
6.3 探索传播性的特征
我们在这里收集的故事代表了在过去一年中,大约 500 个传播度最高的作品。我们将尝试解构这些文章来寻找使它们广为流传的共同特征。先从图像数据开始。
6.3.1 探索图像数据
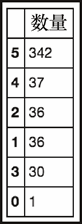
让我们来看看每个故事中包含的图片数量。我们运行一个数值统计,然后绘制图表。
dfc['img_count'].value_counts().to_frame('count')
上述代码生成图 6-13 的输出。
现在,让我们绘制这些信息。
fig, ax = plt.subplots(figsize=(8,6))
y = dfc['img_count'].value_counts().sort_index()
x = y.sort_index().index
plt.bar(x, y, color='k', align='center')
plt.title('Image Count Frequency', fontsize=16, y=1.01)
ax.set_xlim(-.5,5.5)
ax.set_ylabel('Count')
ax.set_xlabel('Number of Images')
上述代码生成图 6-14 的输出。
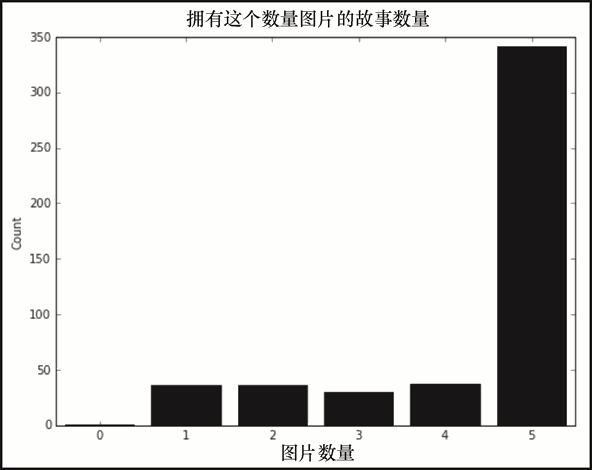
图 6-14 中的数字已经令人惊讶了。绝大多数的故事里都有五张图片,而只有一张甚至没有图片的故事是相当罕见的。
因此,我们发现人们倾向于分享包含大量图片的内容。下面来看看这些图像中最常见的颜色。
mci = dfc['main_hex'].value_counts().to_frame('count')
mci
上述代码生成图 6-15 的输出。

图 6-15 看上去不是很有帮助,因为我们并不理解 HEX 值代表什么颜色。不过,这里可以使用 pandas 中的一个新功能,称为 conditional formatting,它可以帮助我们。
mci['color'] = ' '
def color_cells(x):
return 'background-color: ' + x.index
mci.style.apply(color_cells, subset=['color'], axis=0)
mci
上述代码生成图 6-16 的输出。
这当然很有帮助。我们可以看到一些颜色,例如淡蓝色、黑色和绿色(这里是以灰度渲染的),但颜色的粒度是如此之细,总共有超过 450 个唯一的值。让我们使用一点聚类的技术将其转化成更容易管理的范围。由于这里有每个颜色的 RBG 值,我们可以创建一个三维空间,并使用 K-means 算法来聚集它们。我不会在这里讨论算法的细节,不过它是一个相当简单的迭代算法,它通过测量每个数据点到到中心点的距离来生成聚类,并迭代式地重复该过程。算法需要我们选择 k 的值,或者说是期望的聚类数量。由于 RGB 值的范围是从 0 到 256,我们将使用 256 的平方根,也就是 16。如此一来,我们可获得一个可管理的数量,同时保留调色板的特点。
我们首先将 RGB 值拆分成单独的列,如下所示。
defget_csplit(x):
try:
return x[0], x[1], x[2]
except:
return None, None, None
dfc['reds'], dfc['greens'], dfc['blues'] =
zip(*dfc['main_rgb'].map(get_csplit))
接下来,我们将使用它来运行我们的 K-means 模型并获取中心值。
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=16)
clf.fit(dfc[['reds', 'greens', 'blues']].dropna())
clusters = pd.DataFrame(clf.cluster_centers_, columns=['r', 'g', 'b'])
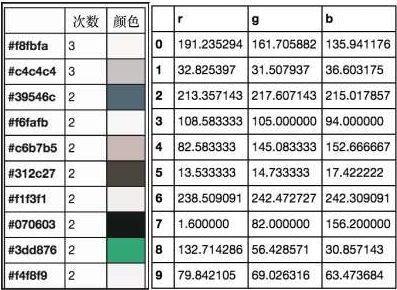
clusters
上述代码生成图 6-17 的输出。
现在,从每页的首张图片中,我们获得了 16 个最受欢迎的主流颜色。接下来使用 pandas的 DataFrame.style()方法以及我们刚刚创建的为单元格填色的函数,来看看这些主流颜色长什么样子。这里需要将索引设置为等于三列中十六进制值那列,以使用我们的color_cells 函数,具体如下。
def hexify(x):
rgb = [round(x['r']), round(x['g']), round(x['b'])]
hxc = mpc.rgb2hex([(x/255) for x in rgb])
return hxc
clusters.index = clusters.apply(hexify, axis=1)
clusters['color'] = ' '
clusters.style.apply(color_cells, subset=['color'], axis=0)
上述代码生成图 6-18 的输出。
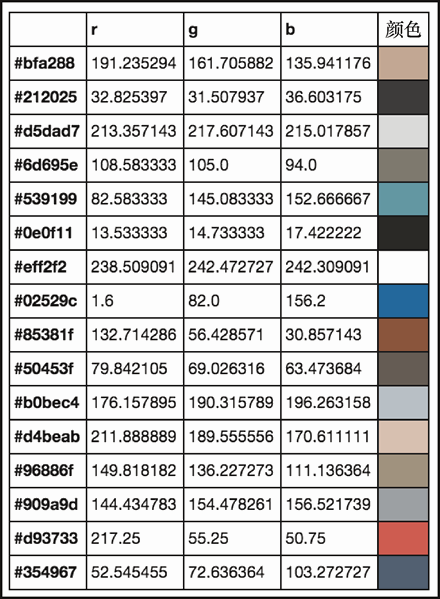
那么,你看到了。这些是广为流传的内容中最常见的颜色(至少在第一张图像中)。比预期更单调一点:虽然有一些蓝色和红色,但多数还是棕色这种灰蒙蒙的色调。
现在让我们继续检视故事的标题。
6.3.2 探索标题
我们将从创建一个函数开始,使用它来检查最常见的元组。将其设置好之后,将来在正文上也可以使用它。
from nltk.util import ngrams
from nltk.corpus import stopwords
import re
def get_word_stats(txt_series, n, rem_stops=False):
txt_words = []
txt_len = []
for w in txt_series:
if w is not None:
if rem_stops == False:
word_list = [x for x in ngrams(re.findall('[a-z0-9']+', w.lower()), n)]
else:
word_list = [y for y in ngrams([x for x in re.findall('[a-z0-9']+', w.lower())\
if x not in stopwords.words('english')], n)]
word_list_len = len(list(word_list))
txt_words.extend(word_list)
txt_len.append(word_list_len)
return pd.Series(txt_words).value_counts().to_frame('count'), pd.DataFrame(txt_len, columns=['count'])
这里有很多要解释,所以让我们逐步分析。我们创建了一个函数并接收Series、一个整数和一个布尔值作为输入。整数决定了我们将用于n元语法解析的n,而布尔值决定我们是否排除停用词。函数返回每行 ①的元组 ②数目和每个元组的频率。
(译者注:①也就是每篇文章。②这里的元组是指 n 元语法生成的元组。)
下面让我们在标题上运行这个函数,暂时保持停用词。先从一元语法开始。
hw,hl = get_word_stats(dfc['title'], 1, 0)
hl
上述代码生成图 6-19 的输出。
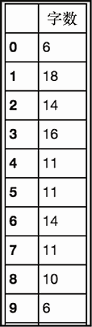
现在,每个标题的字数都有了,让我们来看看其统计信息。
hl.describe()
上述代码生成图 6-20 的输出。
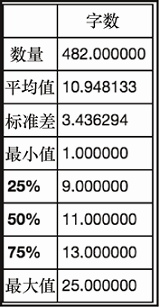
我们可以看到传播广泛的故事其标题长度的中位数恰好在 11 个字。让我们来看看最常用的那些单词,如图 6-21 所示。
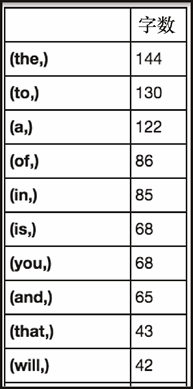
这种信息不是很有价值,但它符合我们的期望。让我们来看看二元语法的同类信息。
hw,hl = get_word_stats(dfc['title'], 2, 0)
hw
上述代码生成图 6-22 的输出。
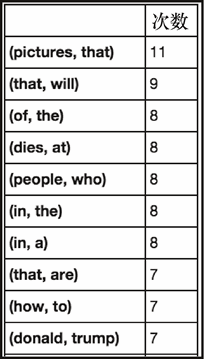
这肯定是更有趣。从中可以看到标题中的某些部分反复出现。最突出的两个是(donald, trump①)和(die,at)。Trump是有道理的,因为他做了一些抓眼球的声明,但令人惊讶的是看到关于死亡的标题。快速浏览过去一年的头条新闻,发现一些知名人物最近去世了,所以这也有一定的意义。
(①译者注:Donald Trump 是美国 2016 年总统大选的候选人之一。)
现在让我们去掉停用词,再次运行代码。
hw,hl = get_word_stats(dfc['title'], 2, 1)
hw
上述代码生成图 6-23 的输出。
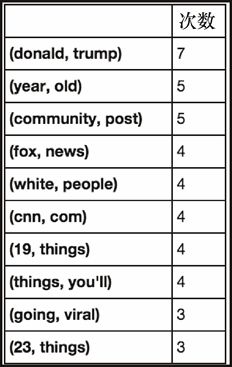
再次,我们看到了许多期待的东西。看起来如果我们改变数字的解析方式(用单个标识符,例如[number],来替换每一个数字),可能会看到更多这样的元组排名靠前。如果你愿意尝试,我会把这个练习留给你。
让我们再来看看三元语法。
hw,hl = get_word_stats(dfc['title'], 3, 0)
上述代码生成图 6-24 的输出。
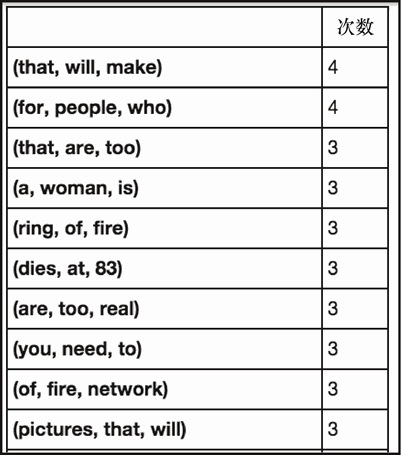
看来,元组包括的词语越多,标题越来越像经典的 BuzzFeed 风格。让我们看看事实是否如此。我们还没看过哪个网站产生的病毒式传播故事最多,这里通过图表来看看BuzzFeed是否领先。
dfc['site'].value_counts().to_frame()
上述代码生成图 6-25 的输出。
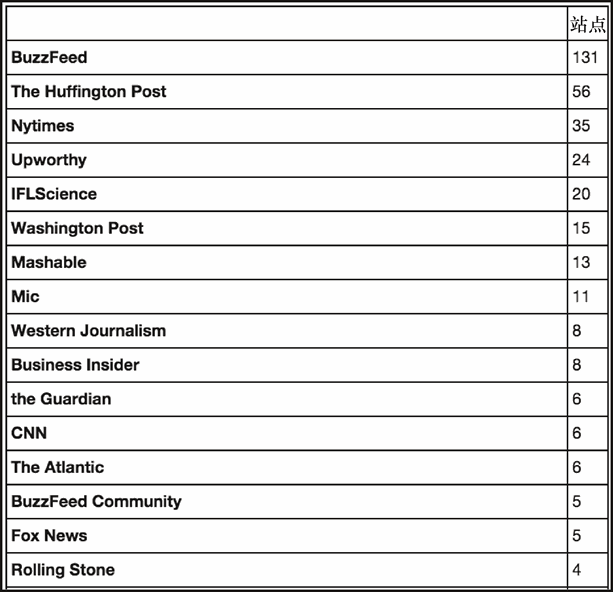
我们可以清楚地看到,BuzzFeed 在名单中占主导地位,和第二位 Huffington Post 拉开了明显的距离,而这个网站也有 Jonah Peretti 的参与。看起来研究病毒式传播的科学可以产生巨大的收益。
到目前为止,我们已经检视了图像和标题,接下来继续观察故事的正文。
6.3.3 探索故事的内容
在上一节中,我们创建了一个函数来发现故事标题中常见的 n 元语法,现在应用这个函数来探索故事的完整内容。
我们将这样开始:去除停用词,使用二元组。因为与故事主体相比,标题是非常短小的,所以包含停止词是有一定意义的,但在故事正文中,通常去除它们是更合理的做法。
hw,hl = get_word_stats(dfc['text'], 2, 1)
hw
上述代码生成图 6-26 的输出。
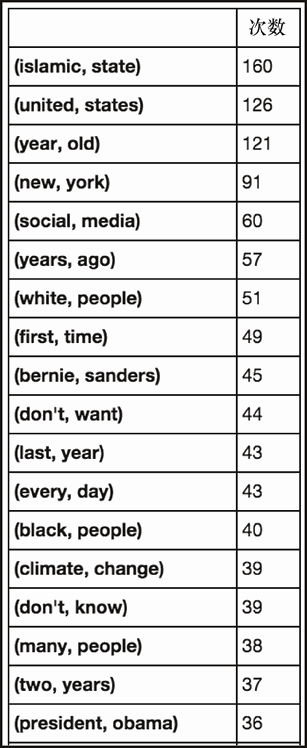
有趣的是,我们在标题中看到的轻松愉快的元组在这里完全消失了。正文充满了关于恐怖主义、政治和种族关系的讨论。
标题的内容是轻松愉快的,而正文的内容却是黑暗而富有争议的,这怎么可能?我的猜测是“13 Puppies Who Look Like Elvis”比“The History of US Race Relations”这类文章的字数要少的多 ①。
(①译者注:作者的意思是标题通常长度都非常短,而正文的长度相互之间差异很大,所以造成了统计结果迥然。)
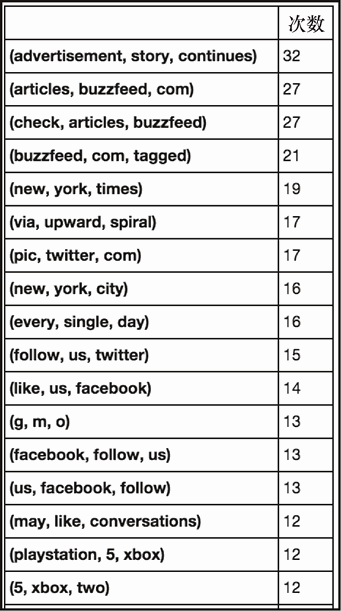
让我们再来看看一个实验。这次将评估故事正文的三元组。
hw,hl = get_word_stats(dfc['text'], 3, 1)
hw
上述代码生成图 6-27 的输出。
我们似乎突然进入了广告和社交活动的领域。有了这些,让我们继续构建内容评分的预测模型。





本书评论