15.3 在Amazon网络服务上运行Hadoop程序
如果要在100台机器上同时运行MapReduce作业,那么就需要找到100台机器,可以采取购买的方式,或者从其他地方租用。Amazon公司通过Amazon网络服务(Amazon Web Services,AWS,http://aws.amazon.com/),将它的大规模计算基础设施租借给开发者。
AWS提供网站、流媒体、移动应用等类似的服务,其中存储、带宽和计算能力按价收费,用户可以仅为使用的部分按时缴费,无需长期的合同。这种仅为所需买单的形式,使得AWS很有诱惑力。例如,当你临时需要使用1000台机器时,可以在AWS上申请并做几天实验。几天后当你发现当前的方案不可行,就即时关掉它,不需要再为这1000台机器支出任何费用。本节首先介绍几个目前在AWS上可用的服务,然后介绍AWS上运行环境的搭建方法,最后给出了一个在AWS上运行Hadoop流作业的例子。
15.3.1 AWS上的可用服务
AWS上提供了大量可用的服务。在行内人士看来,这些服务的名字很容易理解,而在新手看来则比较神秘。目前AWS还在不停地演变,也在不断地添加一些新的服务。下面给出一些基本的稳定的服务。
S3 —— 简单存储服务,用于在网络上存储数据,需要与其他AWS产品配合使用。用户可以租借一组存储设备,并按照数据量大小及存储时间来付费。
EC2 —— 弹性计算云(Elastic Compute Cloud),是使用服务器镜像的一项服务。它是很多AWS系统的核心,通过配置该服务器可以运行大多数的操作系统。它使得服务器可以以镜像的方式在几分钟内启动,用户可以创建、存储和共享这些镜像。EC2中“弹性”的由来是该服务能够迅速便捷地根据需求增加服务的数量。
Elastic MapReduce(EMR) —— 弹性MapReduce,它是AWS的MapReduce实现,搭建于稍旧版本的Hadoop之上(Amazon希望保持一个稳定的版本,因此做了些修改,没有使用最新的Hadoop)。它提供了一个很好的GUI,并简化了Hadoop任务的启动方式。用户不需要因为集群琐碎的配置(如Hadoop系统的文件导入或Hadoop机器的参数修改)而多花心思。在EMR上,用户可以运行Java作业或Hadoop流作业,本书将对后者进行介绍。
另外,很多其他服务也是可用的,本书将着重介绍EMR。下面还需要用到S3服务,因为EMR需要从S3上读取文件并启动安装Hadoop的EC2服务器镜像。
15.3.2 开启Amazon网络服务之旅
使用AWS之前,首先需要创建AWS账号。开通AWS账号还需要一张信用卡,后面章节中的练习将花费大约1美元的费用。打开http://aws.amazon.com/可以看到如图15-2所示的界面,在右上部有“现在注册”(Sign Up Now)按钮。点击后按照指令进行,经过三个页面就可以完成AWS的注册。 注意,你需要注册S3、EC2和EMR三项服务。
![[http:aws.amazon.com/]页面右上部给出了注册AWS账号的按钮](https://img.211cn.ca/books/3142/291.jpg)
aws.amazon.com/]页面右上部给出了注册AWS账号的按钮
建立了AWS账号后,登录进AWS控制台并点击EC2、Elastic MapReduce和S3选项卡,确认你是否已经注册了这些服务。如果你没有注册某项服务,会看到如图15-3所示的提示。
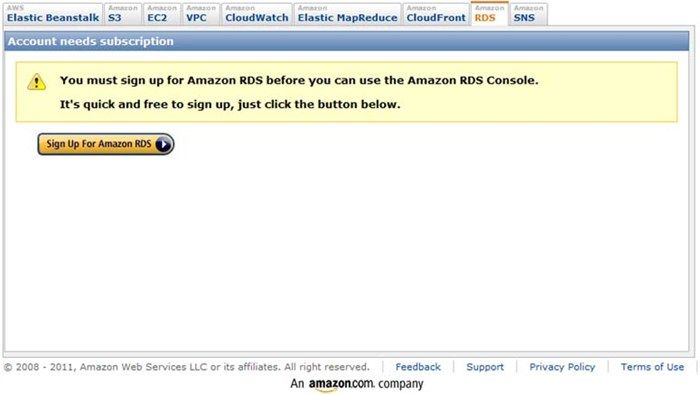
这样就做好了在Amazon集群上运行Hadoop作业的准备,下一节将介绍在EMR上运行Hadoop的具体流程。
15.3.3 在EMR上运行Hadoop作业
注册了所需的Amazon服务之后,登录AWS控制台并点击S3选项卡。这里需要将文件上传,以便AWS能找到我们提供的文件。
1. 首先需要创建一个新的bucket(可以将bucket看做是一个驱动器)。例如,创建了一个叫做rustbucket的bucket。注意,bucket的名字是唯一的,所有用户均可使用。你应当为自己的bucket创建独特的名字。
2. 然后创建两个文件夹:mrMeanCode和mrMeanInput。将之前用Python编写的MapReduce代码上传到mrMeanCode,另一个目录mrMeanInput用于存放Hadoop作业的输入。
3. 在已创建的bucket中(如rustbucket)上传文件inputFile.txt到mrMeanInput目录。
4. 将文件mrMeanMapper.py和mrMeanReducer.py上传到mrMeanCode目录。这样就完成了全部所需文件的上传,也做好了在多台机器上启动第一个Hadoop作业的准备。
5. 点击Elastic MapReduce选项卡,点击“创建新作业流”(Create New Job Flow)按钮,并将作业流命名为mrMean007。屏幕上可以看到如图15-4所示的页面,在下方还有两个复选框和一个下拉框,选择“运行自己的应用程序”(Run Your Own Application)按钮并点击“继续”(Continue)进入到下一步。
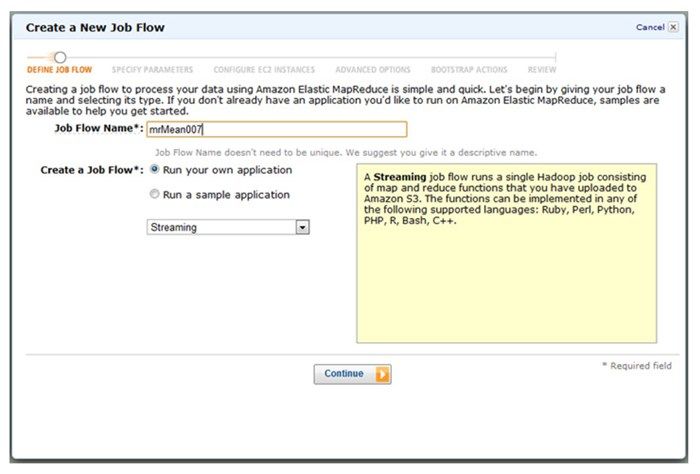
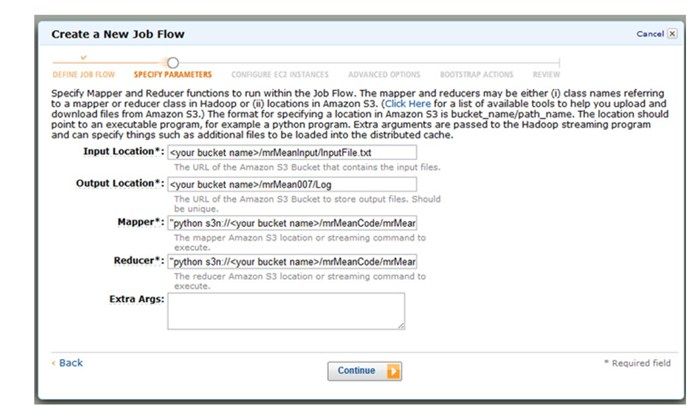
6. 在这一步需要设定Hadoop的输入参数。如果这些参数设置错误,作业将会执行失败。在“指定参数”(Specify Parameters)页面的对应字段上输入下面的内容:
Input Location*:
7. 下一个页面需要设定EC2的服务器镜像,这里将设定用于存储数据的服务器数量,默认值是2,可以改成1。你也可以按需要改变EC2服务器镜像的类型,可以申请一个大内存高运算能力的机器(当然也花费更多)。实际上,大的作业经常在大的服务器镜像上运行,详见http://aws.amazon.com/ec2/#instance。本节的简单例子可以选用很小的机器。本页面如图15-6所示,点击“继续”(Continue)。
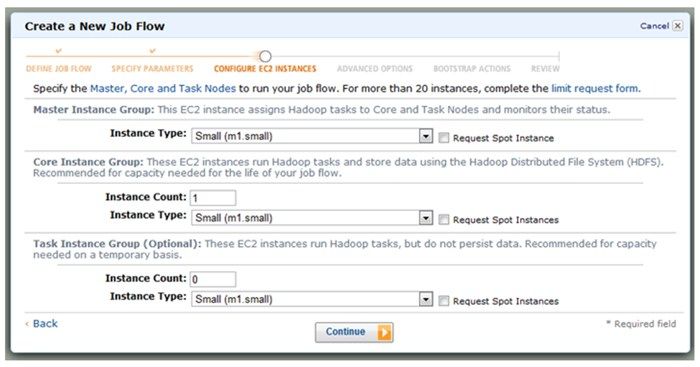
和服务器数量
8. 下一个是“高级选项”(Advanced Options)页面,可以设定有关调试的一些选项。务必打开日志选项,在“亚马逊S3日志路径”(Amazon S3 Log Path)里添加s3n://
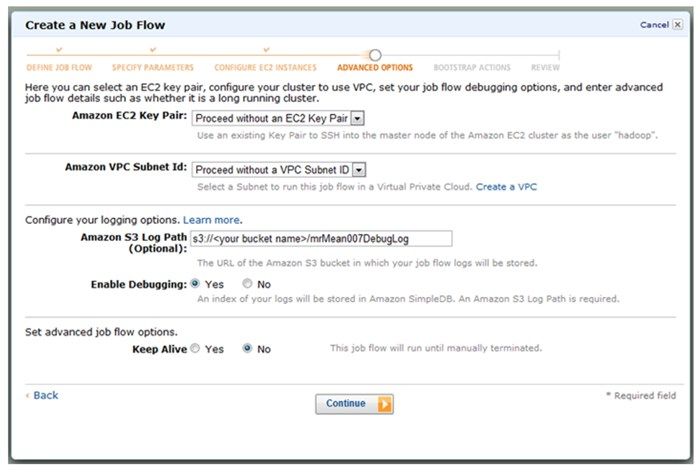
业失败还可以设定登录服务器所需的登录密钥。如果想检查代码的运行环境,登录服务器再查看是个很好的办法
9. 关键的设置已经完成,可以在接下来的引导页面使用默认的设定,一直点“下一步”(Next)到查看(Review)页面。检查一下所有的配置是否正确,然后点击底部的“创建作业流”(Create Job Flow)按钮。这样新任务就创建好了,在下一个页面点击“关闭”(Close)按钮将返回EMR控制台。
当作业运行的时候,可以在控制台看到其运行状态。读者不必担心运行这样一个小作业花费了这么多时间,因为这里包含了新的服务器镜像的配置。最终页面如图15-8所示(可能你那里不会有这么多的失败作业)。
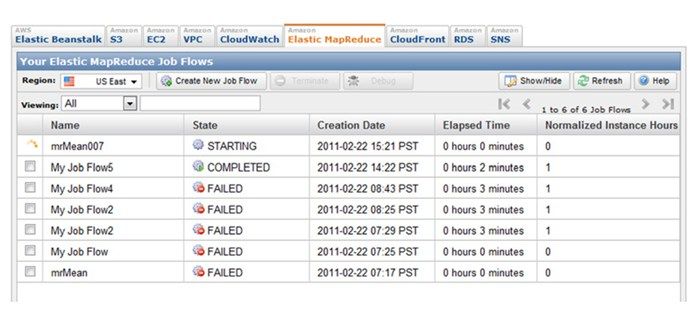
新建的任务将在开始运行几分钟之后完成,可以通过点击控制台顶端的S3选项卡来观察S3的输出。选中S3控制台后,点击之前创建的bucket(本例中是rustbucket)。在这个bucket里应该可以看到一个mrMean007Log目录。双击打开该目录,可以看到一个文件part-00000,该文件就是reducer的输出。双击下载该文件到本地机器上,用文本编辑器打开该文件,结果应该是这样的:
100 0.509570 0.344439这个结果与单机上用管道得到的测试结果一样,所以该结果是正确的。如果结果不正确,应当怎样找到问题所在呢?退回到EMR选项卡,点击“已经完成的任务”(Completed Job),可以看到“调试”(Debug)按钮,上面还有一个绿色小昆虫的动画。点击该按钮将打开调试窗口,可以访问不同的日志文件。另外,点击“控制器”(Controller)超链接,可以看到Hadoop命令和Hadoop版本号。
现在我们已经运行了一个Hadoop流作业,下面将介绍如何在Hadoop上执行机器学习算法。MapReduce可以在多台机器上运行很多程序,但这些程序需要做一些修改。
不使用AWS
如果读者不希望使用信用卡,或者怕泄露自己的信用卡信息,也能在本地机器上运行同样的作业。下面的步骤假定你已经安装了
Hadoop(http://hadoop.apache.org/common/docs/stable/#Getting+Started)。
1. 将文件复制到HDFS: hadoop fs -copyFromLocal inputFile.txt mrmean-i
2. 启动任务:
hadoop jar $HADOOP_HOME/contri b/streaming/hadoop-0.20.2-stream- ing.jar - input mrmean-i -output mrmean-o -mapper "python mrMeanMap- per.py" -reducer "python mrMeanReducer.py"
3. 观察结果:
hadoop fs -cat mrmean-o/part-00000
4. 下载结果:
hadoop fs -copyToLocal mrmean-o/part-00000 .
完成





本书评论