11.4 评估二元分类器
问题描述
给定一个训练后的二元分类器,评估它的性能。
解决方案
使用scikit-learn的cross_val_score方法进行交叉验证,同时使用scoring参数来决定性能评估指标,可以在准确率、精确度、召回率和F1分数等多种指标中选择。
准确率(accuracy)是一种常见的性能指标,它表示被正确预测的样本数占参与预测的样本总数的比例,其计算公式如下:
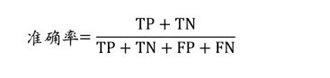
其中:
● TP是“真阳性”的数量,代表本身属于正类(如患有此类疾病、已购买此产品等),而且被正确预测的样本。
● TN是“真阴性”的数量,代表本身属于负类(如未患有此类疾病、没有购买过该产品等),而且被正确预测的样本。
● FP是“假阳性”的数量,也被称为I类错误,代表本来属于负类,却被错误预测为正类的样本。
● FN是“假阴性”的数量,也称为II类错误,代表本来属于正类,却被错误预测为负类的样本。
我们可以通过设定scoring="accuracy"来使用3折(3为默认的折数)交叉验证评估模型的准确率。

准确率的优点在于它有直观的解释:被正确预测的样本的百分比。然而,在现实世界中,样本数据的分布往往会有类别不均衡的问题(例如,99.9%的样本属于分类1,只有0.1%属于分类2)。当存在类别不均衡的情况时,使用准确率作为衡量标准会出现模型的准确率高但预测能力不足的情况。例如,我们想预测一种非常罕见的癌症(只有0.1%的发病率)在人群中的分布情况。模型训练完以后,发现其准确率达到95%。然而,99.9%的人没有罹患这种癌症,也就是说,如果我们随便创建一个简易的模型“预测”根本没有人患这种癌症,这个模型的准确率也会比训练出的模型高4.9%,但显然这没有任何意义,什么也预测不了。出于这个原因,我们通常会使用一些其他指标(如精确度、召回率和F1分数)来评估模型。
精确度(precision)是所有被预测为正类的样本中被正确预测的样本的百分比。我们可以把它看作一种衡量预测结果中的噪声的指标,即当样本被预测为正类时,预测正确的可能性有多大。具有高精确度的模型是悲观的,因为它们仅在非常确定时才会预测样本为正类。精确度可以用如下公式表示:


召回率是“真阳性”样本占所有正类样本的比例。召回率衡量的是模型识别正类样本的能力。召回率高的模型是乐观的,因为它们比较容易将样本预测为正类:
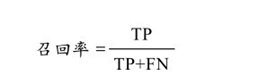

如果这是你第一次听说精确度和召回率,可能需要花一点时间才能完全理解这些概念。这两个指标与准确率相比都有一个缺点,就是不那么直观。大多数情况下,我们希望在精确度和召回率之间达到某种平衡,而F₁分数(F₁score)可以满足这种需求。 F1分数是调和平均值(一种用于概率数据的平均数):

F₁分数是衡量正类预测的正确程度(correctness)的指标,代表在被标记为正类的样本中,确实是正类的样本所占的比例。

讨论
作为评估指标,准确率包含一些有价值的特性,而且它非常易于理解。
然而,好的衡量标准往往还要在精确度和召回率之间保持某种平衡,即模型要在乐观和悲观之间保持平衡。 分数代表了召回率与精确度之间的一种平衡,两者的相对贡献是相等的。
除了使用cross_val_score方法,如果已经得到样本的真实值和预测值,我们还可以直接计算出准确率和召回率等指标:

延伸阅读
● 准确率的悖论(http://bit.ly/2FxTpK0)





本书评论