14.5 示例:餐馆菜肴推荐引擎
现在我们就开始构建一个推荐引擎,该推荐引擎关注的是餐馆食物的推荐。假设一个人在家决定外出吃饭,但是他并不知道该到哪儿去吃饭,该点什么菜。我们这个推荐系统可以帮他做到这两点。
首先我们构建一个基本的推荐引擎,它能够寻找用户没有尝过的菜肴。然后,通过SVD来减少特征空间并提高推荐的效果。这之后,将程序打包并通过用户可读的人机界面提供给人们使用。最后,我们介绍在构建推荐系统时面临的一些问题。
14.5.1 推荐未尝过的菜肴
推荐系统的工作过程是:给定一个用户,系统会为此用户返回N个最好的推荐菜。为了实现这一点,则需要我们做到:
1. 寻找用户没有评级的菜肴,即在用户-物品矩阵中的0值;
2. 在用户没有评级的所有物品中,对每个物品预计一个可能的评级分数。这就是说,我们认为用户可能会对物品的打分(这就是相似度计算的初衷);
3. 对这些物品的评分从高到低进行排序,返回前N个物品。
好了,接下来我们尝试这样做。打开svdRec.py文件并加入下列程序清单中的代码。
程序清单14-2 基于物品相似度的推荐引擎
def standEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0; ratSimTotal = 0.0
for j in range(n):
userRating = dataMat[user,j]
if userRating == 0: continue
#❶ 寻找两个用户都评级的物品
overLap = nonzero(logical_and(dataMat[:,item].A>0, dataMat[:,j].A>0))[0]
if len(overLap) == 0: similarity = 0
else: similarity = simMeas(dataMat[overLap,item], dataMat[overLap,j])
#print 'the %d and %d similarity is: %f' % (item, j, similarity)
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0: return 0
else: return ratSimTotal/simTotaldef recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
#❷ 寻找未评级的物品
unratedItems = nonzero(dataMat[user,:].A==0)[1]
if len(unratedItems) == 0: return 'you rated everything'
itemScores = []
for item in unratedItems:
estimatedScore = estMethod(dataMat, user, simMeas, item)
itemScores.append((item, estimatedScore))
#❸ 寻找前N个未评级物品
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[:N]
上述程序包含了两个函数。第一个函数是standEst(),用来计算在给定相似度计算方法的条件下,用户对物品的估计评分值。第二个函数是recommend(),也就是推荐引擎,它会调用standEst()函数。我们先讨论standEst()函数,然后讨论recommend()函数。
函数standEst()的参数包括数据矩阵、用户编号、物品编号和相似度计算方法。假设这里的数据矩阵为图14-1和图14-2的形式,即行对应用户、列对应物品。那么,我们首先会得到数据集中的物品数目,然后对两个后面用于计算估计评分值的变量进行初始化。接着,我们遍历行中的每个物品。如果某个物品评分值为0,就意味着用户没有对该物品评分,跳过了这个物品。该循环大体上是对用户评过分的每个物品进行遍历,并将它和其他物品进行比较。变量overLap给出的是两个物品当中已经被评分的那个元素❶。如果两者没有任何重合元素,则相似度为0且中止本次循环。但是如果存在重合的物品,则基于这些重合物品计算相似度。随后,相似度会不断累加,每次计算时还考虑相似度和当前用户评分的乘积。最后,通过除以所有的评分总和,对上述相似度评分的乘积进行归一化。这就可以使得最后的评分值在0到5之间,而这些评分值则用于对预测值进行排序。
函数recommend()产生了最高的N个推荐结果。如果不指定N的大小,则默认值为3。该函数另外的参数还包括相似度计算方法和估计方法。我们可以使用程序清单14-1中的任意一种相似度计算方法。此时我们能采用的估计方法只有一种选择,但是在下一小节中会增加另外一种选择。该函数的第一件事就是对给定的用户建立一个未评分的物品列表❷。如果不存在未评分物品,那么就退出函数;否则,在所有的未评分物品上进行循环。对每个未评分物品,则通过调用standEst()来产生该物品的预测得分。该物品的编号和估计得分值会放在一个元素列表itemScores中。最后按照估计得分,对该列表进行排序并返回❸。该列表是从大到小逆序排列的,因此其第一个值就是最大值。
接下来看看它的实际运行效果。在保存svdRec.py文件之后,在Python提示符下输入命令:
>>> reload(svdRec)
下面,我们调入了一个矩阵实例,可以对本章前面给出的矩阵稍加修改后加以使用。首先,调入原始矩阵:
>>> myMat=mat(svdRec.loadExData())该矩阵对于展示SVD的作用非常好,但是它本身不是十分有趣,因此我们要对其中的一些值进行更改:
>>> myMat[0,1]=myMat[0,0]=myMat[1,0]=myMat[2,0]=4
>>> myMat[3,3]=2现在得到的矩阵如下:
>>> myMat
matrix([[4, 4, 0, 2, 2],
[4, 0, 0, 3, 3],
[4, 0, 0, 1, 1],
[1, 1, 1, 2, 0],
[2, 2, 2, 0, 0],
[1, 1, 1, 0, 0],
[5, 5, 5, 0, 0]])好了,现在我们已经可以做些推荐了。我们先尝试一下默认的推荐:
>>> svdRec.recommend(myMat, 2)
[(2, 2.5000000000000004), (1, 2.0498713655614456)]这表明了用户2(由于我们从0开始计数,因此这对应了矩阵的第3行)对物品2的预测评分值为2.5,对物品1的预测评分值为2.05。下面我们就利用其他的相似度计算方法来进行推荐:
>>> svdRec.recommend(myMat, 2, simMeas=svdRec.ecludSim)
[(2, 3.0), (1, 2.8266504712098603)]
>>> svdRec.recommend(myMat, 2, simMeas=svdRec.pearsSim)
[(2, 2.5), (1, 2.0)]我们可以对多个用户进行尝试,或者对数据集做些修改来了解其给预测结果带来的变化。
这个例子给出了如何利用基于物品相似度和多个相似度计算方法来进行推荐的过程,下面我们介绍如何将SVD应用于推荐。
14.5.2 利用SVD提高推荐的效果
实际的数据集会比我们用于展示recommend()函数功能的myMat矩阵稀疏得多。图14-4就给出了一个更真实的矩阵的例子。
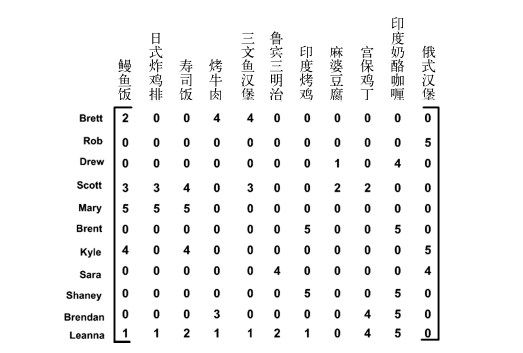
我们可以将该矩阵输入到程序中去,或者从下载代码中复制函数loadExData2()。下面我们计算该矩阵的SVD来了解其到底需要多少维特征。
>>>from numpy import linalg as la
>>> U,Sigma,VT=la.svd(mat(svdRec.loadExData2()))
>>> Sigma
array([ 1.38487021e+01, 1.15944583e+01, 1.10219767e+01,
5.31737732e+00, 4.55477815e+00, 2.69935136e+00,
1.53799905e+00, 6.46087828e-01, 4.45444850e-01,
9.86019201e-02, 9.96558169e-17])接下来我们看看到底有多少个奇异值能达到总能量的90%。首先,对Sigma中的值求平方:
>>> Sig2=Sigma**2再计算一下总能量:
>>> sum(Sig2)
541.99999999999932再计算总能量的90%:
>>> sum(Sig2)*0.9
487.79999999999939然后,计算前两个元素所包含的能量:
>>> sum(Sig2[:2])
378.8295595113579该值低于总能量的90%,于是计算前三个元素所包含的能量:
>>> sum(Sig2[:3])
500.50028912757909该值高于总能量的90%,这就可以了。于是,我们可以将一个11维的矩阵转换成一个3维的矩阵。下面对转换后的三维空间构造出一个相似度计算函数。我们利用SVD将所有的菜肴映射到一个低维空间中去。在低维空间下,可以利用前面相同的相似度计算方法来进行推荐。我们会构造出一个类似于程序清单14-2中的standEst()函数。打开svdRec.py文件并加入如下程序清单中的代码。
程序清单14-3 基于SVD的评分估计
def svdEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0; ratSimTotal = 0.0
U,Sigma,VT = la.svd(dataMat)
#❶ 建立对角矩阵
Sig4 = mat(eye(4)*Sigma[:4])
#❷ 构建转换后的物品
xformedItems = dataMat.T * U[:,:4] * Sig4.I
for j in range(n):
userRating = dataMat[user,j]
if userRating == 0 or j==item: continue
similarity = simMeas(xformedItems[item,:].T,xformedItems[j,:].T)
print 'the %d and %d similarity is: %f' % (item, j, similarity)
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0: return 0
else: return ratSimTotal/simTotal上述程序中包含有一个函数svdEst()。在recommend()中,这个函数用于替换对standEst()的调用,该函数对给定用户给定物品构建了一个评分估计值。如果将该函数与程序清单14-2中的standEst()函数进行比较,就会发现很多行代码都很相似。该函数的不同之处就在于它在第3行对数据集进行了SVD分解。在SVD分解之后,我们只利用包含了90%能量值的奇异值,这些奇异值会以NumPy数组的形式得以保存。因此如果要进行矩阵运算,那么就必须要用这些奇异值构建出一个对角矩阵❶。然后,利用U矩阵将物品转换到低维空间中❷。
对于给定的用户,for循环在用户对应行的所有元素上进行遍历。这和standEst()函数中的for循环的目的一样,只不过这里的相似度计算是在低维空间下进行的。相似度的计算方法也会作为一个参数传递给该函数。然后,我们对相似度求和,同时对相似度及对应评分值的乘积求和。这些值返回之后则用于估计评分的计算。for循环中加入了一条print语句,以便能够了解相似度计算的进展情况。如果觉得这些输出很累赘,也可以将该语句注释掉。
接下来看看程序的执行效果。将程序清单14-3中的代码输入到文件svdRec.py中并保存之后,在Python提示符下运行如下命令:
>>> reload(svdRec)
>>> svdRec.recommend(myMat, 1, estMethod=svdRec.svdEst)
The 0 and 3 similarity is 0.362287.
.
.
.
The 9 and 10 similarity is 0.497753.
[(6, 3.387858021353602), (8, 3.3611246496054976), (7, 3.3587350221130028)]
下面再尝试另外一种相似度计算方法:
>>> svdRec.recommend(myMat, 1, estMethod=svdRec.svdEst,
simMeas=svdRec.pearsSim)
The 0 and 3 similarity is 0.116304.
.
.
.
The 9 and 10 similarity is 0.566796.
[(6, 3.3772856083690845), (9, 3.3701740601550196), (4, 3.3675118739831169)]我们还可以再用其他多种相似度计算方法尝试一下。感兴趣的读者可以将这里的结果和前面的方法(不做SVD分解)进行比较,看看到底哪个性能更好。
14.5.3 构建推荐引擎面临的挑战
本节的代码很好地展示出了推荐引擎的工作流程以及SVD将数据映射为重要特征的过程。在撰写这些代码时,我尽量保证它们的可读性,但是并不保证代码的执行效率。一个原因是,我们不必在每次估计评分时都做SVD分解。对于上述数据集,是否包含SVD分解在效率上没有太大的区别。但是在更大规模的数据集上,SVD分解会降低程序的速度。SVD分解可以在程序调入时运行一次。在大型系统中,SVD每天运行一次或者频率更低,并且还要离线运行。
推荐引擎中还存在其他很多规模扩展性的挑战性问题,比如矩阵的表示方法。在上面给出的例子中有很多0,实际系统中0的数目更多。也许,我们可以通过只存储非零元素来节省内存和计算开销?另一个潜在的计算资源浪费则来自于相似度得分。在我们的程序中,每次需要一个推荐得分时,都要计算多个物品的相似度得分,这些得分记录的是物品之间的相似度。因此在需要时,这些记录可以被另一个用户重复使用。
在实际中,另一个普遍的做法就是离线计算并保存相似度得分。
推荐引擎面临的另一个问题就是如何在缺乏数据时给出好的推荐。这称之为冷启动(cold-start)问题,处理起来十分困难。这个问题的另一个说法是,用户不会喜欢一个无效的物品,而用户不喜欢的物品又无效。1如果推荐只是一个可有可无的功能,那么上述问题倒也不大。但是如果应用的成功与否和推荐的成功与否密切相关,那么问题就变得相当严重了。
1 也就是说,在协同过滤场景下,由于新物品到来时由于缺乏所有用户对其的喜好信息,因此无法判断每个用户对其的喜好。而无法判断某个用户对其的喜好,也就无法利用该商品。——译者注.
冷启动问题的解决方案,就是将推荐看成是搜索问题。在内部表现上,不同的解决办法虽然有所不同,但是对用户而言却都是透明的。为了将推荐看成是搜索问题,我们可能要使用所需要推荐物品的属性。在餐馆菜肴的例子中,我们可以通过各种标签来标记菜肴,比如素食、美式BBQ、价格很贵等等。同时,我们也可以将这些属性作为相似度计算所需要的数据,这被称为基于内容(content-based)的推荐。可能,基于内容的推荐并不如我们前面介绍的基于协同过滤的推荐效果好,但我们拥有它,这就是个良好的开始。





本书评论