14.1 训练决策树分类器
问题描述
使用决策树训练分类器。
解决方案
使用scikit-learn中的DecisionTreeClassifier:


讨论
决策树的训练器会尝试找到在节点上能够最大限度降低数据不纯度(impurity)的决策规则。度量不纯度的方式有许多,DecisionTreeClassifier默认使用基尼不纯度(Gini impurity):
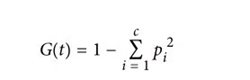
其中,G(t)是节点t的基尼不纯度,pi是在节点t上第i类样本的比例。
寻找使不纯度降低的决策规则的过程会被递归执行,直到所有叶子节点都变为纯节点(即仅包含一种分类)或达到某个终止条件。
在scikit-learn中,DecisionTreeClassifier的使用方式与其他学习算法类似,首先用fit方法训练模型,然后就可以用训练好的模型来预测一个样本的分类:

也可以使用predict_proba方法查看该样本属于每个分类(预测的分类)的概率:

最后,如果想使用其他的不纯度度量方式,可以修改参数criterion:

延伸阅读
●《决策树学习》(Princeton大学官网,http://bit.ly/2FqJxlj)





本书评论