14.1 SVD的应用
奇异值分解
优点:简化数据,去除噪声,提高算法的结果。
缺点:数据的转换可能难以理解。
适用数据类型:数值型数据。
利用SVD实现,我们能够用小得多的数据集来表示原始数据集。这样做,实际上是去除了噪声和冗余信息。当我们试图节省空间时,去除噪声和冗余信息就是很崇高的目标了,但是在这里我们则是从数据中抽取信息。基于这个视角,我们就可以把SVD看成是从有噪声的数据中抽取相关特征。如果这一点听来奇怪,也不必担心,我们后面会给出若干SVD应用的场景和方法,解释它的威力。
首先,我们会介绍SVD是如何通过隐性语义索引应用于搜索和信息检索领域的。然后,我们再介绍SVD在推荐系统中的应用。
14.1.1 隐性语义索引
SVD的历史已经超过上百个年头,但是最近几十年随着计算机的使用,我们发现了其更多的使用价值。最早的SVD应用之一就是信息检索。我们称利用SVD的方法为隐性语义索引(Latent Semantic Indexing,LSI)或隐性语义分析(Latent Semantic Analysis,LSA)。
在LSI中,一个矩阵是由文档和词语组成的。当我们在该矩阵上应用SVD时,就会构建出多个奇异值。这些奇异值代表了文档中的概念或主题,这一特点可以用于更高效的文档搜索。在词语拼写错误时,只基于词语存在与否的简单搜索方法会遇到问题。简单搜索的另一个问题就是同义词的使用。这就是说,当我们查找一个词时,其同义词所在的文档可能并不会匹配上。如果我们从上千篇相似的文档中抽取出概念,那么同义词就会映射为同一概念。
14.1.2 推荐系统
SVD的另一个应用就是推荐系统。简单版本的推荐系统能够计算项或者人之间的相似度。更先进的方法则先利用SVD从数据中构建一个主题空间,然后再在该空间下计算其相似度。考虑图14-1中给出的矩阵,它是由餐馆的菜和品菜师对这些菜的意见构成的。品菜师可以采用1到5之间的任意一个整数来对菜评级。如果品菜师没有尝过某道菜,则评级为0。
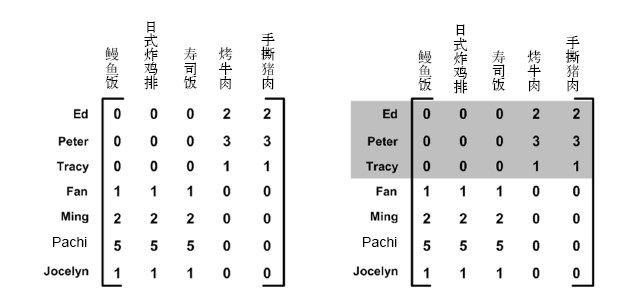
我们对上述矩阵进行SVD处理,会得到两个奇异值(读者如果不信可以自己试试)。因此,就会仿佛有两个概念或主题与此数据集相关联。我们看看能否通过观察图中的0来找到这个矩阵的具体概念。观察一下右图的阴影部分,看起来Ed、Peter和Tracy对“烤牛肉”和“手撕猪肉”进行了评级,同时这三人未对其他菜评级。烤牛肉和手撕猪肉都是美式烧烤餐馆才有的菜,其他菜则在日式餐馆才有。
我们可以把奇异值想象成一个新空间。与图14-1中的矩阵给出的五维或者七维不同,我们最终的矩阵只有二维。那么这二维分别是什么呢?它们能告诉我们数据的什么信息?这二维分别对应图中给出的两个组,右图中已经标示出了其中的一个组。我们可以基于每个组的共同特征来命名这二维,比如我们得到的美式BBQ和日式食品这二维。
如何才能将原始数据变换到上述新空间中呢?下一节我们将会进一步详细地介绍SVD,届时将会了解到SVD是如何得到U和Vᵀ两个矩阵的。Vᵀ矩阵会将用户映射到BBQ/日式食品空间去。类似地,U矩阵会将餐馆的菜映射到BBQ/日式食品空间去。真实的数据通常不会像图14-1中的矩阵那样稠密或整齐,这里如此只是为了便于说明问题。
推荐引擎中可能会有噪声数据,比如某个人对某些菜的评级就可能存在噪声,并且推荐系统也可以将数据抽取为这些基本主题。基于这些主题,推荐系统就能取得比原始数据更好的推荐效果。在2006年末,电影公司Netflix曾经举办了一个奖金为100万美元的大赛,这笔奖金会颁给比当时最好系统还要好10%的推荐系统的参赛者。最后的获奖者就使用了SVD¹。
下一节将介绍SVD的一些背景材料,接着给出利用Python的NumPy实现SVD的过程。然后,我们将进一步深入讨论推荐引擎。当对推荐引擎有相当的了解之后,我们就会利用SVD构建一个推荐系统。
SVD是矩阵分解的一种类型,而矩阵分解是将数据矩阵分解为多个独立部分的过程。接下来我们首先介绍矩阵分解。
- Yehuda Koren, “The BellKor Solution to the Netflix Grand Prize,” August 2009;http://www.netflixprize.com/assets/GrandPrize2009_BPC_BellKor.pdf.





本书评论