
第六节 分布式互联网协议
一、去中心化分布式思维
我们生活在互联网时代,现今互联网架构越来越难处理几十亿个互联用户的需求。如今用中心化的服务器架构来提供数据存取服务,其成本高昂且效率低下。数据中心消耗了全球1.1%~1.5%的电力(并且以每年60%的速度增长)。每个星期都会出现的关于用户账号和密码被盗的新闻,已经证明在这种CS架构(服务器+客户端)下,用户资料的绝对安全几乎是不可能实现的。数据中心成了互联网的瓶颈,传统的HTTP协议也成为阻滞互联网进一步发展的障碍。
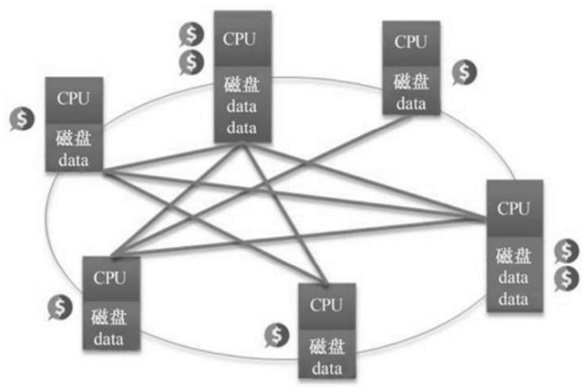
为了满足未来互联网的发展需要,通过传统P2P技术和创新比特币技术相结合,一种颠覆式的全分布式P2P网络概念浮出水面,该网络提倡共同的参与、透明的开放、平等的分享、公平的激励理念,在P2P网络环境中,成千上万台彼此连接的计算机都处于对等的地位,整个网络不依赖专用的集中服务器,如图2.49所示。网络中的每一台计算机既能充当网络服务的请求者,又对其他计算机的请求做出响应,提供资源和服务,系统能根据用户提供的资源多少奖励相应的数字货币。
我们在这一节将会通过三个基于区块链理念的分布式互联网协议应用来探索互联网的新组织形式。
二、IPFS点对点协议(Inter Planetary File System)
1.HTTP做错了什么
超文本传输协议(HTTP)已经在全球信息协议中一统山河,对信息的发布与传播设置了很多规范。没有HTTP的生活几乎无法想象:HTTP将发布信息的成本几乎降到了零,这一创新粉碎了对信息从上而下的传播渠道管控,借助信息流动与更简单的信息发布方式,现在人人都能发布与访问包括经济、政治与文化领域(音乐、创意、视频、新闻、游戏等所有一切)的信息,HTTP让我们的文化整体水平获得了提高。
人们永远都会继续热爱着HTTP,它的确是史上最伟大、最重要的发明之一。
不过尽管HTTP成就斐然,在传播与维护人类知识方面,它作为基础差得不是一点半点,而是几乎全无招架之力。HTTP传播信息的方式从根本上是有缺陷的,无论进行再多的性能调整,打破CASSL,再或者其他什么都难以修复这一问题。
HTTP/2(超文本传输协议第二版)是可喜的进步,不过它只能算针对一个有年头的技术所进行的保守更新。想要让网络获得更好的未来,我们不止需要一个HTTP的更新版,更需要一个新的基础。而根据网络空间的管理模式,也就是说,我们需要一个新的协议。笔者强烈建议使用IPFS打造这个新协议。
(1)HTTP脆弱不堪。
这是世界上的第一台HTTP网络服务器,属于Tim Berners-Lee,是他在欧洲核子研究组织(CERN)工作时使用的一台NeXT计算机,如图2.50所示。

机器上贴了一个警告标签:“这台计算机是服务器,请不要关机!!”
之所以不能关机,是因为其他服务器上的网站与之相连。一旦它们连接到这台计算机,就会依赖它而继续存在。如果关机,连接就会中断。如果无法从同一个位置继续访问这台机器,就会发生更糟的事情:站点之间的联系永久中断,内容就永远无法再被访问了。这张标签完全显示了HTTP的最大问题:它在死去。
Tim的NeXT计算机现在被存放在博物馆里。属于第一批死去的数百万网络服务器之一。
大家已经看到结果了(见图2.51):

即使从未看过HTTP规范,也可能会知道404。这是HTTP所使用的一个错误代码,代表该网站不再在服务器的那个位置上。一般来讲,这都算走运了。更常见的是,那里一台服务器都没有了,甚至没办法告诉访问者要找的东西丢失了,找都找不到。除非互联网档案馆有备份,不然根本找不到,相关内容永久消失。
网页越老旧,越有可能出现404。这些页面都是冷冰冰的数字墓碑,象征着垂死的网页,无论以前什么知识、美景甚至垃圾曾存储在那里,都化为了同样的404。
笔者从还能被启动的586计算机中Windows 95的浏览器收藏夹中挖出了一两个还能访问的20世纪90年代的网页链接,今天再浏览那些网站,会让人深有所感:HTTP是多么不适合维护网站之间的连接。那个网站上的所有静态内容(虽然早已不再符合现代审美)都能加载,我的新浏览器仍旧能够显示页面(HTML不像HTTP,具有优秀的存续能力)。但是站点上的任何链接或者动态更新的内容都“死”了。这样的例子太多了,不可胜数,尽管链接内容十分有用,网站却已消失。无论消失的内容是值得质疑的垃圾还是经典的有用信息,都是我们的历史,而它们却在迅速消失。
事情发生的原因非常简单:集中管理的网络服务器难以避免被关闭的命运,域名所有权变更或是公司倒闭,也可能是计算机在没有备份的情况下死机了,导致内容无法恢复。让所有人自行运营自己的HTTP服务器无法解决这个问题,只会让结果更糟糕。
(2)HTTP鼓励过度集中化。
这类数据消失的结果导致我们对大型、更集中管理的服务器产生了进一步的依赖。由于冗余备份较多,在短时间内它们的可用性(大多)更高,但是仍没有解决长期的可用性问题,还触发了一系列全新的问题。
从John Perry Barlow的网络空间独立宣言到现在,我们已经走过了漫长的道路。由于信息更多,电子领域对世界变得更有影响力也更有帮助,一些组织机构或者利益集团都开始借助合法抑或非法手段窥探HTTP的缺陷,借此来刺探我们,从我们身上赚钱,并阻止我们访问一切对他们有威胁的内容。
我们想要让互联网去集中化,但今天我们所拥有的页面正在迅速变得集中化,数十亿名用户都依赖着少数几个服务器,如图2.52所示。
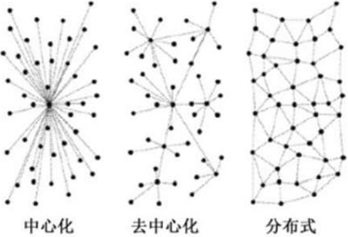
不管你是否认为这是个合理的权衡手段,这并不是使用HTTP的初衷。像NSA(或许还有我们未来的机器人统治者)这样的机构现在只需要拦截几个源头,就能够监控我们的通信。各国政府想要审查内容阻断访问,也会非常容易。同时,我们的通信也有被DDoS攻击的风险。
分布式网页将会让互联网没那么易控,提高网络的自由与独立性。因为无须传输巨量数据,还降低了“一个大停机”这样的风险。
(3)HTTP效率低下。
鸟叔的骑马舞(Gangnam Style)曾达到大约23.4432亿次(2 344 327 696)的浏览量。
我们假设:这部视频的大小是117MB。也就是说,从发布之后,单这部视频(最多)就会有约2742亿MB(274 286 340 432)或者274.3千兆字节的数据流量产生。如果我们假设1GB的总费用是1美分(包括带宽与所有的服务器费用),那么单这部视频目前已经花费了2 742 860美元。
对谷歌来说这还不算太糟,但如果对于一个小网站,这么多数据所花费的成本将会是天文数字,特别是对于费用高昂的亚洲(1GB的费用为0.12~0.2美元)小公司来说。
HTTP虽然降低了发布信息的价格,但仍需要花钱,看起来低廉的成本加起来也真不算少。将大量数据从中央数据中心传播出去,如果不是以规模经济的方式完成的话,费用可能相当高昂。
但如果数据不总是从数据中心发送的呢?我们可以将ISP网络的每台计算机转变为一个流媒体CDN。像骑马舞这样热门的视频甚至可以在ISP网内完全下载,而无须消耗互联网主干的大量数据。这是IPFS能够改善的诸多事项之一(我们稍后再继续讨论这个问题)。
(4)HTTP对互联网主干过度依赖。
如果内容过度集中化,将会使我们高度依赖互联网主干的数据中心功能。这样除了很容易被拦截审查之外,也存在着可靠性问题。即使有冗余备份,主要的主干网有时候也会存在被毁坏或者路由表失控问题,结果可能十分严重。
曾经一辆车撞上了Neocities在加拿大所使用的上行光缆,还曾发生过猎人射穿连接东俄勒冈州数据中心的光缆,导致工程师需要使用雪地车前往修复;2015年4月15日在加州海湾地区还出现了光纤受攻击事件。而这些问题的关键都在于,互联网主干并不完美,很容易受攻击,导致重要的光纤线路被切断而影响服务。
2.IPFS如何解决HTTP的问题
IPFS是一个分布式文件系统,试图通过相同的文件系统连接所有计算机设备。在某种程度上,这点与网络初始目标十分类似,但实际上IPFS更接近于交换Git对象的单个比特流群集。IPFS可能会成为互联网的一个重要的新子系统,如果正确构建的话,还可以补充或者取代HTTP。
IPFS目前还处于Alpha开发阶段,我们暂且称之为实验。它还没有取代我们现有的站点存储。就像任何复杂的新科技一样,它还有很多需要改进的地方。不过IPFS并不是虚无缥缈的,现在它的开发者已经将其付诸使用了。
IPFS开发者想要宣布一个大胆至极的概念:IPFS将会取代HTTP(与许多其他东西)。
我们在前文中讨论了HTTP的问题(还有过度集中化的问题),现在讨论一下IPFS如何提高网站体验。
IPFS从根本上改变了我们寻找东西的方式,这是它的关键性能。使用HTTP时搜索的是位置,而IPFS搜索的是内容。
举个例子。我在服务器上运行的一个文件如下:
https://neocities.org/img/neocitieslogo.sv.,浏览器首先找到服务器的位置(IP地址),然后请求我方服务器使用路径名。在这种设计中,只有网站的拥有者能够确定这就是对方寻找的文件,而寻找者是被动的,他需要相信拥有者并未挪动文件或者关闭服务器。
我们不用再寻找一个被集中化控制的位置,并询问它/img/neocitieslogo.svg是什么,取而代之的是我们向由数百万台计算机组成的分布式网络请求文件时不通过文件名,而是通过文件所包含的内容,这正是IPFS所做的事情。
在将neocitieslogo.svg添加到IPFS节点时,它获得了一个新名字:QmXGTa GWTT1uUtfSb2sBAvArMEVLK4rQEcQg5bv7wwdzwU。这个名字实际上是一个加密哈希,是从文件的内容中计算得来的。这个哈希通过加密确保永久显示该文件的内容。如果文件被修改了哪怕一个比特,哈希都会面目全非。
如果向IPFS分布式网络请求该哈希,它会通过分布式哈希表,有效地找到文件所在节点,取到内容并使用哈希验证数据的正确性。早期的DHT设计曾出现Sybil攻击的问题,不过现在已经有了新的解决办法。
IPFS是通用的,存储限制极少,大文件或者小文件都没问题。它会自动将大文件打散为小部件,允许IPFS节点下载文件,不止有类似HTTP服务器那样的方式,甚至还支持数百个文件的同时下载。IPFS网络成了精细颗粒、去信任化、分布式、易于联合的CDN,并且几乎涉及了所有数据:图片、视频流、分布式数据库、整个操作系统、块环链、8英寸软盘备份,还有最重要的静态网站,这使得它非常有用。
IPFS文件中可以包括特殊的IPFS目录对象,名称为人类可读的文件名(连接着其他IPFS哈希)。采用类似标准HTTP服务器的做法,默认加载目录中的index.html。使用目录对象后,IPFS可以按照与现在完全相同的方式建立起静态页面。给网站添加IPFS节点只需使用这个命令:ipfsadd-ryoursitedirectory,然后就可以从任意IPFS节点访问该网站,而无须请求哈希(样例还有以index.html重命名之后的样例)。
(1)通过IPFS将数据联合起来。
无须将发布到IPFS的内容存储到所有节点上。相反,用户可自主选择要留存的数据。把它想象成书签,除了在网站里无法像书签一样收藏链接之外,整个网站都能备份,还有志愿者帮忙将内容提供给其他想要浏览的人。
如果很多节点都提供一点空间和带宽,很快就能累积成更多的可用空间与带宽,胜过任何集中化的HTTP服务。分布式网络很快就会发展成为全世界速度最快、可用性最佳以及最大的数据存储方式,想要关闭渠道来个“焚书”是绝无可能了,秦朝的悲剧也不会再重演。
从其他IPFS节点复制、存储网站并提供相应服务变得十分简单。只需一个命令外加网站的哈希:ipfspinadd-rQmcKi2ae3uGb1kBg1yBpsuwo VqfmcByNdMiZ 2pukxyLWD8,然后IPFS会负责剩下的工作。
(2)IPNS。
IPFS哈希代表着不可变的数据,也就是说,如果哈希不变,内容也不会变。由于对数据留存有促进作用,这是一件好事,不过我们仍需一种办法找到代表相应网站的最新哈希值。IPFS使用了特有的IPNS功能来完成这一使命。
IPNS 允许用户使用密匙对代表网站最新版本(使用哈希公钥,简称PubkeyHash)的IPFS哈希进行签名。这个概念和比特币(Bitcoin)相似,因为一个比特币地址也就是一个PubkeyHash。通过Neocities的IPFS节点对你的图片进行签名之后,用户使用相关节点的IPNSPubkeyHash来下载:
QmTodvhq9CUS9hH8rirt4YmihxJKZ5tYez8PtDmpWrVMKP。
虽然IPNS还在开发与完善中,但其开发原则是PubkeyHash的指向可以修改,而PubkeyHash会保持不变。
(3)人类可读的可变地址。
IPFS/IPNS的哈希非常大,而且是难以记忆的丑陋字符串。因此IPFS允许用户使用现有的域名系统(DNS)为IPFS/IPNS内容提供人类可读的链接。使用者只需将一个存有哈希的TXT文档放在NameServer上(如果读者手边有命令行的话,运行:digTXTipfs.git.sexy)。就能看到访问http://ipfs.io/ipns/ipfs.git.sexy的操作。
下一步IPFS计划支持域名币(Namecoin),理论上Namecoin可以用来创建一个完整的去中心化、分布式网络,而无须中央机构。不用互联网名称与数字地址分配机构(ICANN),不用中央服务器,没有XX局审批也没有昂贵的证书,而且没有瓶颈。
(4)IPFSHTTP网关:旧网络与新网络的桥梁。
当前用来举例的IPFS是通过一个HTTP网关转接的,在浏览器支持直接访问IPFS之前,允许现有的网络浏览器访问IPFS时,需要通过IPFSHTTP网关(以及Nginx的帮助)来使用这个新技术。
目前,对IPFS的初步实施都是试验性质的。Neocities每天在更新站点时都会发布一个IPFS哈希,每个主页都能访问。这个哈希指向网站的最新版本,通过IPFSHTTP网关就可以访问。由于IPFS哈希每次更新都会变化,这种做法也会让所有站点的历史存档被保留下来,并且只需正常使用IPFS就能自动生成存档。
(5)未来我们将如何运用IPNS。
从长远来看,如果一切顺利的话,我们或许会想要利用IPFS来存储我们的所有网站,并为每个站点创建IPNS密钥,这将会使用户所发布的内容与开发团队所发布的独立开来。即使Neocities不在了,用户也可以更新自己的网站,并有效地将用户对中央存储的依赖转移到IPFS计划的服务器上,随后打碎成各个部分,从而永久地粉碎集中管理网络世界的计划。
三、MaidSafe分布式网络平台
MaidSafe分布式网络平台是全分布式P2P网络的代表。MaidSafe公司2006年成立于苏格兰,公司希望利用广泛使用的服务器,构建出一套去中心化数据网络,并且在这个网络上开发去中心化的应用程序。MaidSafe的愿景是采用完全分布式的安全、保密、隐私的网络去替换易受到攻击的中心化网络。该网络是一个无法被第三方拦截、复制、窃取、访问数据的网络。
MaidSafe分布式网络平台包括SAFE(Secure Access for Everyone)网络和客户端应用两部分。SAFE网络可以被描述为一个完全分布式的数据管理服务,客户端应用是根据SAFE网络API开发的去中心化应用,如图2.53所示。SAFE网络允许开发者创建任何快速和安全的应用程序,无须购买API和基础网络设施,开发商不会面临任何资金风险,大大降低了用户获取成本。

SAFE网络管理静态数据和动态数据及通信。在任何情况下,网络无法解密任何网络上的数据。它可以看作一个去中心化的服务器系统,可以完成传统网络提供的httpd、ssh、scp、ftp、smtp、pop3及imap功能。
MaidSafe网络采用商业计算机未使用的硬盘空间、CPU和通信能力。这些计算机可能由系统的特殊用户拥有,但不仅限于这些用户。每台计算机将通过高效的工作获得能够换取其他货物和服务的信用货币,这些信用货币被称为安全币(SafeCoin)。安全币通过公平透明的方式激励开发人员、支持者和最终用户。
SAFE网络使用安全币交易,安全币发行量为2^32个,价值将由市场决定。
SAFE网络客户端应用程序通过一些创新的步骤进行网络接入:
·自我加密数据。
·基于一个去中心化的PKI访问和创建安全加密保护的ID。
·自我认证。
客户端应用程序可以在该网络上进行访问、存储、修改和通信操作。客户端允许人们以匿名方式加入网络,并且不能阻止人们加入。客户端通过虚拟驱动器获得数据,利用编程方法操纵客户端应用内数据、通信数据以及动态数据。
1.MaidSafe平台网络模型
互联网最基本的层次,通常被描述成OSI模型,包括电缆、路由器、交换机、服务器和一些被连接上的终端设备。在这个层面上看,数据存在于它最基本的水平,是1和0的堆砌。这些硬件设备需要一个独一无二的位置地址(在TCP/IP网络里)以便它们彼此能够找到另一个设备,这个被称为IP(互联网协议)地址。
你可能听说过,现行的IPv4的IP地址即将被耗尽(只有2^32个),所以,互联网工程任务组一直在试图向IPv6过渡,通过25年左右的时间来完成这一过程,然而,转变通常是缓慢的。你可以看到图2.54上有一个网络层,它通过使用消息内容和目的地址(IP)进行数据的传输,然后决定如何进行这一项工作。这些信息通常是以被分解成碎片或数据包的形式进行传输的。
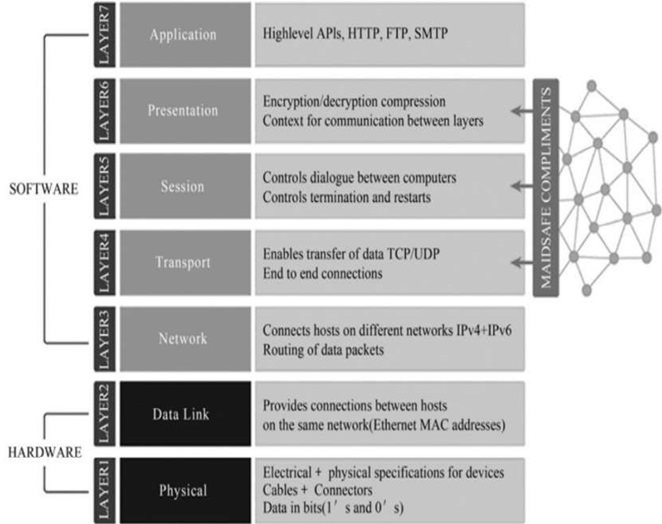
这一点正是现有的互联网和SAFE网络的不同之处。传输层实现的是从一个资源和目的地之间进行可变长度的数据传递,不断检查以确保每个数据包都被传送到目的地,并且重新提交那些没有被成功传送的信息包。我们可以把传输层类比成一个邮局,分类和发送信件、包裹到达目的地。常见的两个层包含的协议是传输控制协议(TCP)和用户数据包协议(UDP)。
会话层管理设备之间的连接,建立、管理和终止应用程序之间的交流与对话。会话层响应来自表示层的请求,它负责将数据从会话层传输到应用层,并将其转化成可被后者接受和显示的格式。这可能包括例如加密解密功能、数据压缩等手段。
最后我们来到了应用层,即OSI模型的最高层,这也是被广大互联网用户所熟悉的一层。应用层把信息从低层传导显示给用户,这就是我们每天都在使用与进行交互操作的一个个应用程序。在这个层面上我们会看到:在网络上进行数据通信的基础协议如超文本传输协议(HTTP),以及发送电子邮件的邮件简化传输协议(SMTP)。
下面将SAFE网络模型和OSI模型进行对比。如图2.55所描绘的,SAFE网络是一个重叠的网络,利用互联网现有的硬件和网络层。值得注意的是,在这一点上,我们专注于在软件层面的更改,可以预期的是,SAFE网络将在硬件层内产生显著的影响。随着越来越多的网络资源被SAFE网络的用户所提供,我们将有能力减少部署的服务器数量,以及改变它们使用的方式。
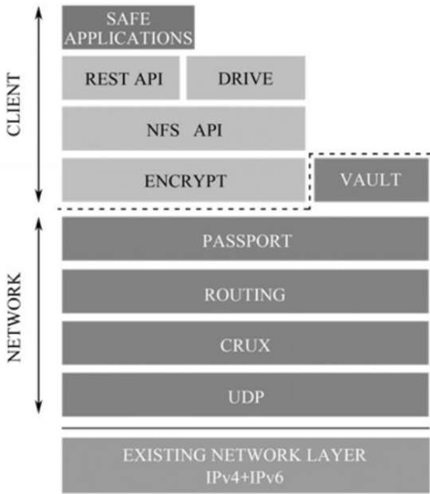
依托现有的互联网基础设施的硬件和基础网络,SAFE网络利用了UDP传输协议,在该协议之上层使用CRUX协议(Connected Reliable Udpe Xchange)。通过这两层的组合和之上的路由层,在提供了TCP可靠性和控制拥堵的同时,还帮助解决了NAT穿越的问题。
网络地址翻译(NAT)通常用于解决之前提到的IPv4地址耗尽问题,把个人IP地址添加在一个公共IP地址的后面。由于NAT无法确定传入的消息用于哪个设备,这带来了一个问题,特别是P2P程序,如文件共享服务,如Torrents,或像Skype的VOIP应用。CRUX、UDP和路由的使用,使得安全网络得以穿越所有的NAT路由器。
在UDP和CRUX之上的路由层是分布式哈希表(DHT),基于Kademlia之上,管理网络上的节点之间的路由。每个节点在本地存储与之连接的其他节点的信息。到达目的地之前,用作信息交换的路由通常会经过许多个中间的节点传输数据。CRUX提供的确认/重传机制确保信息可以被可靠地传递,这是通信成功的关键。
在用户的计算机设备上,Passport和VAULT可以完成网络库所需要的一切。
Passport工具的关键作用在于验证用户,使他们能够执行各种任务,如转移一个SafeCoin的所有权或访问一个文件。这些密钥并不需要中心化的权威授权验证。
VAULT被掌管在网络上的矿工手里。这些VAULT在执行多种功能,包括管理数据、存储数据、维护客户端、管理其他网络节点以及整个网络。
应用程序接口(API)在加密层的最上面,为安全的客户端(应用程序)提供连接到基础网络的方式。这些API(有两个)将被网络中APP的开发者用于使他们的应用程序可以使用这些网络功能。其余的API可以用来创建一些简单的命令,如输入(put)、得到(get)、删除(delete)……而像NFSAPI的POSIX则提供更精细的访问,加入更多的高级功能。驱动器是一个跨平台的虚拟驱动器,被API所公用,在网络用户的计算机上作为一个本地驱动器来面向网络。
2.MaidSafe网络特性
SAFE网络具有如下特性。
(1)无服务器。
·无服务器=无数据中心。
·100%服务器安全(无服务器)。
·不受网络审查(无DNS)。
·杜绝通过缓存进行投机性攻击。
·无限数据存储,无资金成本和交易。
(2)无管理员,只有用户。
·网络实时自动配置和重新配置。
·通过在互联工作的数百个节点上运行成千上万的算法保护隐私和数据。
·网络决定实时数据存储位置。
·为用户提供实时数据高速缓存。
·无须网络配置和规划(计算机做得比我们更好)。
·没有数据中心,所以没有数据中心的工作人员。
(3)数据管理安全。
·所有数据都是实时加密的,用户不可见。
·实时删除重复数据,减少存储的数据量。
·实时复制数据,恢复和修复数据。
·“复制”数据的地理分布(允许大规模网络中断零损失)。
·通过签名和密钥安全加密保障所有权。
·除非特别共享,否则不能访问别人的数据。
(4)密码和密钥安全。
·100%防止密码在传输过程被盗(它们从不发送)。
·最少三个不同的系统区域隔离ID和密钥(无网络连接它们)。
·登录系统采用用户名、pin码和密码。
·存储、检索和操作数据采用另一个身份ID(密钥集)。
·与他人沟通采用另一个身份ID。
·对于每个私人分享创建和共享另一个密钥链。
(5)共享任何数据。
·创建朋友和同事之间的私密分享(即时并安全)。
·创建任意数量的公开数据分享(薄网站)。
·创建微博客系统。
·创建社交网络系统。
·没有大小限制地共享任何内容,如音乐、节目、照片,甚至操作系统。
(6)分布式应用。
·允许在最小的设备上运行超大应用程序。
·在网络上共享CPU、存储和内存,自动分配到每个设备。
·允许结构化数据的版本回退,支持自动和手动合并以匹配应用程序。
3.MaidSafe网络应用
客户端的应用包括云存储、消息加密、密码钱包、任何程序提供的任何数据文件的处理、分布式数据库、文件共享与知识产权保护的研究、文件签署、合同的签订、分散的团体或公司的合作及交易机制等许多方面。客户端可以访问当前提供的所有互联网服务,并提供许多在中心化结构网络下不能实现的服务,如图2.56所示。

在这些客户端访问网络时,将确保用户没有通过另一个密码来访问更深入的服务。客户端包括许多加密保护的密钥对,可以使用这些密钥自动登录会话管理或处理任何网络服务会员的要求。因此,一个会员网站可以展示一个加入按钮,仅仅是单击这个按钮就能签署一项合约,并获得未来的访问权限。数字投票、新闻聚合、机密信息和知识转移等业务现在都是可能的,但这只是开始!
四、StoreJ分布式云储存
StoreJ起源于2014年4月,研究团队在得克萨斯州比特币会议的黑客马拉松中赢得大奖,从而获得了BitAngles基金25万美元的投资。StoreJ在其白皮书中表示,当前传统的云储存不过是一个营销名词,其中心化的存储机制完全基于用户对于数据储存商的信任,而无处不在的DDoS攻击、Sybil攻击、窃听软件,甚至内部人员的主动泄露的威胁也几乎证明了这种信任基础的羸弱不堪。图2.57为传统云储存应用架构。
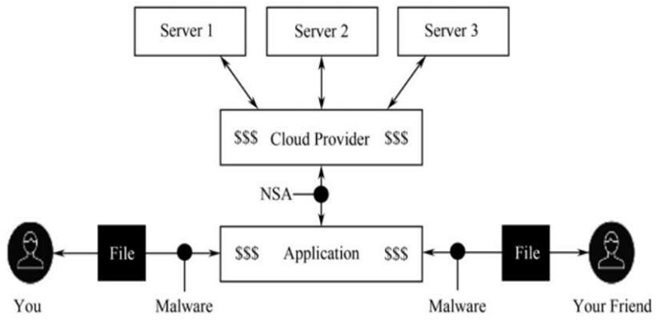
资料来源:WilkinsonSet al,(2014)MetadiskABlockchain-Based Decentralized File Storage Application.
同时,存储技术的发展原本给用户带来的应该是日渐低廉的储存成本,却由于传统架构的缺陷使得中心化云储存的员工工资、法律成本、安防成本、数据中心租金等这些固定成本日益增加,而最终造成了用户需要花费越来越多的资金在储存上。
而StoreJ则通过磁盘共享的理念,鼓励网络上的用户分享各自闲置的硬盘空间,并通过分享自己的硬盘空间而获取一定的收益。这种模式在StoreJ的对比中体现出了明显的费用优势,图2.58为100GB储存空间的每月费用对比。
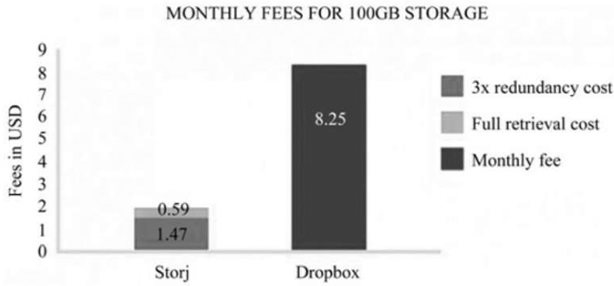
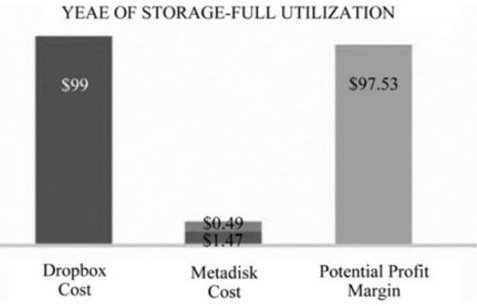
目前,从Dropbox租用100GB存储空间的年费是99美元。即使用户没有全部使用,他也需要交99美元的年费。有了StoreJ,人们可以花费1.47美元到例如Digital Ocean这样的公司租用虚拟个人主机(VPS),还包括备份,再花0.49美元购买检索数据服务,只花费1.96美元就获得Dropbox价值99美元的存储空间,如图2.59所示。在VPS上,用户可以在StoreJ平台上出租额外的硬盘空间,获取利润。
一般而言,由于每12个月存储能力会翻倍,存储成本越来越低。如果去中心化存储系统是完全自动化的,云存储价格最终会降到接近零,并且通过参考比特币的区块链架构,它通过将自身的P2P货币STCX与存储空间、算力、带宽进行连接而实现去信任化的安全结构。
1.文件加密碎片化处理
被碎片化切割的文件能够确保矿工无法获得完整的文件,而确保被存储文件的安全。StoreJ将矿工定义为向整个网络提供硬盘空间的用户。通过碎片化的文件,能够阻止任何矿工选择性地对文件进行存储,也使得大容量文件能够以碎片化遍布各个网络节点的形式实现分布式存储,如图2.60所示。
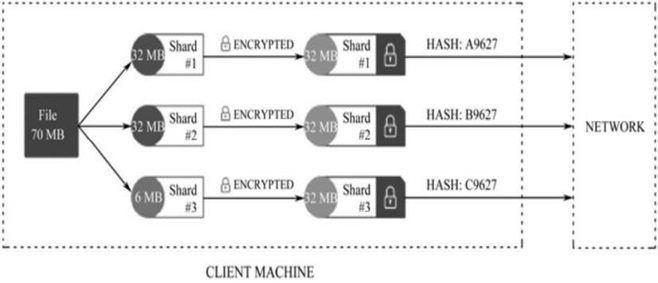
资料来源:WilkinsonSet al,(2014)StorJ:A Peer-to-Peer Cloud Storage Network.
事实上,多个碎片也能够进行组合并再加密,通过这种方式,几个来源不同的碎片组合加密后再发布到网络上将获得更高的安全保障。
2.存储安全保障
每一个矿工都必须从密码学上证明自己所储存的碎片是完整的且未被篡改的。而为了确保所有在网络上存储自己文件的用户能够验证被矿工们储存的文件,StoreJ通过了Merkle Tree类似比特币验证SPV钱包的验证方式,实现了其所谓的文件完整性审计。
由于传统的中心化云储存通过独立硬盘冗余阵列(RAID)或多数据中心的方式,进行物理数据备份而保障网络失效下的数据安全。而StoreJ并不存在中心化服务器,而是分布于整个网络的节点之中的,也无法依靠一个矿工去完成原本中心化服务器所要完成的备份工作,因此StoreJ通过K-of-M抹除码能实现同一个文件碎片在多个矿工磁盘上的冗余储存。
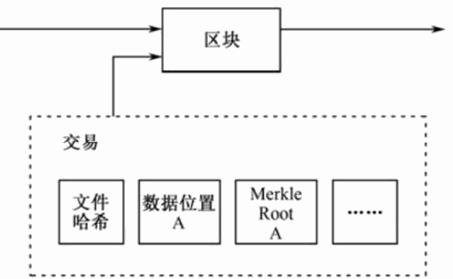
StoreJ通过将实时的数据存储状态广播在区块链上,来使得每一个时间节点的存储状态都置于公共监管之下。由于向比特币区块链直接上传数据非常不经济,也受到数据大小的限制,因此当前实践中使用的是Florincoin区块链,开发团队表示后期将考虑类似Factom或者以太坊的形式形成独立共识机制架构,如图2.61所示。
3.传输速度
增加了的冗余使得StoreJ网络体现出了独特的功能。由于StoreJ是一个去中心化分布式网络,新增加一个提供文件碎片存储空间的矿工,就会同时新增加一个能够下载这个文件碎片的节点。如果将冗余度设置为20倍,则意味着将会有20个节点同时下载同一片文件碎片。这与传统中心化Server-Client模式中自动寻找最近数据中心的方式恰恰相反。
作为一项点对点网络的标准功能,StoreJ能够通过连接地理位置上最相近的节点来获得高传输速度,而节点数量越大,传输的速度也就越快。我们因此也会引入加密数字货币作为激励机制鼓励参与的节点能够实时处于分享状态,从而避免点对点网络中节点自私化的难题。
4.奖励机制
为了使网络有效运作,StoreJ通过自制的加密数字货币SJCX来针对合适的行为进行积极的奖励。矿工和客户能够通过交易SJCX的形式来在StoreJ网络上交易存储空间与带宽,这种交易以小额支付的方式实现,从而实现交易的实时性。
目前,StoreJ在进行B组测试,项目团队通过对申请参与的矿工奖励100万个SJCX的形式激励更多的测试节点参与到StoreJ网络中来,以更完整地反映这个分布式云储存的完整性与强健性。








本书评论