10.2 使用后处理来提高聚类性能
前面提到,在k均值聚类中簇的数目k是一个用户预先定义的参数,那么用户如何才能知道k的选择是否正确?如何才能知道生成的簇比较好呢?在包含簇分配结果的矩阵中保存着每个点的误差,即该点到簇质心的距离平方值。下面会讨论利用该误差来评价聚类质量的方法。
考虑图10-2中的聚类结果,这是在一个包含三个簇的数据集上运行k均值算法之后的结果,但是点的簇分配结果值没有那么准确。k均值算法收敛但聚类效果较差的原因是,k均值算法收敛到了局部最小值,而非全局最小值(局部最小值指结果还可以但并非最好结果,全局最小值是可能的最好结果)。
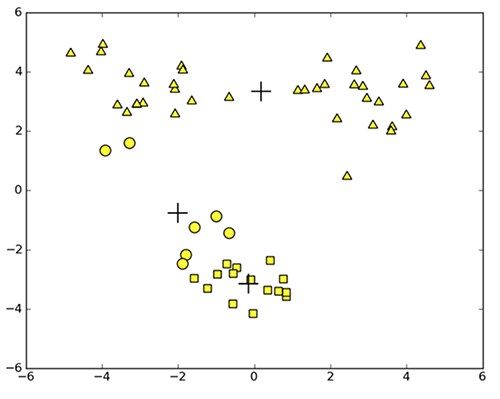
一种用于度量聚类效果的指标是SSE(Sum of Squared Error,误差平方和),对应程序清单10-2中clusterAssment矩阵的第一列之和。SSE值越小表示数据点越接近于它们的质心,聚类效果也越好。因为对误差取了平方,因此更加重视那些远离中心的点。一种肯定可以降低SSE值的方法是增加簇的个数,但这违背了聚类的目标。聚类的目标是在保持簇数目不变的情况下提高簇的质量。
那么如何对图10-2的结果进行改进?你可以对生成的簇进行后处理,一种方法是将具有最大SSE值的簇划分成两个簇。具体实现时可以将最大簇包含的点过滤出来并在这些点上运行k均值算法,其中的k设为2。
为了保持簇总数不变,可以将某两个簇进行合并。从图10-2中很明显就可以看出,应该将图下部两个出错的簇质心进行合并。可以很容易对二维数据上的聚类进行可视化,但是如果遇到40维的数据应该如何去做?
有两种可以量化的办法:合并最近的质心,或者合并两个使得SSE增幅最小的质心。第一种思路通过计算所有质心之间的距离,然后合并距离最近的两个点来实现。第二种方法需要合并两个簇然后计算总SSE值。必须在所有可能的两个簇上重复上述处理过程,直到找到合并最佳的两个簇为止。接下来将讨论利用上述簇划分技术得到更好的聚类结果的方法。





本书评论