2.2 检查和准备数据
我们现在有一个包含 500 套公寓的数据集。来看看其中有什么。首先在 Jupyter 记事本中,使用 pandas 导入数据。
import pandas as pd
import re
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
%matplotlib inline
pd.set_option("display.max_columns", 30)
pd.set_option("display.max_colwidth", 100)
pd.set_option("display.precision", 3)
# Use the file location of your Import.io csv
CSV_PATH = r"/Users/alexcombs/Downloads/magic.csv"
df = pd.read_csv(CSV_PATH)
df.columns
上述代码生成图 2-4 中的输出。

最后一行 df.columns 为数据提供了列标题的输出。此外,让我们使用 df.head().T 查看数据的某些样本。在行结束处的.T 语法将转置我们的数据框并垂直地显示它,如图 2-5所示。
我们已经可以看出数据有一些缺失值(NaN)。需要多个操作来标准化此数据。数据集中的列(或者说是图 2-5 中转置后的行)表示了每个 Zillow 房源的单项数据。看起来似乎有两种类型的房源——一种类型是单个单元,而另一种类型是多个单元。
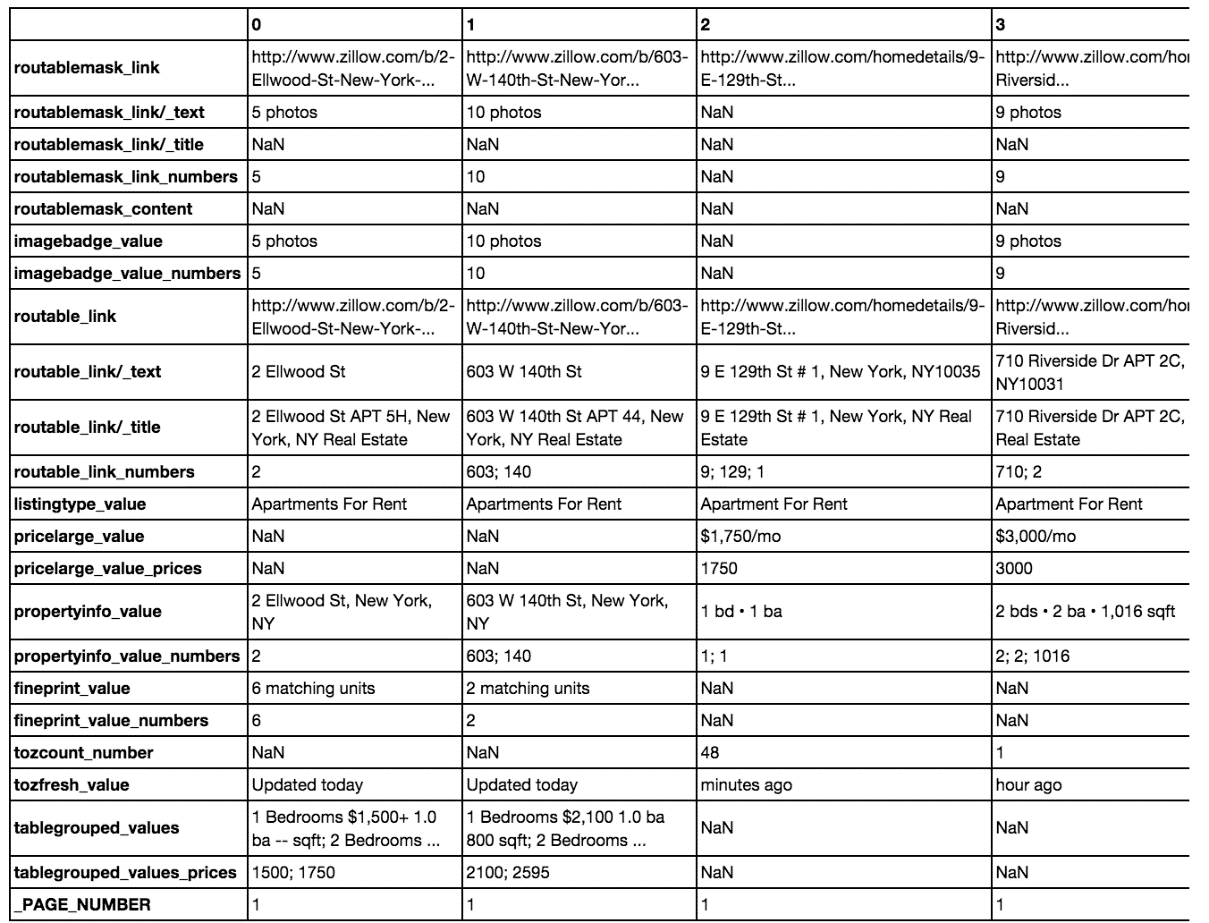
这两种类型可以在图 2-6 中看到。

这两个房源对应于在 Zillow.com 上所看到的图像,如图 2-7 所示。
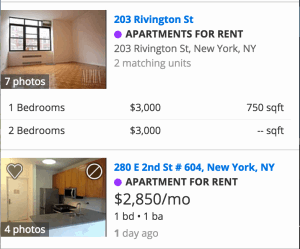
拆分这些的关键是 listingtype_value 这个列头。我们将数据拆分为单一的单元,Apartment for Rent,以及多个单元,Apartments for Rent:
# multiple units
mu = df[df['listingtype_value'].str.contains('Apartments For')]
# single units
su = df[df['listingtype_value'].str.contains('Apartment For')]
现在来看看每种房源类型的数量。
len(mu)
上述代码生成以下输出。
161
len(su)
上述代码生成以下输出。
339
由于大多数房源属于单一单元的类型,我们现在将从此开始。
接下来,我们需要将数据格式化为标准结构。例如,至少需要为卧室数、浴室数、平方英尺和地址各准备一列。
从之前的观察中可以发现,我们已经有一个清晰的价格列,那就是pricelarge_value_prices。幸运的是,该列中没有缺失值,因此我们不会因为缺少数据而丢失任何的房源。
卧室和浴室的数量以及平方英尺将需要一些解析,因为它们全都挤在单一的列中。让我们解决这个问题。
先来看一下该列。
su['propertyinfo_value']
上述代码生成如图 2-8 所示的输出。

看上去,数据似乎总是包括卧室和浴室的数量,偶尔也会包含例如年份这样的额外信息。在我们继续解析之前,先来检验一下这个假设。
# 检查没有包含'bd'或'Studio'的行数
len(su[~(su['propertyinfo_value'].str.contains('Studio')\
|su['propertyinfo_value'].str.contains('bd'))])
上述代码生成以下输出。
0
现在来看看下面几行代码。
#检查没有包含'ba'的行数
len(su[~(su['propertyinfo_value'].str.contains('ba'))])
上述代码生成以下输出。
6
看来有几行缺少浴室数量的数据。出现这种情况的原因有多种,我们可以使用一些方法来解决这个问题。一种就是填充或插补这些缺失的数据点。
关于缺失数据的主题很可能讨论一整章甚至是一本书,这里我建议投入一些时间来理解这个课题,它是建模过程中一个关键的组成部分。然而,这并非此处讨论的主要目的,所以我们将假设数据的缺失是随机的,即使删除这些没有浴室信息的房源,也不会使得我们的样本产生不恰当的偏向。
#选择拥有浴室的房源 ① (①这行代码中,作者使用的注释和变量名令人困惑,但是最终效果是一样的。)
no_baths = su[~(su['propertyinfo_value'].str.contains('ba'))]
#再排除那些缺失了浴室信息的房源
sucln = su[~su.index.isin(no_baths.index)]
现在我们可以继续解析卧室和浴室信息:
#使用项目符号进行切分
def parse_info(row):
if not 'sqft' in row:
br, ba = row.split('')[:2]
sqft = np.nan
else:
br, ba, sqft = row.split('.')[:3]
return pd.Series({'Beds': br, 'Baths': ba, 'Sqft': sqft})
attr = sucln['propertyinfo_value'].apply(parse_info)
attr
上述代码生成图 2-9 的输出。

这里我们做了些什么?我们在 propertyinfo_value 列上运行了 apply 函数。然后该操作返回一个数据框,其中每个公寓属性都会成为单独的列。在最终完成之前,还有几个额外的步骤。我们需要在取值中删除字符串(bd、ba 和 sqft),并且需要将这个新的数据框和原始的数据进行连接。让我们现在就这么做吧。
#在取值中将字符串删除
attr_cln = attr.applymap(lambda x: x.strip().split(' ')[0] if
isinstance(x,str) else np.nan)
attr_cln
上述代码生成图 2-10 的输出。
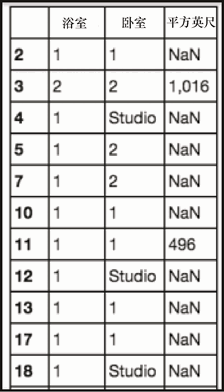
让我们来看看下面的代码。
sujnd = sucln.join(attr_cln)
sujnd.T
上述代码生成图 2-11 的输出。
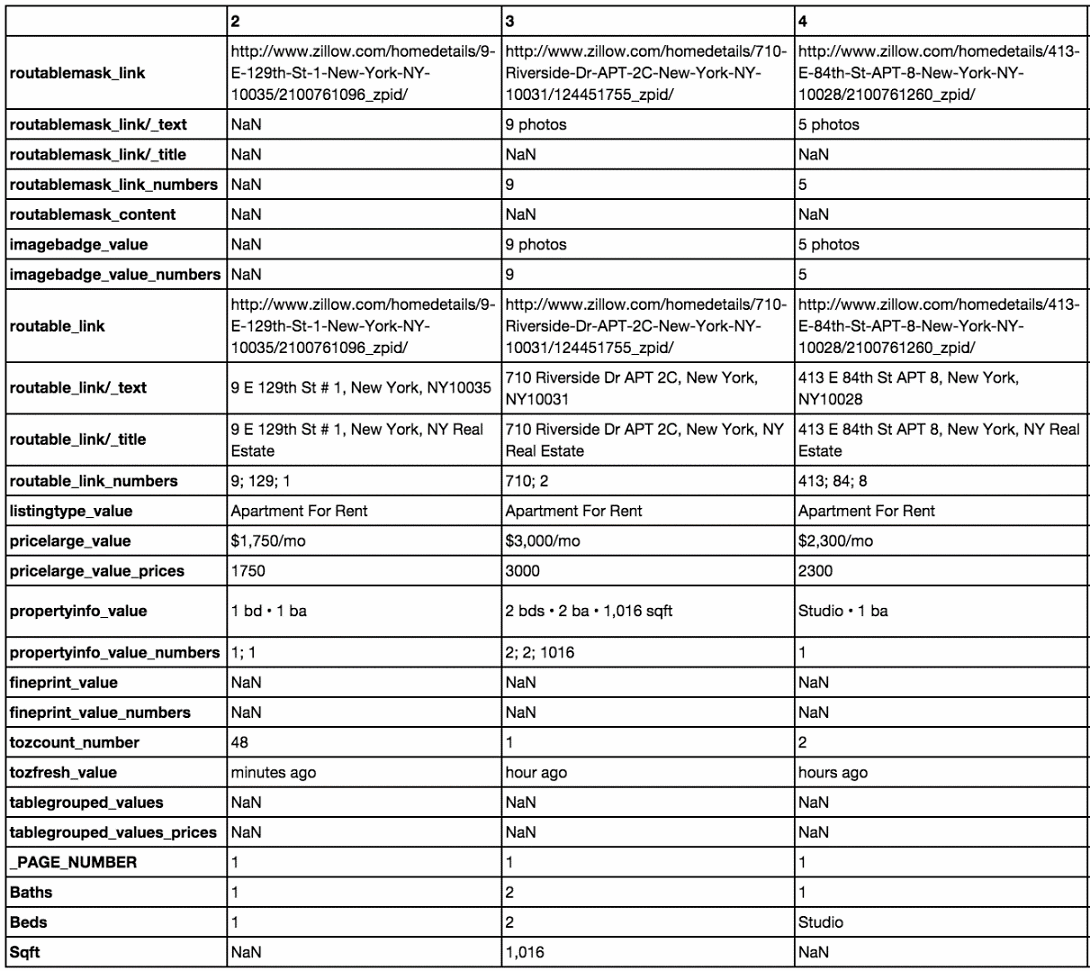
到了这个时刻,各方面的数据集开始聚集在一起了。我们可以基于卧室的数量、浴室的数量和面积的平方英尺数,来测试关于公寓价值的假设。但是,正如行业专家所说,房地产的区域最为关键。让我们采取和之前相同的属性解析方法,并将其应用到公寓的地址上。
如果可能,我们还将尝试提取楼层的信息。这里我们假设一个模式,其中一个数字后面跟随一个字母,而该数字就表示建筑物的楼层。
# parse out zip, floor
def parse_addy(r):
so_zip = re.search(', NY(\d+)', r)
so_flr = re.search('(?:APT|#)\s+(\d+)[A-Z]+,', r)
if so_zip:
zipc = so_zip.group(1)
else:
zipc = np.nan
if so_flr:
flr = so_flr.group(1)
else:
flr = np.nan
return pd.Series({'Zip':zipc, 'Floor': flr})
flrzip = sujnd['routable_link/_text'].apply(parse_addy)
suf = sujnd.join(flrzip)
suf.T
上述代码生成图 2-12 的输出。
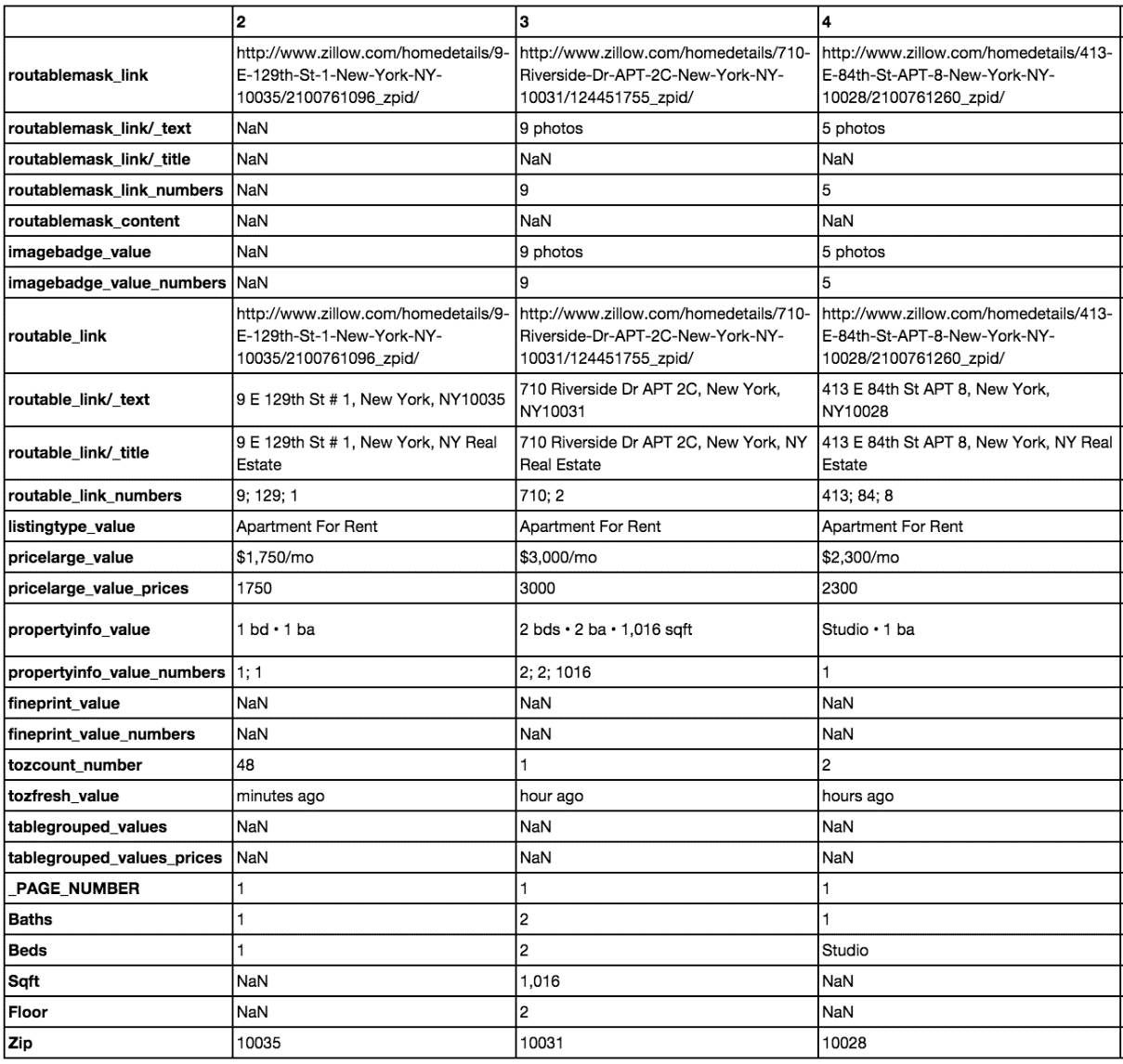
正如你所看到的,当楼层和邮编信息出现的时候,我们能够成功地解析出它们。这使我们从 333 个房源中获得了 320 个带有邮政编码信息的房源和 164 个带有楼层信息的房源。
最终进行一点清理,然后我们即将开始检查这个数据集。
#我们将数据减少为所感兴趣的那些列
sudf = suf[['pricelarge_value_prices', 'Beds', 'Baths', 'Sqft', 'Floor','Zip']]
# 我们还会清理奇怪的列名,并重置索引
sudf.rename(columns={'pricelarge_value_prices':'Rent'}, inplace=True)
sudf.reset_index(drop=True, inplace=True)
sudf
上述代码生成图 2-13 的输出。
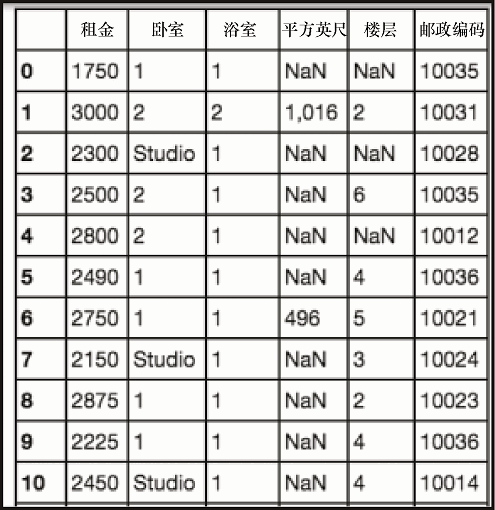
2.2.1 分析数据
到了这个阶段,数据已经是我们分析时所需要的格式了。让我们从一些总体的统计数据分析开始。
sudf.describe()
上述代码生成图 2-14 的输出。
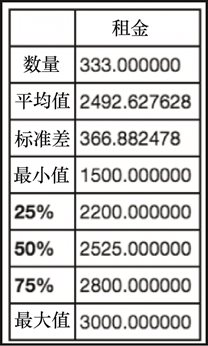
这里可以看到租金的统计细分。不要忘记我们从 Zillow 的原始数据中,只选择了每月价格在 1500 到 3000 美元之间的公寓。在这里无法看到的是卧室和浴室的平均数量,或者楼层的平均数。导致这个现象的问题有两个。第一个问题涉及卧室。我们需要所有的数据都为数值型才能获得统计。可以将工作室公寓认定为一个零卧室的公寓(实际也确实如此),来解决这个问题。
# 我们将出现的'Studio'替换为 0
sudf.loc[:,'Beds'] = sudf['Beds'].map(lambda x: 0 if 'Studio' in x else x)
sudf
上述代码生成图 2-15 的输出。
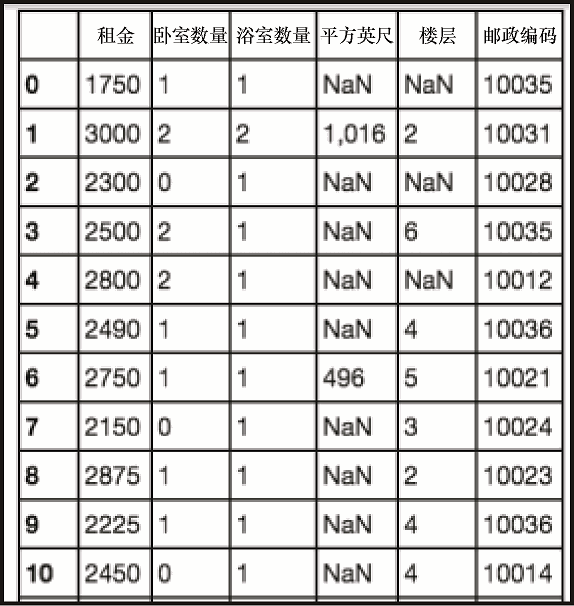
这解决了第一个问题,但我们还有另一个问题。任何需要统计数据的列必须是数值类型。正如你在图 2-16 的截图所见,情况并非如此。
sudf.info()
上述代码生成图 2-16 的输出。

我们可以通过更改数据类型来解决这个问题,如下面的代码所示。
# 让我们解决列中数据类型的问题
sudf.loc[:,'Rent'] = sudf['Rent'].astype(int)
sudf.loc[:,'Beds'] = sudf['Beds'].astype(int)
# 存在半间浴室的情况,因此需要浮点型
sudf.loc[:,'Baths'] = sudf['Baths'].astype(float)
#存在 NaNs,需要浮点型,但是首先要将逗号替换掉
sudf.loc[:,'Sqft'] = sudf['Sqft'].str.replace(',','')
sudf.loc[:,'Sqft'] = sudf['Sqft'].astype(float)
sudf.loc[:,'Floor'] = sudf['Floor'].astype(float)
让我们执行下面的这行代码并看看结果如何。
sudf.info()
上述代码生成图 2-17 的输出。

让我们执行下面的代码行,以便得到最终的统计数据。
sudf.describe()
上述代码生成图 2-18 的输出。
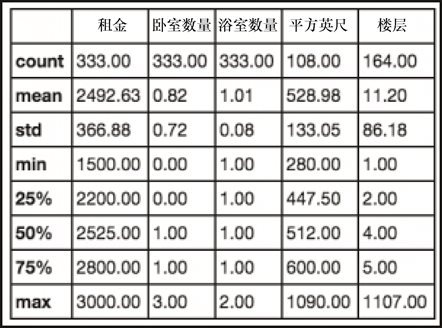
租金、卧室、浴室和平方英尺的数字都看起来不错,但是 Floor 楼层这一列似乎有些问题。在纽约,确实有很多非常高的建筑,但我想没有超过 1000 层的。
快速看过数据之后,你会发现 APT 1107A 给了我们这个结果。很可能,这是一个 11层的公寓,但是为了安全性以及一致性,我们会放弃这个房源。幸运的是,这是唯一超出30 楼的房源,所以我们的数据仍然是完好的状态。
#索引标号 318 是有问题的房源,这里放弃它
sudf = sudf.drop([318])
sudf.describe()
上述代码生成图 2-19 的输出。
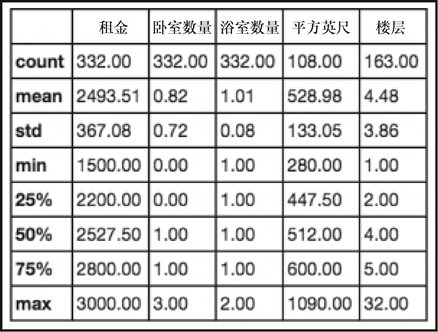
我们的数据现在看起来不错,接下来继续分析的步骤。让我们生成数据的透视图,首先通过邮政编码和卧室数量来检视价格的情况。Pandas 有一个.pivot_table()函数,使这个操作变得很容易。
sudf.pivot_table('Rent', 'Zip', 'Beds', aggfunc='mean')
上述代码生成图 2-20 的输出。
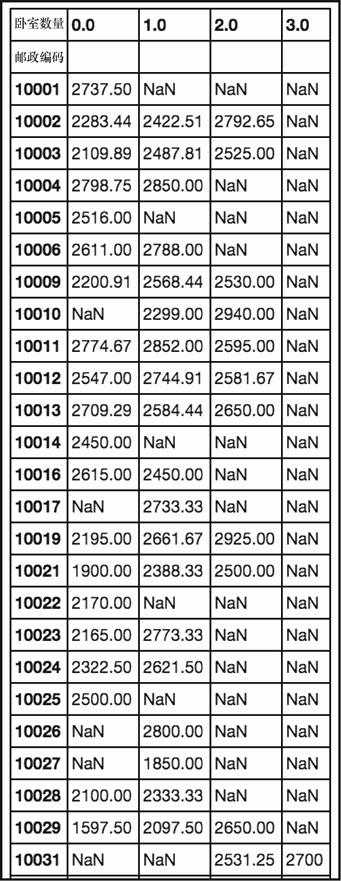
此操作可让我们按照邮政编码来查看平均价格。正如你所见,随着房间数量的增加,我们将看到越来越少的房源,NaN 值就是很好的证明。为了进一步探究其原因,我们可以基于房源的数量进行透视。
sudf.pivot_table('Rent', 'Zip', 'Beds', aggfunc='count')
上述代码生成图 2-21 的输出。
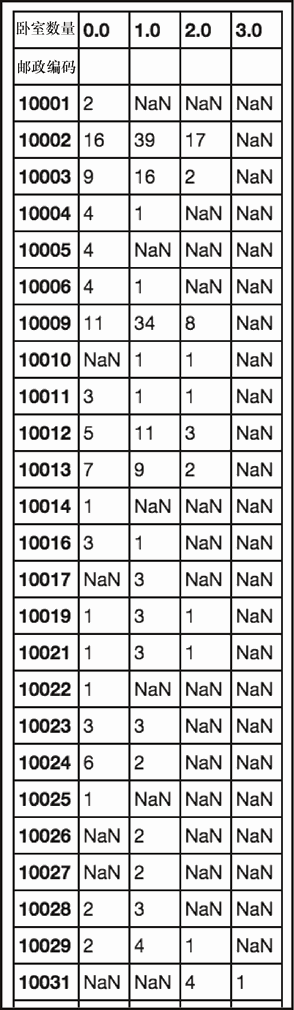
从图 2-21 可以看出,根据邮政编码和卧室数量的维度来分析,我们的数据是稀疏的。
这是不幸的,理想情况下,我们应该需要更多的数据。尽管如此,我们仍然可以进行分析。
现在要通过可视化的方式来检视手头的数据。
2.2.2 可视化数据
由于目前的数据是基于邮政编码的,因此最好的可视化方法是使用热图 ①。如果你不熟悉热图,那么简单地来理解它只是按照色谱来表示数据的可视化。现在,让我们使用名为folium的 Python 映射库来实现这一点(https://github.com/python-visualization/folium)。
由于缺少包含两到三间卧室的公寓,让我们缩减数据集,聚焦到工作室和一间卧室的房源。
su_lt_two = sudf[sudf['Beds']<2]
现在我们将继续创建可视化。
import folium
map = folium.Map(location=[40.748817, -73.985428], zoom_start=13)
map.geo_json(geo_path=r'/Users/alexcombs/Downloads/nyc.json',
data=su_lt_two,
columns=['Zip', 'Rent'],
key_on='feature.properties.postalCode',
threshold_scale=[1700.00, 1900.00, 2100.00, 2300.00, 2500.00,
2750.00],
fill_color='YlOrRd', fill_opacity=0.7, line_opacity=0.2,
legend_name='Rent (%)',
reset=True)
map.create_map(path='nyc.html')
上述代码生成图 2-22 的输出。
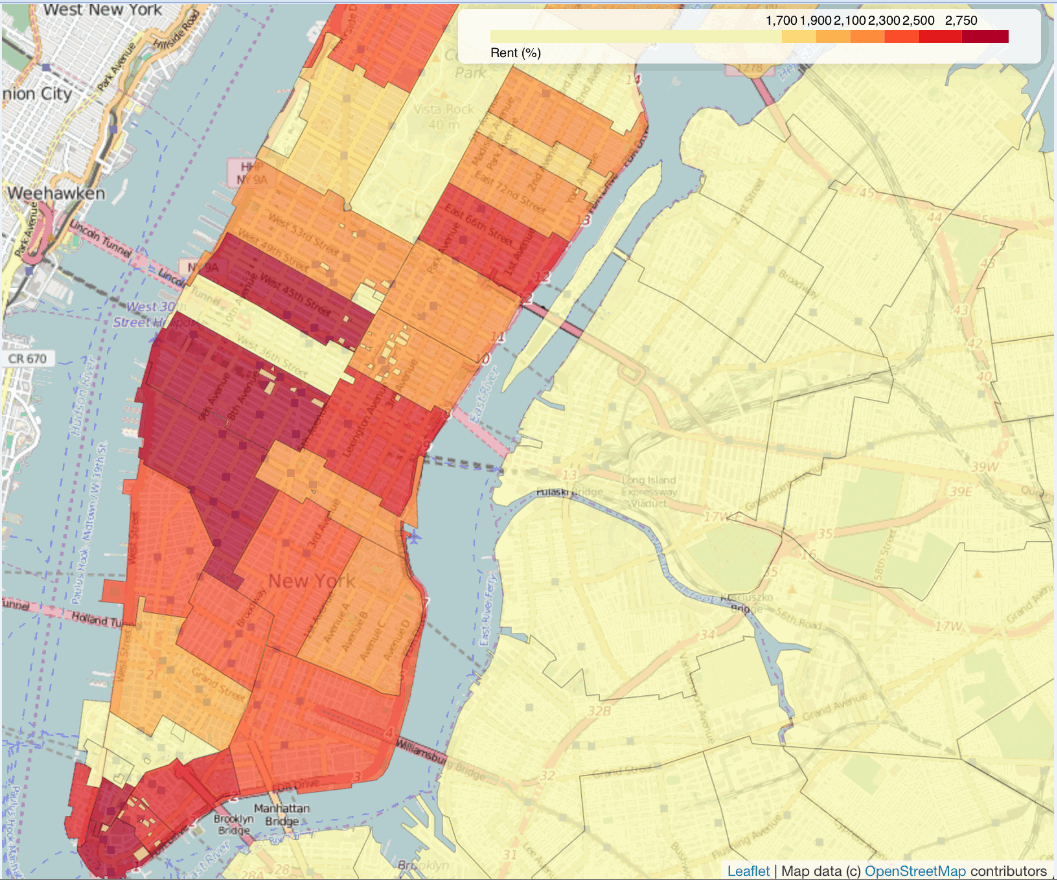
这里发生了很多事情,所以让我们一步一步来分析。导入 folium 后,我们创建了一个.Map()对象。为了使地图居中,还需要传入坐标和缩放级别。我在 Google 上搜索了帝国大厦的坐标(你需要使用经度的正负符号),并调整缩放,使帝国大厦出现在我想要居中的地方。
下一行代码需要一个称为 GeoJSON 文件的东西。这是一个表示地理属性的开放格式来。通过搜索 NYC GeoJSON 文件,我找到了一个,特别是它还包含了邮政编码的映射。
一旦传入了 GeoJSON 文件与邮政编码之后,你还需要传入数据框。
然后你需要引用键列(在这个例子中为 Zip)以及你希望用于热图的列。在我们的例子中将使用租金的中位数。其他选项用于确定颜色的调色板、颜色改变的取值以及某些用于调整图例和着色的其他参数。最后一行代码确定了输出文件的名称。
如果你在本地机器上使用这些代码,你可能会在Chrome 浏览器中遇到一个问题。阴影部分似乎不正常。Chrome 认为其是跨域请求,因此拒绝执行它,而且由于此,你将无法看到热图的叠加部分。Internet Explorer 和 Safari 浏览器应该可以正常显示。
随着热图完成,我们可以感受到哪些地区有更高的或更低的租金。如果你租房的时候关注某个特定的区域,这将很有帮助。不过,让我们继续使用回归建模,进行更为深入的分析。
①译者注:热图可以帮助显示基于地理位置的信息,所以适合邮编相关的分析。





本书评论