
10.4 示例:对地图上的点进行聚类
假如有这样一种情况:你的朋友Drew希望你带他去城里庆祝他的生日。由于其他一些朋友也会过来,所以需要你提供一个大家都可行的计划。Drew给了你一些他希望去的地址。这个地址列表很长,有70个位置。
我把这个列表保存在文件portland-Clubs.txt中,该文件和源代码一起打包。这些地址其实都在俄勒冈州的波特兰地区。
也就是说,一晚上要去70个地方!你要决定一个将这些地方进行聚类的最佳策略,这样就可以安排交通工具抵达这些簇的质心,然后步行到每个簇内地址。Drew的清单中虽然给出了地址,但是并没有给出这些地址之间的距离远近信息。因此,你要得到每个地址的纬度和经度,然后对这些地址进行聚类以安排你的行程。
示例:对于地理数据应用二分k均值算法
1. 收集数据:使用Yahoo! PlaceFinder API收集数据。
2. 准备数据:只保留经纬度信息。
3. 分析数据:使用Matplotlib来构建一个二维数据图,其中包含簇与地图。
4. 训练算法:训练不适用无监督学习。
5. 测试算法:使用10.4节中的biKmeans()函数。
6. 使用算法:最后的输出是包含簇及簇中心的地图。
你需要一个服务来将地址转换为纬度和经度。幸运的是,雅虎提供了这样的服务。下面将介绍Yahoo!
PlaceFinder API的使用方法。然后,对给出的地址坐标进行聚类,最后画出所有点以及簇中心,并看看聚类结果到底如何。
10.4.1 Yahoo! PlaceFinder API
雅虎的牛人们已经为我们提供了一个免费的地址转换API,该API对给定的地址返回该地址对应的纬度与经度。访问下面的URL可以了解更多细节:http://developer.yahoo.com/geo/placefinder/guide/。
为了使用该服务,需要注册以获得一个API key。具体地,你需要在Yahoo!开发者网络(http://developer.yahoo.com/)中进行注册。创建一个桌面应用后会获得一个appid。需要appid来使用geocoder。一个geocoder接受给定地址,然后返回该地址对应的经纬度。下面的代码将上述所有过程进行了封装处理。打开kMeans.py文件,然后加入下列代码。
程序清单10-4 Yahoo! PlaceFinder API
import urllib
import json
def geoGrab(stAddress, city):
apiStem = 'http://where.yahooapis.com/geocode?'
params = {}
#❶ 将返回类型设为JSON
params['flags'] = 'J'
params['appid'] = 'ppp68N8t'
params['location'] = '%s %s' % (stAddress, city)
url_params = urllib.urlencode(params)
yahooApi = apiStem + url_params
#❷ 打印输出的的URL
print yahooApi
c=urllib.urlopen(yahooApi)
return json.loads(c.read())
from time import sleep
def massPlaceFind(fileName):
fw = open('places.txt', 'w')
for line in open(fileName).readlines():
line = line.strip()
lineArr = line.split('\t')
retDict = geoGrab(lineArr[1], lineArr[2])
if retDict['ResultSet']['Error'] == 0:
lat = float(retDict['ResultSet']['Results'][0]['latitude'])
lng = float(retDict['ResultSet']['Results'][0]['longitude'])
print "%s\t%f\t%f" % (lineArr[0], lat, lng)
fw.write('%s\t%f\t%f\n' % (line, lat, lng))
else: print "error fetching"
sleep(1)
fw.close()上述程序包含两个函数:geoGrab()与massPlaceFind()。函数geoGrab()从Yahoo返回一个字典,massPlaceFind()将所有这些封装起来并且将相关信息保存到文件中。
在函数geoGrab()中,首先为Yahoo API设置apiStem,然后创建一个字典。你可以为字典设置不同值,包括flags = J,以便返回JSON格式的结果❶。(不用担心你不熟悉JSON,它是一种用于序列化数组和字典的文件格式,本书不会看到任何JSON。JSON是JavaScript Object Notation的缩写,有兴趣的读者可以在www.json.org找到更多信息。)接下来使用urllib的urlencode()函数将创建的字典转换为可以通过URL进行传递的字符串格式。最后,打开URL读取返回值。由于返回值是JSON格式的,所以可以使用JSON的Python模块来将其解码为一个字典。一旦返回了解码后的字典,也就意味着你成功地对一个地址进行了地理编码。
程序清单10-4中的第二个函数是massPlaceFind()。该函数打开一个tab分隔的文本文件,获取第2列和第3列结果。这些值被输入到函数geoGrab()中,然后需要检查geoGrab()的输出字典判断有没有错误。
如果没有错误,就可以从字典中读取经纬度。这些值被添加到原来对应的行上,同时写到一个新的文件中。如果有错误,就不需要去抽取纬度和经度。最后,调用sleep()函数将massPlaceFind()函数延迟1秒。这样做是为了确保不要在短时间内过于频繁地调用API。如果频繁调用,那么你的请求可能会被封掉,所以将massPlaceFind()函数的调用延迟一下比较好。
保存kMeans.py文件后,在Python提示符下输入:
>>> reload(kMeans)
要尝试geoGrab,输入街道地址和城市的字符串,比如:
>>> geoResults=kMeans.geoGrab('1 VA Center', 'Augusta, ME')
http://where.yahooapis.com/geocode?flags=J&location=1+VA+Center+Augusta%2C+ME&appid=ppp68N6k实际使用的URL会被打印出来,通过这些URL,用户可以看到具体发生了什么。如果并不想看到URL,那么将程序清单10-4中的print语句注释掉也没关系。下面看一下返回结果,应该是一个很大的字典。
>>> geoResults
{u'ResultSet': {u'Locale': u'us_US', u'ErrorMessage': u'No error',u'Results':[{u'neighborhood': u'', u'house': u'1',
u'xstreet': u'', u'line4': u'United States', u'line3': u'', u'line2':u'Augusta, ME 04330-6410', u'line1': u'1 Center上面给出的是一部只包含键ResultSet的字典,该字典又包含分别以Locale、ErrorMessage、Results、version、Error、Found和Quality为键的其他字典。
读者可以看一下所有这些键的内容,不过我们主要感兴趣的还是Error和Results。
Error键值给出的是错误编码。0意味着没有错误,其他任何值都代表没有获得要找的地址。可以输入下面内容以获得错误编码:
>>> geoResults['ResultSet']['Error']
0现在看一下纬度和经度,可以输入如下命令来实现:
>>> geoResults['ResultSet']['Results'][0]['longitude']
u'-69.776608'
>>> geoResults['ResultSet']['Results'][0]['latitude']
u'44.307661'上面给出的都是字符串,可以使用float()函数将它们转换为浮点数。下面看看在多行上的运行效果,输入命令执行程序清单10-4中的第二个函数:
>>> kMeans.massPlaceFind('portlandClubs.txt')
Dolphin II 45.486502 -122.788346.
.
Magic Garden 45.524692 -122.674466 Mary's Club 45.535101 -122.667390 Montego's 45.504448 -122.500034这会在你的工作目录下生成一个称为places.txt的文本文件。接下来将使用这些点进行聚类,并将俱乐部以及它们的簇中心画在城市地图上。
10.4.2 对地理坐标进行聚类
现在我们有一个包含格式化地理坐标的列表,接下来可以对这些俱乐部进行聚类。在此过程中使用Yahoo!
PlaceFinder API来获得每个点的纬度和经度。下面需要使用这些信息来计算数据点与簇质心的距离。
这个例子中要聚类的俱乐部给出的信息为经度和维度,但这些信息对于距离计算还不够。在北极附近每走几米的经度变化可能达到数10度;而在赤道附近走相同的距离,带来的经度变化可能只是零点几。可以使用球面余弦定理来计算两个经纬度之间的距离。为实现距离计算并将聚类后的俱乐部标识在地图上,打开kMeans.py文件,添加下面程序清单中的代码。
程序清单10-5 球面距离计算及簇绘图函数
def distSLC(vecA, vecB):
a = sin(vecA[0,1]*pi/180) * sin(vecB[0,1]*pi/180)
b = cos(vecA[0,1]*pi/180) * cos(vecB[0,1]*pi/180) * cos(pi * (vecB[0,0]-vecA[0,0]) /180)
return arccos(a + b)*6371.0
import matplotlib
import matplotlib.pyplot as plt
def clusterClubs(numClust=5):
datList = []
for line in open('places.txt').readlines():
lineArr = line.split('\t')
datList.append([float(lineArr[4]), float(lineArr[3])])
datMat = mat(datList)
myCentroids, clustAssing = biKmeans(datMat, numClust, distMeas=distSLC)
fig = plt.figure()
rect=[0.1,0.1,0.8,0.8]
scatterMarkers=['s', 'o', '^', '8', 'p', 'd', 'v', 'h', '>', '<']
axprops = dict(xticks=[], yticks=[])
ax0=fig.add_axes(rect, label='ax0', **axprops)
imgP = plt.imread('Portland.png')
#❶ 基于图像创建矩阵
ax0.imshow(imgP)
ax1=fig.add_axes(rect, label='ax1', frameon=False)
for i in range(numClust):
ptsInCurrCluster = datMat[nonzero(clustAssing[:,0].A==i)[0],:]
markerStyle = scatterMarkers[i % len(scatterMarkers)]
ax1.scatter(ptsInCurrCluster[:,0].flatten().A[0],ptsInCurrCluster[:,1].flatten().A[0],marker=
ax1.scatter(myCentroids[:,0].flatten().A[0],myCentroids[:,1].flatten().A[0], marker='+', s=300)
plt.show()上述程序清单包含两个函数。第一个函数distSLC()返回地球表面两点之间的距离。第二个函数clusterClubs()将文本文件中的俱乐部进行聚类并画出结果。
函数distSLC()返回地球表面两点间的距离,单位是英里。给定两个点的经纬度,可以使用球面余弦定理来计算两点的距离。这里的纬度和经度用角度作为单位,但是sin()以及cos()以弧度为输入。可以将角度除以180然后再乘以圆周率pi转换为弧度。导入NumPy的时候就会导入pi。
第二个函数clusterClubs()只有一个参数,即所希望得到的簇数目。该函数将文本文件的解析、聚类以及画图都封装在一起,首先创建一个空列表,然后打开places.txt文件获取第4列和第5列,这两列分别对应纬度和经度。基于这些经纬度对的列表创建一个矩阵。接下来在这些数据点上运行biKmeans()并使用distSLC()函数作为聚类中使用的距离计算方法。最后将簇以及簇质心画在图上。
为了画出这些簇,首先创建一幅图和一个矩形,然后使用该矩形来决定绘制图的哪一部分。接下来构建一个标记形状的列表用于绘制散点图。后边会使用唯一的标记来标识每个簇。下一步使用imread()函数基于一幅图像来创建矩阵❶,然后使用imshow()绘制该矩阵。接下来,在同一幅图上绘制一张新的图,这允许你使用两套坐标系统并且不做任何缩放或偏移。紧接着,遍历每一个簇并将它们一一画出来。标记类型从前面创建的scatterMarkers列表中得到。使用索引i % len(scatterMarkers)来选择标记形状 ,这意味着当有更多簇时,可以循环使用这些标记。最后使用十字标记来表示簇中心并在图中显示。
下面看一下实际效果,保存kMeans.py并在Python提示符下输入如下命令:
>>> reload(kMeans)
>>> kMeans.clusterClubs(5)
sseSplit, and notSplit: 3073.83037149 0.0
the bestCentToSplit is: 0
.
.
.
sseSplit, and notSplit: 307.687209245 1118.08909015
the bestCentToSplit is: 3
the len of bestClustAss is: 25
执行上面的命令后,会看到与图10-4类似的一个图。
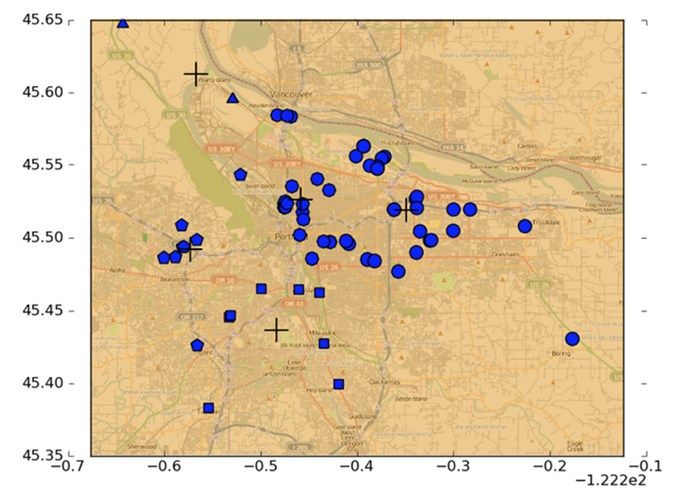
可以尝试输入不同簇数目得到程序运行的效果。什么数目比较好呢? 读者可以思考一下这个问题。






本书评论