3.13 根据值对行分组
问题描述
要根据一些共有的值(shared value)对行分组。
解决方案
groupby是pandas中最强大的功能之一:

讨论
groupby才是数据整理工作的真正起点。经常会遇到这种情况:数据帧的每一行代表的是一个人或者一个事件,而我们需要根据某些标准对这些行分组并计算某个统计量。例如,假设有一个数据帧,其中每一行都是一家国际连锁餐厅分店的一条销售记录。如果想要知道每一家分店的销售总额,可以将销售记录按照分店分组并计算每一组的总和。
不熟悉groupby的用户经常会写一行下面的语句,然后就被返回的值弄晕了:
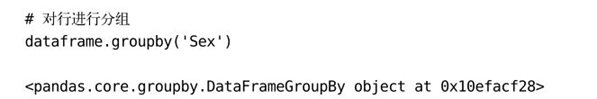
为什么不返回一些更有用的东西?原因是groupby需要和一些作用于组(group)的操作配合使用,比如计算一个综合统计量(例如,平均值、中位数、总和)。当说到分组时,我们总是用“按照性别分组”这样的简单说法,其实这是不完整的。为了让分组能更有用,我们需要根据某种标准进行分组,然后对每一组应用一个函数:
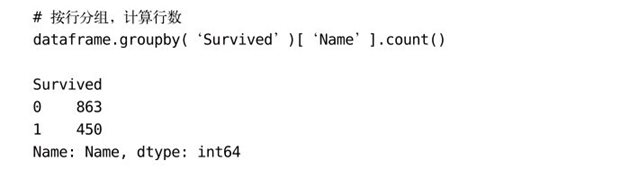
注意到Name被加到groupby的后面了吗?这是因为特定的描述性统计量只对特定的数据类型来说才有意义。比如,按照性别来计算平均年龄是有意义的,但是按照性别来计算总年龄就没有什么意义。在上面这个例子中,我们先按照乘客是否幸存做了分组,然后计算了每一组名字的数量(也就是乘客的数量)。
当然,也可以先按照第一列分组,再按照第二列对前面的结果进行二次分组:






本书评论