X = patsy.dmatrices(f, su_lt_two, return_type='dataframe')
results = sm.OLS(y, X).fit()
print(results.summary())
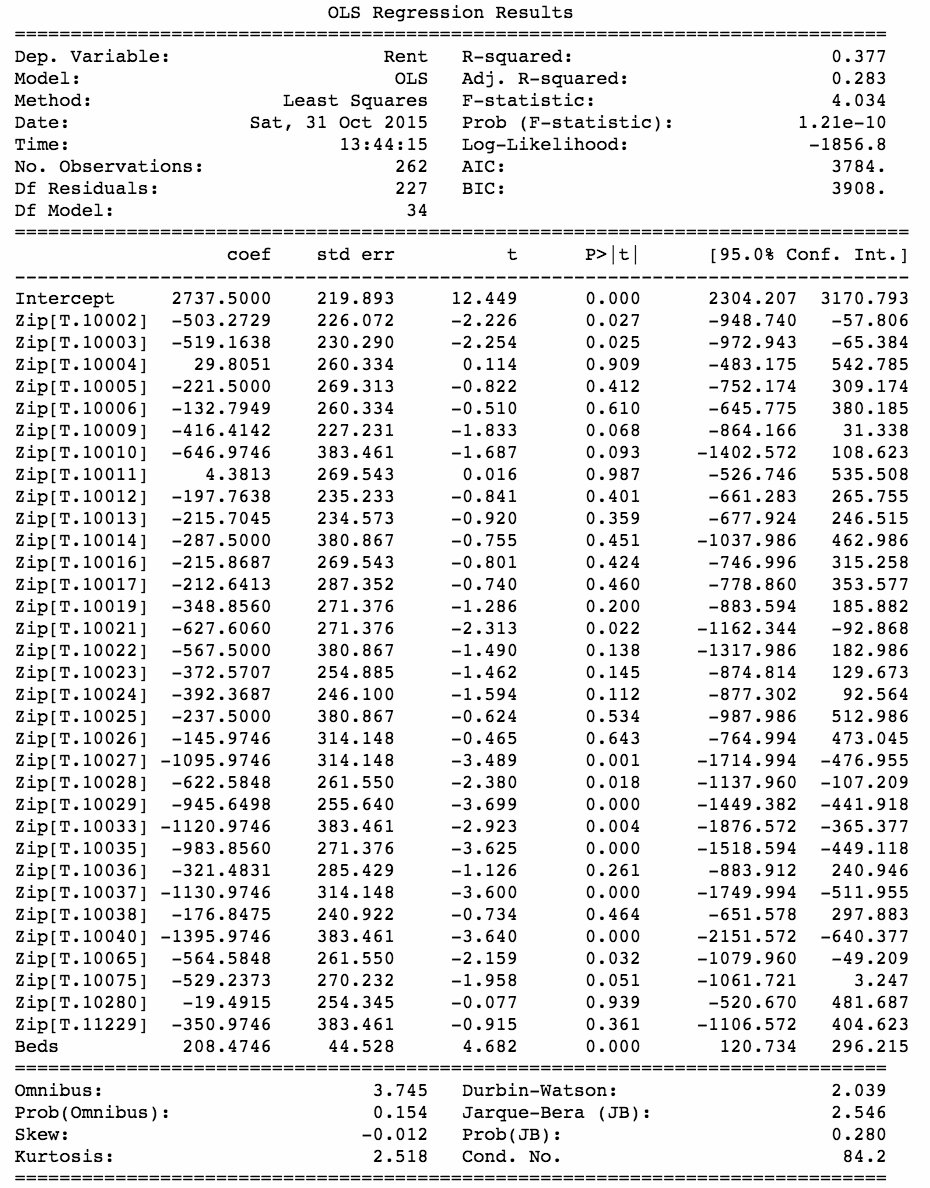
上述代码生成图 2-23 的输出。
通过这几行代码,我们刚刚运行了第一个机器学习算法。
虽然大多数人不倾向于将线性回归视为机器学习,但它实际上就是机器学习。线性回归是一种监督式的机器学习。在这种情况下,监督只是意味着我们为训练集提供了输出值①。
现在,让我们解释这其中发生的事情。在引入包之后,有两行和 patsy 模块相关的代码。
第一行是我们将要使用的公式。在左手边(波浪号之前)是反应或因变量,也就是 Rent。
在右手边,是独立或预测变量,就是 Zip 和 Beds。这个公式表示,我们想知道邮政编码和卧室数量将如何影响出租价格。
然后我们的公式将和包含相应列名的数据框一起,传递给 patsy.dmatrices()。然后设置 Patsy,让它返回一个数据框,其中 X 矩阵由预测变量组成,而 y 向量由响应变量组成。这些将被传递给 sm.OLS(),之后调用.fit()来运行我们的模型。最后,打印出模型的结果。
如你所见,输出的结果提供了大量的信息。让我们从最上面的部分开始吧。可以看到模型包括了 262 个观察样本,调整后的 R2 为 0.283,F-statistic 为 1.21e-10,具有统计的显着性。这里显著性是指什么?它意味着我们所创建的模型,仅仅使用卧室数量和邮政编码,就已经能够解释约三分之一的价格差异。这是一个满意的结果吗?为了更好地回答这个问题,让我们来看看输出的中间部分。
中间部分为我们提供了模型中每个自变量的有关信息。从左到右,我们可以看到以下信息:变量、变量在模型中的系数、标准误差、t 统计量、t 统计量的 p 值,以及 95%的置信区间。
这一切告诉我们什么?如果看 p 值这一列,我们可以确定独立变量从统计的角度来看是否具有意义。在回归模型中具有统计学意义,这意味着一个独立变量和响应变量之间的关系不太可能是偶然发生的。通常,统计学家使用 0.05 的 p 值来确定这一点。一个 0.05的 p 值意味着我们看到的结果只有 5%的可能性是偶然发生的。就这里的输出而言,卧室的数量显然是有意义的。那邮政编码怎么样呢?
首先要注意的是,我们的截距代表了 10001 的邮政编码。建立线性回归模型的时候,是需要截距的。截距就是回归线和y轴交叉的地方。Statsmodels会自动选择一个预测变量作为截距。在这里,它决定使用纽约的切尔西地区(10001)②就像卧室的数量,截距在统计上是显着的。但是,其他邮政编码又怎么样呢?
在大多数情况下,它们并不显著。不过,让我们来看看显著的几个。邮政编码——10027、10029 和 10035——都是非常显著的,并且都具有很高的负置信区间。这告诉我们,和切尔西地区一个类似的公寓相比,这些地区往往会有较低的租金价格。
因为切尔西被认为是纽约的一个时尚之地,而另三个街区都在哈林区。③及其附近——它们当然不会被认为是时尚的地方——模型与我们对真实世界的直觉,是相吻合的。
现在让我们使用这个模型进行一些预测。
①译者注:或者说是目标值。
②译者注:位于美国纽约曼哈顿的切尔西区域,以画廊、音乐、文学等各类艺术而闻名。
③译者注:纽约的黑人区。
2.3.1 预测
假设根据前面的分析,我们对三个特定的邮政编码感兴趣:10002、10003 和 10009。
我们应该如何使用已有的模型,来确定为某个公寓支付多少钱呢?下面来看看吧。
首先,需要理解模型的输入是什么样子,这样我们才知道如何输入一组新的值。让我们来看看 X 矩阵。
X.head()
上述代码生成图 2-24 的输出。

我们可以看到,输入是用所谓的虚拟变量进行编码的。由于邮政编码不是数字的,所以为了表示这个特征,系统使用了虚拟编码。如果某个公寓在 10003 中,那么该列将被编码为 1,而所有其他邮政编码都被编码为 0。而卧室是数值型的,所以系统将根据实际的数字对其进行编码。现在,让我们创建自己的输入行进行预测。
to_pred_idx = X.iloc [0] .index
to_pred_zeros = np.zeros(len(to_pred_idx))
tpdf = pd.DataFrame(to_pred_zeros,index = to_pred_idx,columns = ['value'])
tpdf
上述代码生成图 2-25 的输出。
我们刚刚使用了 X 矩阵的索引,并用零填充数据。现在让我们填入一些实际的值。我们要对一个位于 10009 区域的、包含一间卧室的公寓进行估价。
tpdf.loc['Intercept'] = 1
tpdf.loc['Beds'] = 1
tpdf.loc['Zip[T.10009]'] = 1
tpdf
对于线性回归,截距值必须设置为 1,模型才能返回正确的统计值。
上述代码生成图 2-26 的输出。

这里我们可以看到截距和 10009 邮政编码已经被设置为 1 了。

在图 2-27 中,我们可以看到卧室的数量也已经被设置为 1 了。
我们已经将特征设置为了适当的值,现在使用该模型返回一个预测。
results.predict(tpdf['value'])
上述代码生成如下输出。
2529.5604669841355
请记住,results 是我们保存模型的变量名。这个模型对象有一个.predict()方法,我们使用自己的输入值调用该方法。正如你可以看到的,模型返回了预测的值。
如果我们想要在条件中增加一间卧室怎么办?
来改变一下输入并看看结果。
tpdf['value'] = 0
tpdf.loc['Intercept'] = 1
tpdf.loc['Beds'] = 2
tpdf.loc['Zip[T.10009]'] = 1
tpdf
上述代码生成了图 2-28 的输出。
我们可以看到卧室数量已经被更新为 2。
现在,我们将再次运行预测。
results.predict(tpdf['value'])
上述代码生成以下输出。
2738.035104645339
看起来,额外增加的卧室每个月将花费我们大约 200 美元。如果我们选择 10002 地区呢?让我们在代码中实现这个。
tpdf['value'] = 0
tpdf.loc['Intercept'] = 1
tpdf.loc['Beds'] = 2
tpdf.loc['Zip[T.10002]'] = 1
results.predict(tpdf['value'])
上述代码生成以下输出。
2651.1763504369078
根据我们的模型,如果选择 10002 而不是 10009 地区,我们可以在两卧室的公寓上少花一些钱。
2.3.2 扩展模型
到了目前这个阶段,我们只检视了邮政编码、卧室和出租价格之间的关系。虽然这个模型有一定的解释能力,但是,我们的数据集太小,使用的特征也太少,无法充分地观测房地产估值这个复杂的市场。
然而,幸运的是,我们即将向该模型添加更多的数据和特征,而且可以使用完全相同的框架来扩展我们的分析。
未来可扩展的探索包括利用 Foursquare 或 Yelp API 所提供的餐馆和酒吧数据,或者是Walk Score 这类供应商所提供的可步行性和交通便利性指标。
要扩展这个模型有很多的方法,我建议你在一个方向上持续努力,例如探索各种指标。
随着每天更多的数据被发布,你的模型会不断地改善。





本书评论