3.0 简介
“数据整理(data wrangling)”是一个被广泛使用的词,经常用于描述将原始数据转换成整洁的、组织合理的形式以供使用的过程。对于我们而言,数据整理只是数据预处理中的一个步骤,但它是一个重要的步骤。
在“整理”数据时,最常用的数据结构是数据帧(data frame),它既直观又灵活。数据帧是呈表格状的,也就是说,就像你在数据表中看到的数据一样,数据帧是用行和列来表示数据的。下面给出一个用泰坦尼克号乘客的数据创建的数据帧:
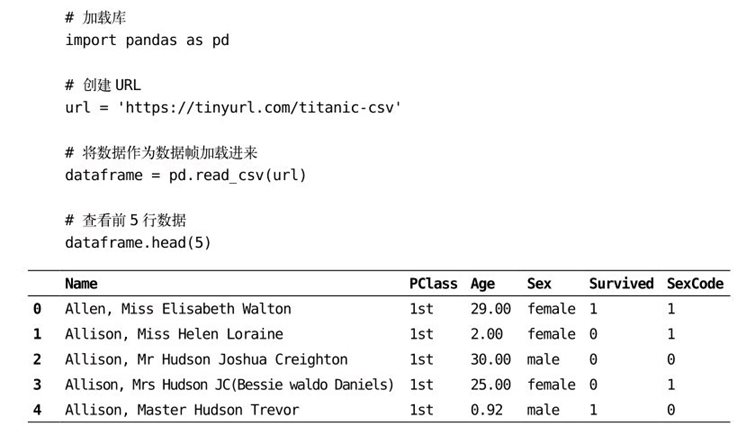
在这个数据帧中有三件重要的事情需要注意。
第一,在一个数据帧中,每一行都对应一个观察值(例如,一位乘客),每一列都对应一个特征(性别、年龄等)。举个例子,通过查看第一个观察值可知,Elisabeth Walton Allen小姐住在头等舱,当年29岁,在灾难中活了下来。
第二,每一列有一个数据头(例如,Name、PClass、Age),每一行有一个索引(例如,这位幸运的Elisabeth Walton Allen小姐的索引号是0)。这些数据能用于选择及操作观察值与特征。
第三,Sex和SexCode这两列虽然用的是不同的表现形式,但是包含了同样的信息。在Sex列中,女性用字符串female表示,而在SexCode列中,女性用整数1表示。如果想让所有的特征都是唯一的,需要删除这两列中的一列。
在本章中,为了创建一组整洁、组织合理的观察值以供接下来的预处理之用,我们会调用pandas库,使用各种不同的方法来操作数据帧。





本书评论