1.2 什么是惩罚回归方法
惩罚线性回归方法是由普通最小二乘法(ordinary least squares,OLS)衍生出来的。
而普通最小二乘法是在大约 200 年前由高斯(Gauss)和法国数学家阿德里安 - 马里 · 勒让德(Legendre)提出的。惩罚线性回归设计之初的想法就是克服最小二乘法的根本缺陷。
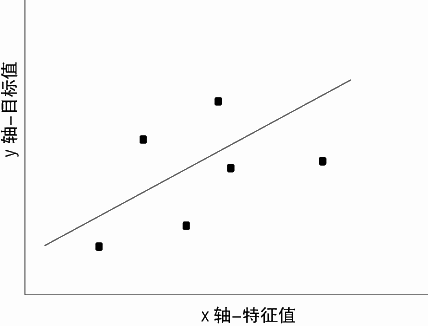
最小二乘法的一个根本问题就是有时它会过拟合。如图 1-1 所示,考虑用最小二乘法通过一组点来拟合一条直线。这是一个简单的预测问题:给定一个特征 x,预测目标值 y。例如,可以是根据男人的身高来预测其收入。根据身高是可以稍微预测男人的收入的(但是女人不行)。
图 1-1 中的点代表(男人的身高、男人的收入),直线代表使用最小二乘法的预测结果。
在某种意义上说,这条直线就代表了在已知男人身高的情况下,对男人收入的最佳预测模型。现在这个数据集有 6 个点。假设这个数据集只有 2 个点。想象有一组点,就像图 1-1中的点,但是你不能获得全部的点。可能的原因是要获得所有这些点的代价太昂贵了,就像前面提到的基因组数据。只要有足够多的人手,就可以分离出犯罪分子的基因组,但主要问题是代价的原因,你不可能获得他们的全部基因序列。
以简单的例子来模拟这个问题,想象只给你提供当初 6 个点中的任意 2 个点。那么拟合出来的直线会发生哪些变化?这将依赖于你得到的是哪 2 个点。实际看看这些拟合的效果,可以从图 1-1 中任意选出 2 个点,然后想象穿过这 2 个点的直线。图 1-2 展示了穿过图 1-1 中 2 个点的可能的直线。可以注意到拟合出来的直线依赖于这 2 个点是如何选择的。
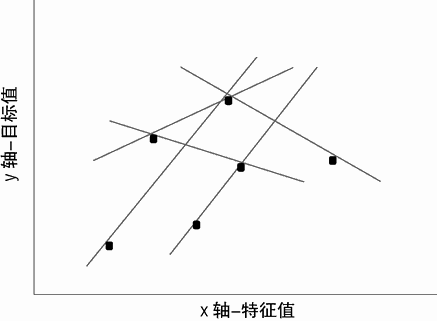
使用 2 个点来拟合一条直线的主要问题是针对直线的自由度(degrees of freedom)①没有提供足够的数据。一条直线有 2 个自由度。有 2 个自由度意味着需要 2 个独立的参数才能唯一确定一条直线。可以想象在一个平面抓住一条直线,然后在这个平面上下滑动这条直线,或者旋转它以改变其斜率。与 x 轴的交点和斜率是相互独立的,它们可以各自改变,两者结合在一起确定了一条直线。一条直线的自由度可以表示成几种等价的方式(可以表示成与 y 轴的交点和斜率、直线上的 2 个点,等等)。所有这些确定一条直线的表示方法都需要 2 个参数。
当自由度与点数相同时,预测效果并不是很好。连接这些点构成了直线,但是在不同点对之间可以形成大量不同的直线。对在自由度与点数相同的情况下所做的预测并不能报太大的信心。图 1-1 是 6 个点拟合一条直线(2 个自由度)。也就是说 6 个点对应 2 个自由度。从大量的人类基因中找到可导致遗传基因的问题可以阐明相似的道理。例如要从大约 20000 个人类基因中找到可导致遗传的基因,可选择的基因越多,需要的数据也越多。
20000 个不同基因就代表 20000 个自由度,甚至从 20000 个人获取的数据都不足以得到可靠的结果,在很多情况下,一个相对预算合理的研究项目只能负担得起大约 500 个人的样本数据。在这种情况下,惩罚线性回归就是最佳的选择了。
惩罚线性回归可以减少自由度使之与数据规模、问题的复杂度相匹配。对于具有大量自由度的问题,惩罚线性回归方法获得了广泛的应用。在下列问题中更是得到了偏爱:
基因问题,通常其自由度(也就是基因的数目)是数以万计的;文本分类问题,其自由度可以超过百万。第 4 章将提供更多的细节:这些方法如何工作、通过示例代码说明算法的机制、用 Python 工具包实现一个机器学习系统的过程示例。
① 自由度:统计学上的自由度(degree of freedom, df)是指当以样本的统计量来估计总体的参数时,样本中独立或能自由变化的自变量的个数称为该统计量的自由度。





本书评论