
5.4 支持向量机
我们将在本章中使用一个新的分类器,即线性支持向量机。支持向量机的算法使用“最大边缘超平面”,试图对数据点进行线性分离并归类。这是口头上的描述,下面让我们来看看这究竟是什么意思。
假设有两类数据,而我们想用一条线来分隔它们(这里只处理两个特征或维度)。放置这条线最有效的方法是什么?如图 5-14 所示。
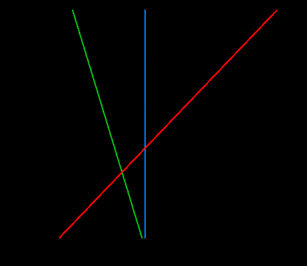
在图 5-14 中,线 H1 不能有效地区分两个类,所以我们可以不考虑这条。线 H2能够清楚地区分它们,但是 H3 确保了最大的空余边缘。这意味着该线在两个类间最近点的当中,而这些点被称为支持向量。它们也可以看作是图 5-15 中的虚线。
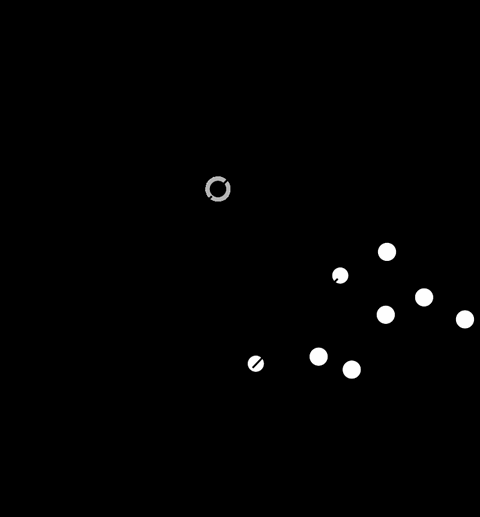
但是,如果数据不能被如此清晰地分到各个类中,那又该怎么办?如果点之间有重叠呢?在这种情况下也有办法。一种是使用所谓的 softmargin SVM。这个公式仍然使边缘最大化,但是有一个权衡的策略:如果点错误地落在边缘的某一侧,那么对这样的点进行惩罚。另一种是使用所谓的 kernel 技巧。这种方法将数据转换到更高维度的空间,让这些数据可以被线性的分割。
如图 5-16 所示,其中有两个类,不能用单线性平面分开。

不过,内核的某种实现可以将图 5-16 的图像映射到更高维度,如图 5-17 所示。这允许数据被线性分割。
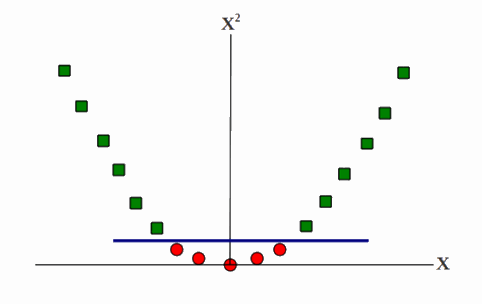
我们已经将一维特征空间映射到二维特征空间。该映射简单地取每个 x 值并将其映射到 x,x。这个变换允许我们添加线性分割的平面。
介绍完这些,现在让我们将 tf-idf 矩阵传送给 SVM 模型。
fromsklearn.svm import LinearSVC
clf = LinearSVC()
model = clf.fit(tv, df['wanted'])
这个 tv 参数是我们的矩阵,而 df ['wanted']是我们的标签列表。记住标签是'y'或'n',表示我们是否对文章感兴趣。一旦运行完成,模型就训练完毕了。
本章中尚未进行的一个步骤就是正式地评估我们的模型。你总是应该保留一份数据来评估模型,但由于我们需要不断更新模型,并且每天评估它,在这一章我们将跳过这一步。
记得这通常是一个糟糕的想法 ①。
现在让我们继续建立每日的新闻源。
①译者注:作者的原意是通常情况下,不应该跳过评估的环节。





本书评论