5.0 简介
有时候,根据某种特性而不是数量来度量对象会更有效。我们常常使用这种定性的信息来判断一个观察值的属性,比如按照性别、颜色或者车的品牌这样的类别对其分类。但并不是所有的分类数据都是这样的。本身没有内在顺序的类别称为nominal,以下类别都属于nominal类别:
● 蓝色、红色、绿色
● 男性、女性
● 香蕉、草莓、苹果
相反,如果一组分类天然拥有内在的顺序性,它就被称为ordinal,例如:
● 低、中、高
● 年轻、年迈
● 同意、中立、反对
此外,分类信息常常用一个字符串型的向量或列(例如,"Maine"、"Texas"、" Delaware")表示,但大部分机器学习算法都要求其输入是数值型的数据。
KNN(K-Nearest Neighbor,K近邻)算法就是一个简单的例子。该算法的第一步是计算两个观察值之间的距离,通常使用的是欧氏距离:
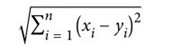
其中,x和y是两个观察值,下标i表示这是观察值的第i个特征。如果x i是一个字符串(例如"Texas"),那么要计算距离显然是不可能的。
因此,需要将字符串转换成某种数值形式,这样才能使用欧氏距离的计算公式。我们的目标是将分类数据中包含的信息合理地转换成数值(分类的序列数、两个分类之间的间距等)。本章会介绍多种转换方法,来应对在处理分类数据时经常碰到的一些问题。





本书评论