
4.3 求解惩罚线性回归问题
在前面章节中,我们看到求解惩罚线性回归模型等价于求解一个优化问题。有大量通用的数值优化算法可以求解公式 4-6、公式 4-8 以及公式 4-11 对应的优化问题,但是惩罚线性回归问题的重要性促使研究人员开发专用算法,从而能够非常快地生成解。本章将对这些算法进行介绍并且运行相关代码,这样可以帮助理解每种算法的运行机制。本章将介绍 2 种算法:最小角度回归 LARS 以及 Glmnet。之所以选择这 2 种算法是因为它们之间相互关联,并且和前面介绍的方法,如岭回归以及前向逐步回归密切相关。此外,它们训练速度都非常快,并且 Python 包中已经有相关实现。第 5 章会使用 Python 包来引入这些算法求解样例问题。
4.3.1 理解最小角度回归与前向逐步回归的关系
一种非常快速聪明的算法是最小角度回归(LARS)算法,该算法由 Bradley Efron, Trevor Hastie、Iain Johnstone、Robert Tibshirani 等人发明(http://en.wikipedia.org/wiki/Least-angle_regression)。LARS 算法可以理解为一种改进的前向逐步回归算法。
1.前向逐步回归算法
✦ 将 β 的所有值初始化为 0。
在每一步中
✦ 使用已经选择的变量找到残差值。
✦ 确定哪个未使用的变量能够最佳的解释残差,将该变量加入选择变量中。
LARS 算法与前向逐步回归算法非常类似。LARS 与前向逐步回归算法的主要差异是 LARS 在引入新属性时只是部分引入,引入属性过程并非不可逆。LARS 算法过程如下。
2.最小角度回归算法(LARS)
✦ 将 β 的所有值都初始化为 0。
在每一步中
✦ 决定哪个属性与残差有最大的关联。
✦ 如果关联为正,小幅度增加关联系数;关联为负,小幅度减少关联系数。
LARS 算法求解的问题与之前问题稍微不同。然而,它生成的解与套索基本相同,即使结果存在差异,差异也相对较小。之所以介绍 LARS 算法是因为该算法非常接近于套索以及前向逐步回归,LARS 算法很容易理解并且实现起来相对紧凑。通过研究 LARS 的代码,你会理解针对更一般的 ElasticNet 回归求解的具体过程,并且会了解惩罚回归求解的细节。
实现 LARS 算法的代码如代码清单 4-1 所示。
代码清单 4-1 用于预测红酒口感的 LARS 算法 -larsWine2.py
__author__ = 'mike-bowles'
import urllib2
import numpy
from sklearn import datasets, linear_model
from math import sqrt
import matplotlib.pyplot as plot
#read data into iterable
target_url = ("http://archive.ics.uci.edu/ml/machine-learningdatabases/"
"wine-quality/winequality-red.csv")
data = urllib2.urlopen(target_url)
xList = []
labels = []
names = []
firstLine = True
for line in data:
if firstLine:
names = line.strip().split(";")
firstLine = False
else:
#split on semi-colon
row = line.strip().split(";")
#put labels in separate array
labels.append(float(row[-1]))
#remove label from row
row.pop()
#convert row to floats
floatRow = [float(num) for num in row]
xList.append(floatRow)
#Normalize columns in x and labels
nrows = len(xList)
ncols = len(xList[0])
#calculate means and variances
xMeans = []
xSD = []
for i in range(ncols):
col = [xList[j][i] for j in range(nrows)]
mean = sum(col)/nrows
xMeans.append(mean)
colDiff = [(xList[j][i] - mean) for j in range(nrows)]
sumSq = sum([colDiff[i] * colDiff[i] for i in range(nrows)])
stdDev = sqrt(sumSq/nrows)
xSD.append(stdDev)
#use calculate mean and standard deviation to normalize xList
xNormalized = []
for i in range(nrows):
rowNormalized = [(xList[i][j] - xMeans[j])/xSD[j] \
for j in range(ncols)]
xNormalized.append(rowNormalized)
#Normalize labels
meanLabel = sum(labels)/nrows
sdLabel = sqrt(sum([(labels[i] - meanLabel) * (labels[i] -
meanLabel) for i in range(nrows)])/nrows)
labelNormalized = [(labels[i] - meanLabel)/sdLabel \
for i in range(nrows)]
#initialize a vector of coefficients beta
beta = [0.0] * ncols
#initialize matrix of betas at each step
betaMat = []
betaMat.append(list(beta))
#number of steps to take
nSteps = 350
stepSize = 0.004
for i in range(nSteps):
#calculate residuals
residuals = [0.0] * nrows
for j in range(nrows):
labelsHat = sum([xNormalized[j][k] * beta[k]
for k in range(ncols)])
residuals[j] = labelNormalized[j] - labelsHat
#calculate correlation between attribute columns from
#normalized wine and residual
corr = [0.0] * ncols
for j in range(ncols):
corr[j] = sum([xNormalized[k][j] * residuals[k] \
for k in range(nrows)]) / nrows
iStar = 0
corrStar = corr[0]
for j in range(1, (ncols)):
if abs(corrStar) < abs(corr[j]):
iStar = j; corrStar = corr[j]
beta[iStar] += stepSize * corrStar / abs(corrStar)
betaMat.append(list(beta))
for i in range(ncols):
#plot range of beta values for each attribute
coefCurve = [betaMat[k][i] for k in range(nSteps)]
xaxis = range(nSteps)
plot.plot(xaxis, coefCurve)
plot.xlabel("Steps Taken")
plot.ylabel(("Coefficient Values"))
plot.show()
代码主要包括 3 个部分,这里先简单介绍,后续会详细说明。
(1)读入数据以及列名称,将数据转换为属性列表(Python 的 list 对象,每个元素对应一个样例,该样例使用包含属性的 list 对象表示)以及标签。
(2)对属性以及标签进行归一化。
(3)对问题进行求解获得结果 β* β₀ *。
第一段代码用于读入整个文件,将文件头分离出来,使用符号“;”获得文件头分隔的属性名列表,将剩下的行切分为浮点数列表,将所有记录封装为列表(一行记录)的列表,将标签封装为列表。对这些数据结构使用 Python 的列表(list)类型,是因为算法要对行和列进行遍历,而 Pandas 的数据帧类型对这个目的来说太慢。
第 2 段代码使用第 2 章的归一化方法。在第 2 章中,属性归一化的目的是将属性值转换为同等尺度,从而可以方便地绘制以及充分填充坐标。在惩罚线性回归中,归一化一般作为第一步,原因大致相同。
LARS 算法的每一步都会固定增加 β 变量值。属性尺度不同,固定增量对不同属性的影响也不同。同样,如果改变一个属性的尺度(从英里变为英尺),答案会显著不同。因为这些原因,惩罚线性回归包一般使用第 2 章中的加权方法,即归约到 0 均值(减去平均值)、单位方差(用标准方差去除)。算法包一般也会提供非归一化的选项,但是很少听说不进行归一化有什么优势。
第 3 节以及最后一节代码用于求解 β*、β₀*。因为算法运行在归一化的变量上,因此不需要截距 β₀ *。截距 β₀* 一般用于表示标签值与加权属性值之间的差异。因为所有属性已经被归约到 0 均值,所以标签与加权属性的期望没有偏差,β₀ * 就不再需要了。注意到有 2 个 beta 相关的列表被初始化。一个称作 beta,其中元素个数与属性个数相同。另一个是类似于矩阵 - 列表的列表 - 用于存储 LARS 算法每一步生成的 beta 列表。这些都涉及了惩罚线性回归以及现代机器学习算法的重要概念。
4.3.2 LARS 如何生成数百个不同复杂度的模型
一般现代的机器学习算法,尤其是惩罚线性回归方法会生成多组解,不仅是单个解。
回顾公式 4-6、公式 4-8 以及公式 4-11。公式的左侧是 β-,右侧是通过数据求解得到的数值。
在公式 4-6 以及公式 4-8 中,参数 λ 需要通过其他方式确定。正如这些公式中所指定的,当λ=0 时,问题变为最小二乘法,当 λ →∞,β* → 0。所以 β 值取决于公式 4-6、公式 4-8以及公式 4-11 中的参数 λ。
LARS 算法并不会显式处理 λ,但会有同样效果。LARS 算法从 β=0 开始,只要 β 中的某一个系数能够最大程度地减少错误,那么该系数对应增加。被添加的增量会提升 β 整体的绝对值和。如果增量较小并且被用在最佳属性上,该过程就具有求解公式 4-8 对应的最小化问题的效果。可以在代码清单 4-1 中追踪该过程。
基本迭代过程只包含几行代码,从 for 循环开始迭代 n 步。迭代的起始点是 β 的一个值。
第一遍,所有值被设为 0。后续遍历,使用上一次迭代的结果。每次迭代包括 2 步。首先,使用 β 计算残差,残差是指观测结果与预测结果的差异。在该例中,预测结果值等于属性值乘以系数然后加和。第 2 步找到每个属性与残差的关联,从而决定哪个属性对降低残差贡献最大。2 个变量的关联值等于归一化(减去均值后除以标准差)值的乘积。
如果 2 个变量完全相关,比如一个变量是另一个变量的缩放版,那以正的缩放对应于正关联,负的缩放对应于负关联。如果 2 个变量相互独立,那么他们的关联系数为 0。维基百科对关联的解释(http://en.wikipedia.org/wiki/Correlation_and_dependence)展示变量相互关联的例子。列表 corr 包含每个属性的计算结果。你可能注意到严格来讲,代码忽略了对均值、残差以及归一化属性的标准差的计算。这里之所以还有效是因为属性已经被提前归一化为标准差为 1 的值,并且因为这些值被用于寻找最大关联,将所有值乘以一个常数不会影响变量顺序。
一旦关联计算完成,决定哪个属性与残差有最大关联(绝对值最大)就变得简单。β列表中的对应元素会增加一点。如果关联为正,增量就为正,否则增量为负。之后利用 β的新值再进行迭代计算。
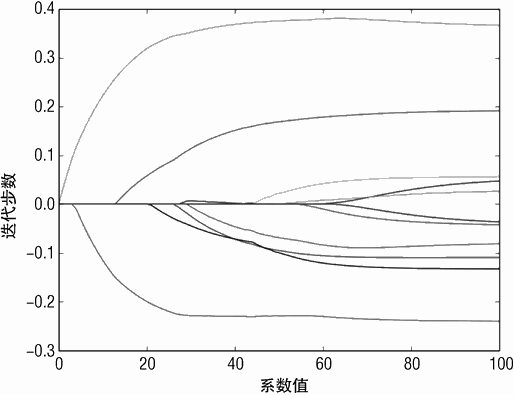
LARS 算法生成的结果如图 4-3 中的曲线所示。对图进行理解可以按照如下的方法:
沿着迭代方向想象有一个点,在该点上,一条垂直线会穿过所有系数曲线。垂直线与系数曲线相交的值是 LARS 算法在该步得到的系数。如果生成曲线需要 350 步,对应就会有350 个系数集合。每个集合是针对特定 λ、对公式 4-8 进行优化获得的结果。这也产生了一个问题:就是使用哪个集合是最优的。该问题会在稍后进行解答。
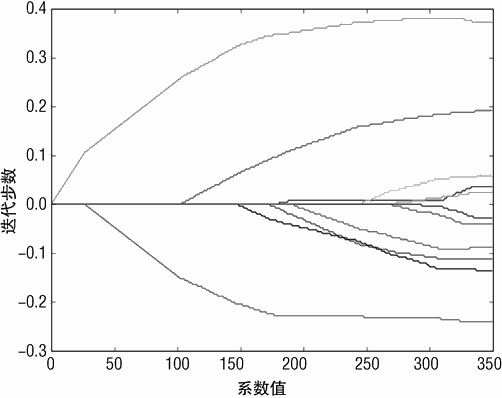
注意到对于前 25 步,只有一个系数值非 0。这对应于套索回归的稀疏属性。第一个不等于 0 的属性是酒精,在此后的一段时间内,这是 LARS 回归唯一使用的变量。随着迭代步数的增加,第 2 个变量开始出现,这样的过程一直持续到所有变量被包含到解中。系数远离 0的过程可以看作是变量重要性的反映。在某些情况下,如果要去掉一些变量的预测,就应该尽量去掉后面出现的而不是开始出现的变量。
重点中的重点
生成变量重要性排序是惩罚线性回归模型的一个重要特征。这使得该模型成为模型初步研究中的一个便捷的工具,因为它们将帮助构建关于保留哪个变量、丢弃哪个变量的决定,这个过程也称作特征工程。你会在后续看到树集成同样会产生变量重要性的度量。不是所有的机器学习方法都会生成此类信息。虽然你总是可以通过尝试所有组合,如 1 个变量、2 个变量等等来生成关于特征的重要性信息,但即使对只有 10 个属性的红酒数据集来说,遍历所有可能子集也需要 10 的阶乘这么多次的训练,这对算法来讲是不可实现的。
4.3.3 从数百个 LARS 生成结果中选择最佳模型
目前关于利用红酒的化学属性上来预测红酒口感得分,已经有 350 个可能的解。如何选择最佳的解?为了选择使用的曲线,你需要了解 350 个选择中每种选择的优劣。正如第3 章所讨论的,性能是指在样本外数据上的性能。第 3 章列出了几种在预留数据上评估性能的方法。代码清单4-2展示了执行10折交叉验证的代码来决定部署使用的最佳系数集合。
10 折交叉验证是将输入数据切分为 10 份几乎均等的数据,将其中一份数据移除,使用剩下数据进行训练,然后再在移除的数据上进行测试。通过遍历 10 份数据,每次移除一份数据用于测试,从而可以对错误进行估计从而估计预测的变化情况。
代码清单 4-2 利用 10 折交叉验证来确定最佳系数集合—larsWineCV.py
__author__ = 'mike-bowles'
import urllib2
import numpy
from sklearn import datasets, linear_model
from math import sqrt
import matplotlib.pyplot as plot
#read data into iterable
target_url = ("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv")
data = urllib2.urlopen(target_url)
xList = []
labels = []
names = []
firstLine = True
for line in data:
if firstLine:
names = line.strip().split(";")
firstLine = False
else:
#split on semi-colon
row = line.strip().split(";")
#put labels in separate array
labels.append(float(row[-1]))
#remove label from row
row.pop()
#convert row to floats
floatRow = [float(num) for num in row]
xList.append(floatRow)
#Normalize columns in x and labels
nrows = len(xList)
ncols = len(xList[0])
#calculate means and variances
xMeans = []
xSD = []
for i in range(ncols):
col = [xList[j][i] for j in range(nrows)]
mean = sum(col)/nrows
xMeans.append(mean)
colDiff = [(xList[j][i] - mean) for j in range(nrows)]
sumSq = sum([colDiff[i] * colDiff[i] for i in range(nrows)])
stdDev = sqrt(sumSq/nrows)
xSD.append(stdDev)
#use calculated mean and standard deviation to normalize xList
xNormalized = []
for i in range(nrows):
rowNormalized = [(xList[i][j] - xMeans[j])/xSD[j] \
for j in range(ncols)]
xNormalized.append(rowNormalized)
#Normalize labels
meanLabel = sum(labels)/nrows
sdLabel = sqrt(sum([(labels[i] - meanLabel) * (labels[i] - meanLabel)
for i in range(nrows)])/nrows)
labelNormalized = [(labels[i] - meanLabel)/sdLabel \
for i in range(nrows)]
#Build cross-validation loop to determine best coefficient values.
#number of cross-validation folds
nxval = 10
#number of steps and step size
nSteps = 350
stepSize = 0.004
#initialize list for storing errors.
errors = []
for i in range(nSteps):
b = []
errors.append(b)
for ixval in range(nxval):
#Define test and training index sets
idxTest = [a for a in range(nrows) if a%nxval == ixval*nxval]
idxTrain = [a for a in range(nrows) if a%nxval != ixval*nxval]
#Define test and training attribute and label sets
xTrain = [xNormalized[r] for r in idxTrain]
xTest = [xNormalized[r] for r in idxTest]
labelTrain = [labelNormalized[r] for r in idxTrain]
labelTest = [labelNormalized[r] for r in idxTest]
#Train LARS regression on Training Data
nrowsTrain = len(idxTrain)
nrowsTest = len(idxTest)
#initialize a vector of coefficients beta
beta = [0.0] * ncols
#initialize matrix of betas at each step
betaMat = []
betaMat.append(list(beta))
for iStep in range(nSteps):
#calculate residuals
residuals = [0.0] * nrows
for j in range(nrowsTrain):
labelsHat = sum([xTrain[j][k] * beta[k]
for k in range(ncols)])
residuals[j] = labelTrain[j] - labelsHat
#calculate correlation between attribute columns
#from normalized wine and residual
corr = [0.0] * ncols
for j in range(ncols):
corr[j] = sum([xTrain[k][j] * residuals[k] \
for k in range(nrowsTrain)]) / nrowsTrain
iStar = 0
corrStar = corr[0]
for j in range(1, (ncols)):
if abs(corrStar) < abs(corr[j]):
iStar = j; corrStar = corr[j]
beta[iStar] += stepSize * corrStar / abs(corrStar)
betaMat.append(list(beta))
#Use beta just calculated to predict and accumulate out of
#sample error - not being used in the calc of beta
for j in range(nrowsTest):
labelsHat = sum([xTest[j][k] * beta[k] for k in range
(ncols)])
err = labelTest[j] - labelsHat
errors[iStep].append(err)
cvCurve = []
for errVect in errors:
mse = sum([x*x for x in errVect])/len(errVect)
cvCurve.append(mse)
minMse = min(cvCurve)
minPt = [i for i in range(len(cvCurve)) if cvCurve[i] == minMse ][0]
print("Minimum Mean Square Error", minMse)
print("Index of Minimum Mean Square Error", minPt)
xaxis = range(len(cvCurve))
plot.plot(xaxis, cvCurve)
plot.xlabel("Steps Taken")
plot.ylabel(("Mean Square Error"))
plot.show()
Printed Output:
('Minimum Mean Square Error', 0.5873018933136459)
('Index of Minimum Mean Square Error', 311)
利用交叉验证进行模型选择
代码清单 4-2 类似于代码清单 4-1。在交叉验证循环中(循环 nxval 次),这种差异逐渐变得清晰。在本例中,nxval=10,当然,nxval 可以设置为其他值。关于交叉验证份数的选择,如果份数较少,那么每次训练使用的数据也较少。如果设为 5 折,那么每次训练时会预留 20% 的数据。如果使用 10 折,只会留出 10% 的数据。正如第 3 章所看到的,在较少的数据上训练会降低算法的准确性。然而,切分份数过多也意味着在训练过程中需要多次遍历,这会显著增加训练时间。
在进行交叉验证循环前,首先初始化一个错误列表。该错误列表包含 LARS 算法中每一步迭代的错误。算法会对所有 10 折交叉验证的每折错误进行累加。在交叉验证循环中,你会看到训练集和测试集的生成过程。这里使用一个取模函数来定义这些集合。在有些情况下,需要使用分层抽样。例如要在一个非平衡数据集上构建分类器,其中某一类的样本点很少。如果希望训练集能够代表整个数据集,那么需要按照类来抽样数据,从而确保样本内和样本外的类大小比例一致。
你可能倾向于使用一个随机函数来定义训练集和测试集,但是要清楚数据集中的任何模式都可能影响抽样过程(即如果观测不是可交换的)。例如,如果数据是在每周的工作日进行采集,那么使用 5 折交叉验证的取余函数可能导致一个集合包含所有周一,另一个集合包含所有周二,等等。
在交叉验证的每一份数据上累加错误以及评估结果
一旦训练集和测试集定义好,LARS 算法的迭代就可以开始。该过程和代码清单 4-1类似,但也存在一些区别:首先,算法的基本迭代在训练集上展开,而不是在所有数据集上展开;其次,对于每次迭代,每份数据上的测试错误使用 \beta 当前值、数据属性以及数据标签计算得到,对应代码在交叉验证循环的最底端。β 每次更新时,在测试集上重复上述过程,将错误累加到“error”列表中,此后对每个列表进行平方取平均就变得简单。代码最终会生成一条曲线,曲线上的每个点与每次迭代的均方误差(MSE)值相对应,MSE 是在 10 份数据上得到的 MSE 的平均值。
你可能会担心测试数据是否被合理使用。一定要防止把测试数据引入训练过程,有多种方式可能会违背该限制。最主要的是,要确保测试数据不能在计算 β 的增量时使用,β 的增量计算只能使用训练数据。
关于模型选择以及训练次序的实际考虑
MSE 曲线与 LARS 迭代步数的关系如图 4-4 所示。该曲线展示了一个非常普遍的模式。基本上 MSE 随着迭代步数的增加而单调递减。严格来讲,从程序的输出来看,最小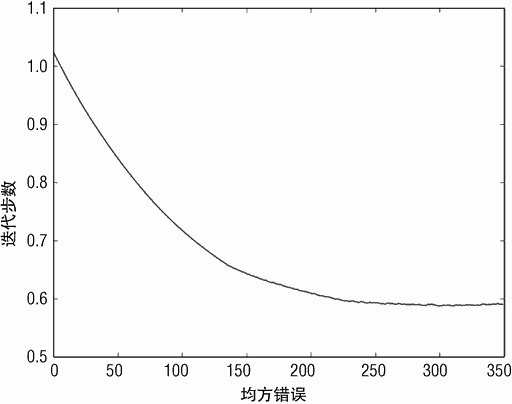
该曲线会在某个点上到达一个明显的最小值,往左或者往右都会显著增加。使用交叉验证来决定 350 个解中,LARS 生成的哪个解应该用于构建预测。在本例中,最小值在第 311步出现,β 的第 311 个系数集合可以用于实际部署。关于部署时具体使用哪个解,一般倾向于使用较为保守的方案。对于惩罚回归来讲,保守的解意味着系数值较小的解。按照惯例,对样本外性能,简单模型一般在左边,复杂模型一般在右边。简单模型往往有更好的泛化性能,即它们对新数据的预测更为准确。更保守的模型在样本外数据上的性能一般出现在图的左边。
代码中的 LARS 算法以及交叉验证首先遍历整个数据集,然后运行交叉验证。实际上,你很可能先运行交叉验证,然后在整个数据集上训练模型。交叉验证的目的是估计模型能够到达的 MSE 性能值,并了解数据集能够支持学习怎样复杂度的模型。如果你能回忆起来,第 3 章讨论过数据集大小以及模型复杂度的问题。交叉验证(或者其他基于预留数据进行性能评估)用来确定部署模型的复杂度。注意是复杂度而不是特定模型(即并不是 β 的特定取值)。正如在代码清单 4-2 中所看到的,使用 10 折交叉验证,实际训练了 10 个模型,在 10 个模型中,无法决定哪个是最佳模型。好的经验是在完整数据集上训练,使用交叉验证确定部署哪个模型。对于代码清单 4-2 中的例子,交叉验证在训练阶段的第 311步取到 MSE 的最小值 0.59。图 4-5 的系数曲线是在整个数据集上训练得到的。因为并不了解 350 个系数集合的哪一个(见图 4-5)应该被部署使用,所以使用交叉验证确定。交叉验证会生成对 MSE 的合理估计,告诉我们将第 311 个模型从训练集部署到整个数据集上。
4.3.4 使用 Glmnet :非常快速并且通用
glmnet 算法由 Jerome Friedman 教授以及他的同事们在斯坦福大学开发。glmnet 算法解决公式 4-11 给出的 ElasticNet 问题。回忆一下 ElasticNet 算法引入对惩罚函数的泛化,包括套索惩罚(绝对值加和)以及岭惩罚(平方和)。ElasticNet 通过参数 λ 来决定系数惩罚项相对于拟合错误的重要程度。算法同时包括参数 α,该参数用于决定惩罚项与岭回归(α=0)以及套索回归(α=1)的接近程度。glmnet 算法生成了完整的系数曲线,类似于LARS 算法。只要 LARS 算法将系数累加量加入 β,就能使曲线前进,glmnet 算法会稳定减少 λ 来推进系数曲线。公式 4-9 为 Friedman 论文中的关键公式:求解公式 11 中的权重系数的迭代公式——ElasticNet 公式。
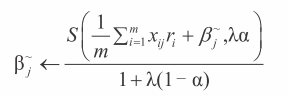
公式 4-9 对应于 Friedman 论文中的公式 5 与公式 8 的组合(假设你们对数学感兴趣)。看上去比较复杂,但是仔细观察会发现与上一节的 LARS 方法存在一定的关系和相似性。
Glmnet 与 LARS 算法工作原理的比较公式 4-9 为 β 更新的基本公式。LARS 更新公式是找到与残差关联最大的属性并小幅增加(减少)对应系数。修改后的公式 4-9 稍微麻烦一些。它使用一个箭头而不是一个等号。
箭头表示“被映射到”。注意到 βj
~出现在箭头的两边。箭头右侧是老的 βj~值,箭头左边(箭头所指方向)是 βj~的新值。经过若干次遍历(对应于公式 4-12 中的迭代),βj~停止改变,
此时算法针对给定的 λ 以及 α 收敛到了最终解。现在是时候讨论一下系数曲线了。
首先应该注意的是加和中的 xijri 项。xijri 在 i 上相加(即在数据的行上计算)生成了第 j 个属性与残差的关联。回忆一下 LARS 回归算法的每一步,计算每个属性与残差的关联。在 LARS 算法中,通过考虑所有关联值来确定哪个属性与残差的关联最大,增加关联最大的属性系数。使用 glmnet 算法,关联计算稍微不同。
使用 glmnet,与残差的关联用于计算系数的变化幅度。但是在 βj~改变前,需要遍历
函数 S()。函数 S() 是套索系数缩减函数。该函数在图 4-5 中绘制。正如你在图 4-5 看到的,如果第 1 个输入小于第 2 个输入,则输出为 0。如果第一个输入大于第 2 个输入,则输出变为第 1 个输入减去第 2 维度上的输入。这个称作软限制。
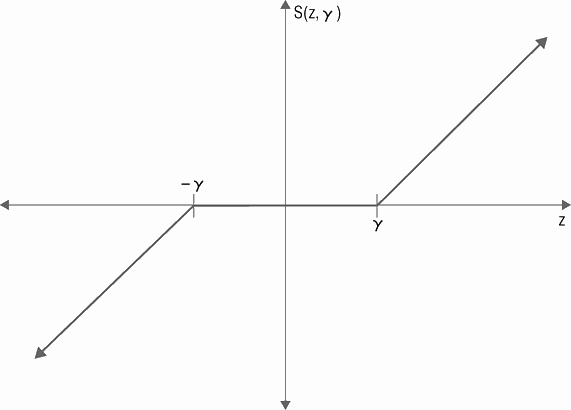
代码清单 4-3 为 glmnet 算法的代码。可以看到用于更新 β 的公式 4-12 是如何用来生成 ElasticNet 系数曲线的。代码清单 4-3 中的公式编号与 Friedman 论文一致。论文可以在网上找到,如果感兴趣可以查阅更多的数学细节。
初始化并且进行 Glmnet 算法的迭代迭代从一个较大的 λ 值开始。λ 足够大使得所有 β 等于 0。公式 4-9 给出如何计算 λ的起始点。对于公式 4-12 的函数 S(),如果第 1 个输入(xijri 的关联)小于第 2 个输入 -λα,则函数输出为 0。迭代从 β 都等于 0 开始,此时残差等于标签值。决定 lambda 初始值的流程为:首先计算每个属性与标签的关联,找到关联值最大的属性,使最大关联刚好等于 λα 来求解 λ 的值。这就是 λ 的最大值,该值导致 β 的所有值都等于 0。
接着迭代从减少 λ 开始,使用稍微小于 1 的系数乘以 λ 来完成。Friedman 建议乘子最好满足 λ^100 = 0.001,此时乘子大约等于 0.93。如果算法运行很长时间都没有收敛,那么增加 λ 的乘子使其接近于 1。Friedman 的代码实现将步长从 100 增加到 200,经过 200步使得起始点 λ 从 1 降为 0.001。在代码清单 4-3 中,可以直接控制乘子大小。系数曲线如图 4-8 所示。
代码清单 4-3 Glmnet 算法 -glmnetWine.py
__author__ = 'mike-bowles'
import urllib2
import numpy
from sklearn import datasets, linear_model
from math import sqrt
import matplotlib.pyplot as plot
def S(z, gamma):
if gamma >= abs(z):
return 0.0
return (z/abs(z))*(abs(z) - gamma)
#read data into iterable
target_url = ("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv")
data = urllib2.urlopen(target_url)
xList = []
labels = []
names = []
firstLine = True
for line in data:
if firstLine:
names = line.strip().split(";")
firstLine = False
else:
#split on semi-colon
row = line.strip().split(";")
#put labels in separate array
labels.append(float(row[-1]))
#remove label from row
row.pop()
#convert row to floats
floatRow = [float(num) for num in row]
xList.append(floatRow)
#Normalize columns in x and labels
nrows = len(xList)
ncols = len(xList[0])
#calculate means and variances
xMeans = []
xSD = []
for i in range(ncols):
col = [xList[j][i] for j in range(nrows)]
mean = sum(col)/nrows
xMeans.append(mean)
colDiff = [(xList[j][i] - mean) for j in range(nrows)]
sumSq = sum([colDiff[i] * colDiff[i] for i in range(nrows)])
stdDev = sqrt(sumSq/nrows)
xSD.append(stdDev)
#use calculate mean and standard deviation to normalize xList
xNormalized = []
for i in range(nrows):
rowNormalized = [(xList[i][j] - xMeans[j])/xSD[j]
for j in range(ncols)]
xNormalized.append(rowNormalized)
#Normalize labels
meanLabel = sum(labels)/nrows
sdLabel = sqrt(sum([(labels[i] - meanLabel) * (labels[i] -
meanLabel) for i in range(nrows)])/nrows)
labelNormalized = [(labels[i] - meanLabel)/sdLabel for i in
range(nrows)]
#select value for alpha parameter
alpha = 1.0
#make a pass through the data to determine value of lambda that
# just suppresses all coefficients.
#start with betas all equal to zero.
xy = [0.0]*ncols
for i in range(nrows):
for j in range(ncols):
xy[j] += xNormalized[i][j] * labelNormalized[i]
maxXY = 0.0
for i in range(ncols):
val = abs(xy[i])/nrows
if val > maxXY:
maxXY = val
#calculate starting value for lambda
lam = maxXY/alpha
#this value of lambda corresponds to beta = list of 0's
#initialize a vector of coefficients beta
beta = [0.0] * ncols
#initialize matrix of betas at each step
betaMat = []
betaMat.append(list(beta))
#begin iteration
nSteps = 100
lamMult = 0.93 #100 steps gives reduction by factor of 1000 in
# lambda (recommended by authors)
nzList = []
for iStep in range(nSteps):
#make lambda smaller so that some coefficient becomes non-zero
lam = lam * lamMult
deltaBeta = 100.0
eps = 0.01
iterStep = 0
betaInner = list(beta)
while deltaBeta > eps:
iterStep += 1
if iterStep > 100: break
#cycle through attributes and update one-at-a-time
#record starting value for comparison
betaStart = list(betaInner)
for iCol in range(ncols):
xyj = 0.0
for i in range(nrows):
#calculate residual with current value of beta
labelHat = sum([xNormalized[i][k]*betaInner[k]
for k in range(ncols)])
residual = labelNormalized[i] - labelHat
xyj += xNormalized[i][iCol] * residual
uncBeta = xyj/nrows + betaInner[iCol]
betaInner[iCol] = S(uncBeta, lam * alpha) / (1 +
lam * (1 - alpha))
sumDiff = sum([abs(betaInner[n] - betaStart[n])
for n in range(ncols)])
sumBeta = sum([abs(betaInner[n]) for n in range(ncols)])
deltaBeta = sumDiff/sumBeta
print(iStep, iterStep)
beta = betaInner
#add newly determined beta to list
betaMat.append(beta)
#keep track of the order in which the betas become non-zero
nzBeta = [index for index in range(ncols) if beta[index] != 0.0]
for q in nzBeta:
if (q in nzList) == False:
nzList.append(q)
#print out the ordered list of betas
nameList = [names[nzList[i]] for i in range(len(nzList))]
print(nameList)
nPts = len(betaMat)
for i in range(ncols):
#plot range of beta values for each attribute
coefCurve = [betaMat[k][i] for k in range(nPts)]
xaxis = range(nPts)
plot.plot(xaxis, coefCurve)
plot.xlabel("Steps Taken")
plot.ylabel(("Coefficient Values"))
plot.show()
#Printed Output:
#['"alcohol"', '"volatile acidity"', '"sulphates"',
#'"total sulfur dioxide"', '"chlorides"', '"fixed acidity"', '"pH"',
#'"free sulfur dioxide"', '"residual sugar"', '"citric acid"',
#'"density"']
图 4-8 为代码清单 4-3 生成的系数曲线。该曲线接近于 LARS 生成的曲线(见图 4-6),类似但不相同。LARS 以及套索常常生成相同曲线,但有时结果不同。决定哪种方法好的唯一方式是在样本外数据集上测试,观察哪种方法性能更好。
套索模型的开发过程与 LARS 算法相同,使用第 3 章的方法在样本外数据上进行测试(如 n 折交叉验证),基于样本外数据上的结果来决定模型的最优复杂度,然后在完整训练集上进行训练来构建系数曲线,从中挑出样本外性能最好的步长对应的解。
本章介绍了惩罚线性回归模型对应的两个最小化问题的求解方法。学习了这两个算法是如何工作的,以及它们之间的关系和实现细节。这些都为后续使用相关的 Python 代码包奠定基础,也便于理解第 5 章中关于模型的不同扩展方法。





本书评论