9.3 通过最大化类间可分性进行特征降维
问题描述
对特征进行降维操作,然后将其应用于分类器。
解决方案
使用线性判别分析(Linear Discriminant Analysis,LDA)方法,将特征数据映射到一个可以使类间可分性最大的成分坐标轴上。

可以使用参数explained_variance_ratio_来查看每个成分保留的信息量(即数据的差异)的情况。在本解决方案中,单个成分保留了99%的信息量:

讨论
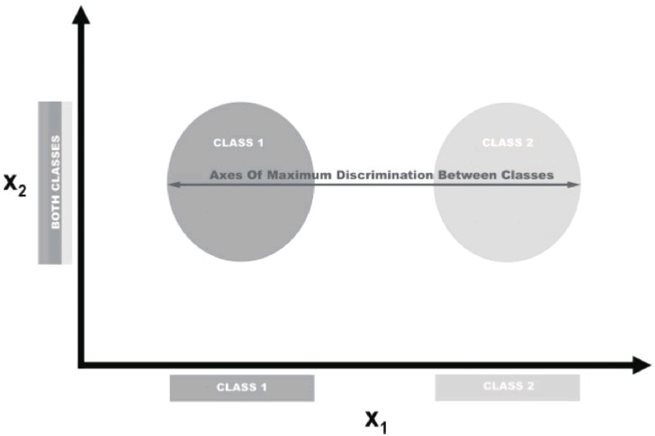
LDA是一种分类方法,也是常用的降维方法。LDA与PCA的原理类似,它将特征空间映射到较低维的空间。然而在PCA中,只需关注使数据差异最大化的成分轴;在LDA中,我们的另一个目标是,找到使得类间差异最大的成分轴。在下图所示的例子中,数据集由具有两个分类、两个特征的数据构成。如果将数据投影到y轴上,那么两类数据将不易分离(互相重叠);而如果将数据投影到x轴上,则只剩下一个特征向量(即降低了一个维度),并且仍然能保持类的可分性。当然,在现实世界中,分类之间的关系会更加复杂,维度也会更高,但概念是一样的。
在scikit-learn中,LDA是由LinearDiscriminantAnalysis方法实现的,其中包含一个参数n_components,表示需要返回的特征数量。为了找出n_components的最优值(例如,需要保留多少个参数),我们可以参考explain_variance_ratio_的输出,该排序数组表示每个输出的特征所保留的信息量(用方差表示),例如:

具体来说,可以运行LinearDiscriminantAnalysis(将参数n_components设置为None)返回每个成分特征保留的信息量的百分比,然后计算需要多少个成分特征才能保留高于阈值(通常为0.95或0.99)的信息量:

延伸阅读
● 比较LDA和PCA在Iris数据集上的二维映射(http://bit.ly/2Fs4cWe)
●《线性判别分析》(http://bit.ly/2FtiKEL)





本书评论