11.7 分类器性能的可视化
问题描述
给定测试集数据的预测分类和真实分类,希望能够可视化地比较不同模型的性能。
解决方案
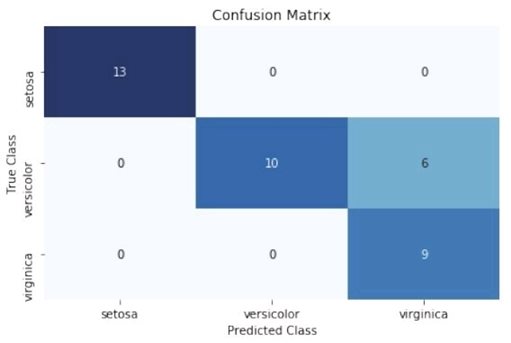
使用混淆矩阵(Confusion Matrix,如202页的图所示)来比较预测分类(Predicted Class)和真实分类(True Class):


讨论
混淆矩阵是将分类器性能可视化的简单有效的方式。它的一个主要的优点就是很容易解释。矩阵(通常以热力图形式呈现)的每一列表示样本的预测分类,而每一行表示样本的真实分类。最终每个单元格都是预测分类和真实分类的一种可能的组合。或许用一个例子能清楚地解释。在本节的解决方案中,左上角的单元格是被预测为Iris setosa分类的样本数(由列表示),其真实分类也是Iris setosa分类的样本数(由行表示)。
这说明我们的模型准确地预测了所有分类为Iris setosa的样本。然而,该模型在预测Iris virginica分类时表现不佳。右下角的单元格表明,该模型成功地预测了9个真实分类为Iris virginica的样本,但是(右侧中间的单元格)却将6个真实分类为Iris versicolor的样本预测为Iris virginica。
关于混淆矩阵有三点值得注意。首先,一个完美的模型,其混淆矩阵应该只有对角线上才有值,而其他位置应该全为零;而一个糟糕的模型,其混淆矩阵看起来像就是将样本均匀分配到了各个单元格上。其次,混淆矩阵不仅可以显示模型将哪些样本的分类预测错了,还可以显示它是怎么分错的,即误分类的模式。例如,本节的解决方案中模型能轻松区分Iris virginica和Iris setosa的样本,却难以区分Iris virginica和Iris versicolor的样本。最后,对于任意数量的分类,混淆矩阵都适用(只是如果数据中有100万个分类,混淆矩阵可能就不那么直观了)。
延伸阅读
● 混淆矩阵(http://bit.ly/2FuGKaP)
● scikit-learn文档:混淆矩阵(http://bit.ly/2DmnICk)





本书评论