
4.4 输入为数值型数据的线性回归方法的扩展
目前为止,算法开发关注于回归问题,其中要预测的输出为实数值。如何把讨论的方法推广到分类问题,其中输出为两个离散值(或者更多),比如“点击”或者“未点击”?
有多种方法将目前的回归问题推广到分类问题。
4.4.1 使用惩罚回归求解分类问题
对于二分类问题,将二值转换为实数值往往会获得好结果。该过程将 2 个类别值编码为 1 和 0(或者 +1 和 −1)。通过这个简单的安排,标签列表变为一串实数值,之前讨论的算法就可以应用上。虽然有很多扩展方法,但上述方法往往是一个不错的方法。上述简单编码的方法要比复杂方法训练更快,这个特性很重要。
代码清单 4-4 给出了在岩石 - 水雷数据集上将类别属性替换为 0 和 1 的一个例子。回想下第 2 章岩石 - 水雷数据集对应于一个分类问题。数据集来自于一次具体实验,实验目标是确定能否通过声纳来检测未爆炸的水雷。除水雷外,其他物体也会反射声波,那么预测的问题是确定反射声波是来自水雷还是海底岩石。
实验使用的声纳波形称作啁啾波形。啁啾波形在脉冲传输过程中会发生频率升降。岩石水雷数据集中的 60 个属性是在 60 个不同时间点抽样获得的返回脉冲,这些脉冲对应于啁啾脉冲的 60 个不同频段。
代码清单 4-4 展示了如何将分类标签 R 和 M 转换为 0.0 以及 1.0,从而将问题转换为普通回归问题,然后使用 LARS 算法来构建分类器。代码清单 4-4 对整个数据集遍历一遍。
正如上一节所讨论的,你会联想到使用交叉验证或者预留数据来选择最优的模型复杂度。
我们会在第 5 章对这些设计过程进行回顾并比较它们的性能。这里目标集中在如何把已经提到的回归工具应用到分类问题上。
代码清单 4-4 通过为二类标签赋数值来将普通分类问题转换为普通线性回归问题
__author__ = 'mike_bowles'
import urllib2
import sys
from math import sqrt
import matplotlib.pyplot as plot
#read data from uci data repository
target_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data")
data = urllib2.urlopen(target_url)
#arrange data into list for labels and list of lists for attributes
xList = []
for line in data:
#split on comma
row = line.strip().split(",")
xList.append(row)
#separate labels from attributes, convert from attributes from
#string to numeric and convert "M" to 1 and "R" to 0
xNum = []
labels = []
for row in xList:
lastCol = row.pop()
if lastCol == "M":
labels.append(1.0)
else:
labels.append(0.0)
attrRow = [float(elt) for elt in row]
xNum.append(attrRow)
#number of rows and columns in x matrix
nrow = len(xNum)
ncol = len(xNum[1])
#calculate means and variances
xMeans = []
xSD = []
for i in range(ncol):
col = [xNum[j][i] for j in range(nrow)]
mean = sum(col)/nrow
xMeans.append(mean)
colDiff = [(xNum[j][i] - mean) for j in range(nrow)]
sumSq = sum([colDiff[i] * colDiff[i] for i in range(nrow)])
stdDev = sqrt(sumSq/nrow)
xSD.append(stdDev)
#use calculate mean and standard deviation to normalize xNum
xNormalized = []
for i in range(nrow):
rowNormalized = [(xNum[i][j] - xMeans[j])/xSD[j] \
for j in range(ncol)]
xNormalized.append(rowNormalized)
#Normalize labels
meanLabel = sum(labels)/nrow
sdLabel = sqrt(sum([(labels[i] - meanLabel) * (labels[i] -
meanLabel) for i in range(nrow)])/nrow)
labelNormalized = [(labels[i] - meanLabel)/sdLabel for i in range(nrow)]
#initialize a vector of coefficients beta
beta = [0.0] * ncol
#initialize matrix of betas at each step
betaMat = []
betaMat.append(list(beta))
#number of steps to take
nSteps = 350
stepSize = 0.004
nzList = []
for i in range(nSteps):
#calculate residuals
residuals = [0.0] * nrow
for j in range(nrow):
labelsHat = sum([xNormalized[j][k] * beta[k]
for k in range(ncol)])
residuals[j] = labelNormalized[j] - labelsHat
#calculate correlation between attribute columns from
#normalized X and residual
corr = [0.0] * ncol
for j in range(ncol):
corr[j] = sum([xNormalized[k][j] * residuals[k]
for k in range(nrow)]) / nrow
iStar = 0
corrStar = corr[0]
for j in range(1, (ncol)):
if abs(corrStar) < abs(corr[j]):
iStar = j; corrStar = corr[j]
beta[iStar] += stepSize * corrStar / abs(corrStar)
betaMat.append(list(beta))
nzBeta = [index for index in range(ncol) if beta[index] != 0.0]
for q in nzBeta:
if (q in nzList) == False:
nzList.append(q)
#make up names for columns of xNum
names = ['V' + str(i) for i in range(ncol)]
nameList = [names[nzList[i]] for i in range(len(nzList))]
print(nameList)
for i in range(ncol):
#plot range of beta values for each attribute
coefCurve = [betaMat[k][i] for k in range(nSteps)]
xaxis = range(nSteps)
plot.plot(xaxis, coefCurve)
plot.xlabel("Steps Taken")
plot.ylabel(("Coefficient Values"))
plot.show()
#Printed Output:
#['V10', 'V48', 'V44', 'V11', 'V35', 'V51', 'V20', 'V3', 'V21', 'V15',
# 'V43', 'V0', 'V22', 'V45', 'V53', 'V27', 'V30', 'V50', 'V58', 'V46',
# 'V56', 'V28', 'V39']
图 4-7 为 LARS 算法关联的系数曲线。曲线形状与红酒口感预测曲线类似。然而,这里的曲线数量更多,因为岩石 - 水雷数据集属性更多(岩石水雷数据包含 60 个属性以及208 行数据)。基于第 3 章的讨论结果,你可能认为最优解不会使用所有属性。第 5 章会看到这种属性取舍的结果(这些结果会显著影响解)以及不同方法的性能优劣。

另一类扩展方法是使用输出的似然函数来定义问题,也被称作逻辑回归。glmnet 算法也可以求解逻辑回归,Friedman 的原始论文对 glmnet 逻辑回归进行综述并将其扩展到多类别分类问题,即对超过 2 种离散输出的预测问题。第 5 章将介绍该算法针对二分类以及多分类的版本。
4.4.2 求解超过 2 种输出的分类问题
一些问题需要在多个结果中进行决策。例如,假设你会为你网站的访客呈现多个链接。
访客可能会点击链接中的任何一个,点击返回按钮或者完全退出网站。与整数型的红酒口感得分不同,这里存在多种可选方案。红酒口感为 4 的得分很自然地处在 3 和 5 之间,如果改变一个属性(比如酒精含量)使得分从 3 变为 4,改变更多的话会使得分进一步向相同方向移动。而网站访客的行为结果没有这样的顺序。这被称作多分类问题。
你总可以使用一个两类分类器来解决多分类问题。该技术称作一对所有或者一对其余,从名字上大概可以了解算法是怎么工作的。基本上把多分类问题分解为多个二分类问题。
例如,你可以预测访问者是否会离开网站或者做其他选择。另一个二分类问题是预测用户是否会点击返回按钮或者点击其他的可用链接。总之能生成多少种相反输出,就可以折腾出多少个二分类问题。二分类器在预测时都会输出具体数值,如代码清单 4-4 中的 LARS分类器。这些一对其余的分类器中,预测输出最大的作为获胜结果。第 5 章在玻璃数据集上实现了该算法,其中包含 6 种不同的输出结果。
4.4.3 理解基扩展:使用线性方法来解决非线性问题
本质上,线性方法假设分类以及回归预测可以表示为可用属性的线性组合。如果你有理由怀疑线性模型不够的话该怎么办?仍然可以通过基扩展使用线性模型来处理非线性关系。基扩展的基本想法是问题中的非线性可以通过属性的多项式组合来近似(或者属性的其他非线性函数);你可以向线性回归公式添加原始属性的幂作为回归因子,通过线性方法来确定多项式回归的系数集合。
为了理解为什么该方法有效,可以看代码清单 4-5。代码从红酒口感数据集开始。本章之前提到利用线性模型可以得到酒精是决定口感最重要的属性。这种关系可能不是直线,尤其在酒精度特别高或者特别低的情况下,直线可能弯曲。
代码清单 4-5 展示了如何对上述观点进行验证。
代码清单 4-5 使用基扩展解决红酒口感预测问题
__author__ = 'mike-bowles'
import urllib2
import matplotlib.pyplot as plot
from math import sqrt, cos, log
#read data into iterable
target_url = ("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv")
data = urllib2.urlopen(target_url)
xList = []
labels = []
names = []
firstLine = True
for line in data:
if firstLine:
names = line.strip().split(";")
firstLine = False
else:
#split on semi-colon
row = line.strip().split(";")
#put labels in separate array
labels.append(float(row[-1]))
#remove label from row
row.pop()
#convert row to floats
floatRow = [float(num) for num in row]
xList.append(floatRow)
#extend the alcohol variable (the last column in that attribute matrix
xExtended = []
alchCol = len(xList[1])
for row in xList:
newRow = list(row)
alch = row[alchCol - 1]
newRow.append((alch - 7) * (alch - 7)/10)
newRow.append(5 * log(alch - 7))
newRow.append(cos(alch))
xExtended.append(newRow)
nrow = len(xList)
v1 = [xExtended[j][alchCol - 1] for j in range(nrow)]
for i in range(4):
v2 = [xExtended[j][alchCol - 1 + i] for j in range(nrow)]
plot.scatter(v1,v2)
plot.xlabel("Alcohol")
plot.ylabel(("Extension Functions of Alcohol"))
plot.show()
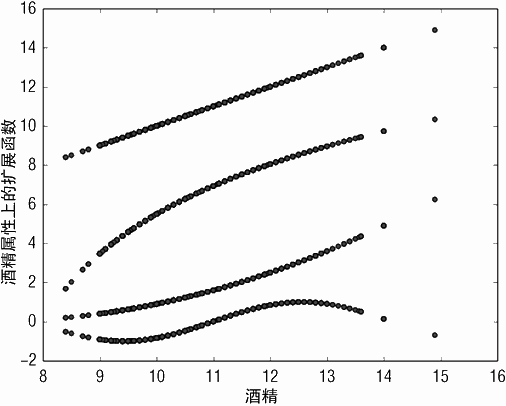
代码按照之前的方式读入数据。读入数据之后(以及在属性正则化之前),代码对数据行进行扫描,向数据行中添加一些新属性,并将扩展后的新行添加到新的属性集上。附加的新属性是原始酒精属性的函数输出。例如,第一个新属性是((alch - 7) * (alch - 7)/10),其中 alch 是数据行的酒精级别。引入常数 7 和 10,从而使新产生的属性都能在一个图上画出来。基本上,新属性取酒精值的平方。
该过程的下一步是使用扩展属性集合来构建一个线性分类器(或者其他可用方法来构建线性模型)。不论使用哪种方法来构建线性模型,模型都需要针对每个属性引入乘子(或者系数),包括新属性。如果扩展使用的函数都是原始属性的幂,线性模型的输出就是原始属性幂的系数。通过选择扩展函数,其他函数族也可以用于构建线性分类器。
图 4-8 展示了新属性与原始属性的依赖关系。可以看到扩展属性是原始属性的平方、log 以及正弦。
4.4.4 向线性方法中引入非数值属性
惩罚线性回归方法(以及其他线性方法)需要使用数值属性。如果你的问题包含其他非数值属性(也称作类别或者因子属性)该怎么办?一个熟悉的例子是性别属性,属性的可能值只有男和女。进行类别属性转换的标准方法是将属性的可能取值编码为若干新的属性列。如果一个属性有N个可能值,那么该属性将被编码为N-1列新的属性。对于每行记录,如果原始属性值为第 i 个可能值,那么将对应的新属性列的第 i 列设为 1,其他列设为 0。
如果该行的原始属性值为第 N 个值,则将对应新属性的所有列设为 0。
代码清单 4-6 展示了如何在鲍鱼数据集上应用该技术。数据集对应的任务是基于不同的身体指标来预测鲍鱼年龄。
代码清单 4-6 在惩罚线性回归方法中对类别属性进行编码 -Abalone Data-larsAbalon.py
__author__ = 'mike_bowles'
import urllib2
from pylab import *
import matplotlib.pyplot as plot
target_url = ("http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data")
#read abalone data
data = urllib2.urlopen(target_url)
xList = []
labels = []
for line in data:
#split on semi-colon
row = line.strip().split(",")
#put labels in separate array and remove label from row
labels.append(float(row.pop()))
#form list of list of attributes (all strings)
xList.append(row)
names = ['Sex', 'Length', 'Diameter', 'Height', 'Whole weight', \
'Shucked weight', 'Viscera weight', 'Shell weight', 'Rings']
#code three-valued sex attribute as numeric
xCoded = []
for row in xList:
#first code the three-valued sex variable
codedSex = [0.0, 0.0]
if row[0] == 'M': codedSex[0] = 1.0
if row[0] == 'F': codedSex[1] = 1.0
numRow = [float(row[i]) for i in range(1,len(row))]
rowCoded = list(codedSex) + numRow
xCoded.append(rowCoded)
namesCoded = ['Sex1', 'Sex2', 'Length', 'Diameter', 'Height', \
'Whole weight', 'Shucked weight', 'Viscera weight', \
'Shell weight', 'Rings']
nrows = len(xCoded)
ncols = len(xCoded[1])
xMeans = []
xSD = []
for i in range(ncols):
col = [xCoded[j][i] for j in range(nrows)]
mean = sum(col)/nrows
xMeans.append(mean)
colDiff = [(xCoded[j][i] - mean) for j in range(nrows)]
sumSq = sum([colDiff[i] * colDiff[i] for i in range(nrows)])
stdDev = sqrt(sumSq/nrows)
xSD.append(stdDev)
#use calculate mean and standard deviation to normalize xCoded
xNormalized = []
for i in range(nrows):
rowNormalized = [(xCoded[i][j] - xMeans[j])/xSD[j] \
for j in range(ncols)]
xNormalized.append(rowNormalized)
#Normalize labels
meanLabel = sum(labels)/nrows
sdLabel = sqrt(sum([(labels[i] - meanLabel) * (labels[i] -
meanLabel) for i in range(nrows)])/nrows)
labelNormalized = [(labels[i] - meanLabel)/sdLabel \
for i in range(nrows)]
#initialize a vector of coefficients beta
beta = [0.0] * ncols
#initialize matrix of betas at each step
betaMat = []
betaMat.append(list(beta))
#number of steps to take
nSteps = 350
stepSize = 0.004
nzList = []
for i in range(nSteps):
#calculate residuals
residuals = [0.0] * nrows
for j in range(nrows):
labelsHat = sum([xNormalized[j][k] * beta[k]
for k in range(ncols)])
residuals[j] = labelNormalized[j] - labelsHat
#calculate correlation between attribute columns from
#normalized wine and residual
corr = [0.0] * ncols
for j in range(ncols):
corr[j] = sum([xNormalized[k][j] * residuals[k]
for k in range(nrows)]) / nrows
iStar = 0
corrStar = corr[0]
for j in range(1, (ncols)):
if abs(corrStar) < abs(corr[j]):
iStar = j; corrStar = corr[j]
beta[iStar] += stepSize * corrStar / abs(corrStar)
betaMat.append(list(beta))
nzBeta = [index for index in range(ncols) if beta[index] != 0.0]
for q in nzBeta:
if (q in nzList) == False:
nzList.append(q)
nameList = [namesCoded[nzList[i]] for i in range(len(nzList))]
print(nameList)
for i in range(ncols):
#plot range of beta values for each attribute
coefCurve = [betaMat[k][i] for k in range(nSteps)]
xaxis = range(nSteps)
plot.plot(xaxis, coefCurve)
plot.xlabel("Steps Taken")
plot.ylabel(("Coefficient Values"))
plot.show()
Printed Output - [filename- larsAbaloneOutput.txt]
['Shell weight', 'Height', 'Sex2', 'Shucked weight', 'Diameter', 'Sex1']
第一个属性是鲍鱼的性别,有 3 种可能值。因为鲍鱼出生不久,性别不能确定,所以有 3 种可能值为 M(雄)、F(雌)以及 I(未定)。
和列相关的变量名使用 Python 列表展示。对于鲍鱼数据集,这些列名并不在数据文件的第一行出现,而是单独保存为一个文件放在 UC Irvine 网站上。列表的第一个变量是动物性别。列表最后一个变量是环数,即切开鲍鱼的壳,使用显微镜观察并统计鲍鱼壳上环的个数。环数实际代表鲍鱼的年龄。该问题的目标是训练一个回归系统来预测环数,而非直接对环数进行计数,这种预测相当于一种更简单、更省时以及更经济的测量手段。
在属性矩阵进行归一化之前,需要完成对性别属性的编码。该过程是构建 2 列来代表3 种可能的值。构建逻辑是如果对应行的性别为雄性(M),将第 1 列设为 1,否则设为 0。
如果性别为雌性(F),第 2 列设为 1。如果样本还处在幼年,2 列都设为 0。新属性列的列名为 Sex1 和 Sex2。
一旦编码完成,属性矩阵包含所有数值,样本就可以按照之前的方法进行处理。算法将变量归一化为 0 均值以及标准差,然后应用先前提到的 LARS 算法来推断系数曲线。
输出展示了进入惩罚线性回归模型中的变量顺序。你会观察到用于编码性别的新的 2 列属性都出现在解中。
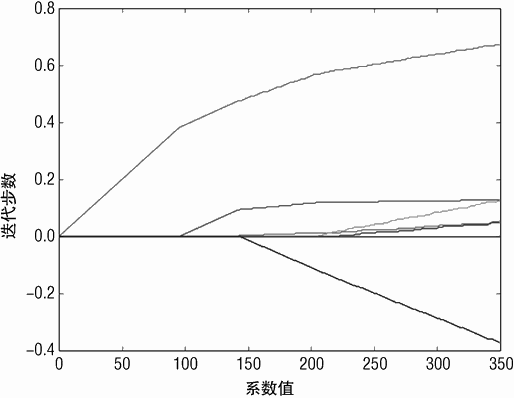
图 4-9 对类别变量使用编码后的新属性在鲍鱼数据集上应用 LARS 算法训练得到的系数曲线本章讨论了惩罚线性回归的几种扩展方法,拓宽了其适应不同问题的能力。本节描述了一个简单常用方法,即将分类问题转换为普通线性回归问题。讨论了如何将二分类推广到多分类问题上。接着讨论了如何在原始属性上应用非线性函数生成新属性,将新属性添加到模型,从而实现使用线性回归来建模非线性行为。最后展示了如何将类别变量转换为数值变量,从而可以在类别变量上训练线性算法。类别变量的转换方法不止可以用于线性回归,也可以用于其他线性方法,如支持向量机。





本书评论