17.3 计算预测分类的概率
问题描述
想知道观察值被预测为某个分类的概率。
解决方案
如果使用scikit-learn的SVC,可以设置probability=True,然后训练模型,接着可以使用predict_proba来查看校准后的概率:

讨论
前面讲过的很多监督学习算法都使用概率来预测分类。比如,在KNN算法中,观察值的k个邻居的分类被记作投票数,以此计算观察值属于某个分类的概率。概率最大的分类就被认为是这个观察值所属的类别。
SVC算法使用一个超平面来创建决策区间,这种做法并不会直接计算出观察值属于某个分类的概率。但是,我们可以输出校准过的分类概率,并给出几点说明。在有两个分类的SVC中可以使用Platt缩放(Platt scaling),它首先训练这个SVC,然后训练一个独立的交叉验证逻辑回归模型将SVC的输出转换为概率:
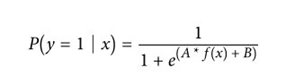
这里A和B是参数向量,f是第i个观察值到超平面的距离。如果数据集中不止两个分类,就可以使用Platt缩放的扩展。
计算预测分类的概率有两个主要的问题:第一,因为我们还训练了一个带交叉验证的模型,所以生成预测分类概率的过程会显著增加模型训练的时间;第二,因为预测的概率是通过交叉验证计算出来的,所以它们可能不会总是与预测的分类匹配。也就是说,一个观察值可能被预测为属于分类1,但是它被预测为属于分类1的概率却小于0.5。
在scikit-learn中,这些预测的概率必须在训练该模型时计算出来。我们可以通过设置SVC的probability参数为True来做到这一点。在模型被训练完之后,可以使用predict_proba方法输出观察值为每个分类的预测概率。





本书评论