
4.2 惩罚线性回归:对线性回归进行正则化以获得最优性能
正如第 3 章所讨论的,本书解决了一类称作函数逼近的问题。训练模型的起始点是包含大量样本的数据集。每个实例包含结果以及大量用于预测结果的属性。第 3 章给出了一个简单的例子。表 4-1 为一个稍微修改的例子。
表 4-1 样例训练集
结果 | 特征1 | 特征2 | 特征3 |
2013年的花费 | 性别 | 2012年的划分 | 年龄 |
100 | M | 0 | 25 |
225 | F | 260 | 32 |
75 | F | 12 | 17 |
因为表 4-1 中的输出是实数值,所以该问题是一个回归问题。性别属性(特征 1)只能取 2 个值,所以该属性为类别属性(或者方面)属性。其他 2 个属性是数值属性。函数逼近的目标是:构建一个从属性到输出的函数;在某种意义下最小化错误。第 3 章讨论过一些其他的错误计算公式,这些备选方案都可以用于量化整体错误。
表 4-1 所示的数据集经常被表示为一个包含结果的列向量以及一个包含属性的矩阵(3列特征)。将结果列向量与矩阵合并在数学上容易混淆。严格来讲,矩阵包含的元素要定义在相同的数据类型上。矩阵内容可以是实数、整数、复数以及二元数字等,但它们不能是实数与类别变量的混合。
这里有一个要点需要记住:线性方法只能操作数值属性。表 4-1 中的数据包含非数值数据,因此线性方法不能直接应用。幸运的是,将表 4-1 中的数据转换为数值数据相对简单。
在 4.4.4 节中,我们会学习将类别属性转换为数值属性的编码技术。如果属性全部为实数值(不论是最初问题定义,还是通过将类别属性转换为实数值),那么线性回归问题的数据可以通过 2 个对象来表示:Y 和 X,其中 Y 是一个包含结果的列向量,X 是一个实数矩阵。
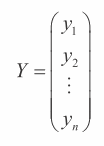
对于表 4-1 中的例子,Y 是结果列。
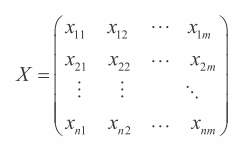
对于表 4-1 的例子,X 是将结果列排除后的剩余列集合。
Y(y_i)的第 i 个元素对应于 X 的第 i 行。X 的第 i 行使用包含下标的 x_i 表示,x_i=(x_i1,x_i2,x_im)。普通最小二乘法的目标是最小化 y_i 与 x_i(X 的第 i 行属性)的线性函数之间的错误,即找到实数向量 β 以及标量 β₀,从而使得来自 Y 的每个元素 y_i 可以通过公式 4-4 来近似。
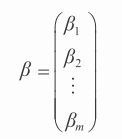
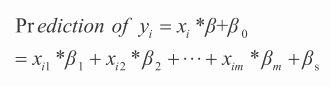
你也可以利用你的经验知识来寻找到 β 值。在表 4-1 中,可能你会觉得人们 2013 年会比 2012 年多消费 10 美元,即他们购买量年均增长 10%,甚至新生儿也会购买 50 美元的书。这些信息就可以构建图书消费的预测公式,类似公式 4-5。
2013 年的花销 = $50 + 1.1 *($ 2012 年的花销)+ $10 * Age公式 4-5 预测图书销售
公式 4-5 并不使用性别属性,因为它是一个类别变量(这方面处理会在“引入非数值属性到线性方法”中介绍,目前暂时忽略)。公式 4-5 生成的预测并不能精确匹配表 4-1中的结果(实际数量)。
4.2.1 训练线性模型:最小化错误以及更多
即使你能手动检查 β 的值,一般手动寻找 β 值也不是最佳方式。对于许多问题,变量数目以及变量间的关系使得猜测 β 的值不可行。所以一般方法是通过解最小化问题来找到属性乘子。最小化问题是找到使得均方误差最小(但不是 0)的 β 值。
公式 4-4 的两边完全相等就意味着模型已经过拟合。公式 4-4 的右侧是你要训练的预测模型。该模型的含义是:为了构建一个预测,把每一个属性乘以对应的系数,加起来再加一个常数。训练意味着找到构成向量 β 以及常量 β₀ 的数值。错误被定义为 yi 的实际值与 yi 的预测值之间的差异(见公式 4-4)。均方误差是将所有样本的错误归约到一个数。
之所以选择错误的平方是因为错误不区分正负,而平方函数从数学上求解更加方便。普通最小二乘法的定义变为找到 β* 以及 β₀*(上标 * 表明这些值是 β 的最佳值),能够满足公式 4-6。
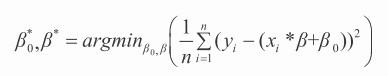
符号 argmin 是指“使表达式最小的参数”,加和是在行上进行,其中一行包括属性值以及对应的标签。()² 中的表达式是 yi 以及用于近似 yi 的线性函数值之间的错误。对于2013 年购书方面的花费预测,加和中的表达式对应于结果值减去通过公式 4-4 计算得到的预测值。
公式 4-6 可以用如下语言描述:向量 beta 是以及常量 beta 零星是使期望预测的均方错误最小的值,期望预测的均方错误是指在所有数据行(i=1,...,n)上计算 yi 与预测生成yi 之间的错误平方的平均。公式 4-5 的最小化生成了回归模型的最小均方误差值。该机器学习模型对应于一组实数,即向量 β* 以及标量 β₀* 中的数字。
4.2.2 向 OLS 公式中添加一个系数惩罚项
惩罚线性回归问题的数学声明非常类似于公式 4-5。第 3 章介绍岭回归时给出了惩罚线性回归的一个例子。岭回归向公式 4-5 的普通最小二乘法添加了一个惩罚项。岭回归的惩罚项如公式 4-7 所示。
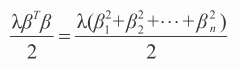
公式 4-6 的 OLS 问题是选择能最小化均方误差的 β。惩罚回归问题(即公式 4-7)向公式 4-6 的右侧添加系数惩罚项。最小化会考虑尽量平衡均方误差以及系数平方值,而这两方面的目标往往是相互矛盾的。只考虑系数本身很容易最小化系数平方:令每个系数都等于 0。但那样会导致较大的预测错误。类似地,OLS 的解可以使预测错误最小化,但可能导致系数惩罚项变大,取决于 λ 的值有多大。
为什么这样做是有意义的?为了加深理解,回想一下第 3 章的子集选择过程。子集选择通过丢弃一些属性来消除过拟合,实际等同于将这些属性的对应系数设为 0。惩罚回归做同样的事情,但与子集选择直接将一些属性系数设为 0 不同,惩罚线性回归将每个属性系数都减少一些。下面一些例子将帮助对该方法进行可视化。
参数 λ 的取值范围为 0 ~∞。如果 λ=0,惩罚项就消失了,问题变为普通最小二乘问题。
如果 λ →∞,关于 β 的惩罚就变得非常严格,会使 β 就趋近于 0。(注意到 β₀ 并没有包含在惩罚项中,所以预测变为一个常数值,与输入 x 无关)。
正如第 3 章例子所示,岭惩罚项也可以将一些属性排除在外。这个过程是通过为惩罚版的最小化问题生成一族解来实现的,即对不同的 λ 值都求解一个惩罚最小化问题。每一个解都在样本外数据上进行测试,能够最小化样本外错误的解作为最终解,用于后续预测。
第 3 章介绍了使用岭回归的一系列步骤。
4.2.3 其他有用的系数惩罚项:Manhattan 以及 ElasticNet
岭惩罚项对于惩罚回归来说并不是唯一有用的惩罚项。任何关于向量长度的指标都可以。使用不同的长度指标可以改变解的重要性。岭回归应用欧式几何的指标(即 β 的平方和)。另外一个有用的算法称作套索(Lasso)回归,该回归源于出租车的几何路径被称作曼哈顿距离或者 L1 正则化(即 β 的绝对值的和)。套索回归的一些属性非常有用。
岭回归以及套索回归的差异在于对 β(即线性系数向量)的惩罚上。岭回归使用欧式距离的平方,即 β 元素的平方和进行惩罚。套索使用 β 元素绝对值的加和:称作出租车或者曼哈顿距离。岭惩罚项是连接原点与空间点 β 的直线的长度平方。套索惩罚项类似于出租车在城市穿行需要正南正北或者正西正东的移动这样产生的距离。套索惩罚项的公式如下。
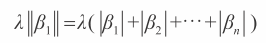
两条垂直线称作正则线。它们用于定义向量或者操作符的维度。正则线的脚标 1 称作l1 正则化,对应绝对值的和。常使用大写的 L1 来标记。脚标为 2 的正则线对应平方和的开方根——欧式距离。不同的系数惩罚函数在生成解时存在一些重要差异。一个主要差异是:套索的系数向量 β* 是稀疏的,意味着对于不同的 λ 值,许多系数等于 0。相比之下,岭回归 β* 向量值是密集的,大部分不等于 0。
4.2.4 为什么套索惩罚会导致稀疏的系数向量
稀疏性与系数惩罚函数的直接关系如图 4-1 和图 4-2 所示。这些图是针对含有 2 个属性 x1 与 x2 的问题。
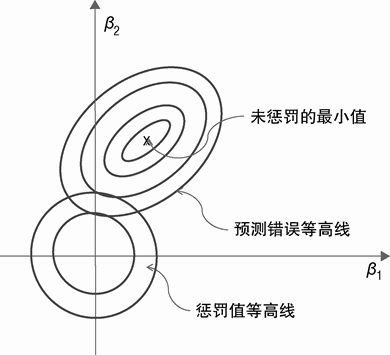
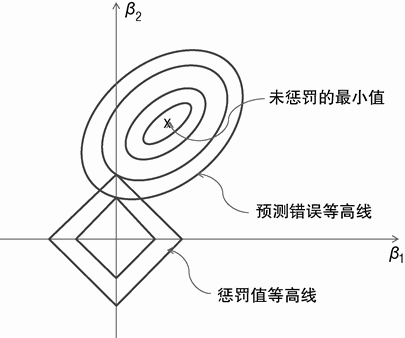
图 4-1 与图 4-2 包含 2 组曲线集合。一组曲线集合是同心椭圆,代表公式 4-6 中的最小均方误差。椭圆代表等高线,线上的均方和为常数。可以将这些椭圆想象为地面上呈椭圆凹陷的地图。对于更接近于中心的椭圆,错误会变小,正如凹陷的海拔高度会随凹陷方向变小。凹陷的最小点使用 x 进行标记。在没有系数惩罚项时,该点对应于最小二乘法的解。
图 4-1 及图 4-2 的曲线集合代表公式 4-7 和公式 4-9 的系数惩罚项,分别是岭惩罚项和套索惩罚项。在图 4-1 中,代表系数惩罚项的曲线是以原点为中心的圆。平方和等于常量,限定了 β₁ 以及 β₂ 是位于圆上的点。常数惩罚项的曲线形状由使用的距离性质决定:基于平方和的惩罚项对应于圆(称作超球面或者高维空间的 l2 球面),基于绝对值和的惩罚项对应于菱形(或者 l1 球面)。小的圆(或者菱形)对应于较小的距离函数。形状虽然由惩罚函数的性质决定,但是每条曲线关联的值由非负参数 λ 来决定。假设图 4-1 中的2 条曲线分别对应平方和(β₁、β₂)为 1.0 和 2.0 的情况。如果 λ =1,那么和 2 个圆圈关联的惩罚项为 1 和 2。如果 λ =10,那么关联的惩罚项为 10 和 20。图 4-2 中的菱形结果也相同。增加 λ 也会增加与图 4-2 相关的惩罚项。
椭圆环(对应于预测错误平方)离不受限的最小值(图中的 x 标记)越远,椭圆环也变得越大。正如公式 4-6 所示,最小化这 2 个函数的和对应于在预测错误最小化以及系数惩罚最小化之间寻求一种平衡。较大的 λ 值会更多地考虑最小化惩罚项(所有系数为 0)。
较小的 λ 值会使得最小值接近于不受限的最小预测错误(图 4-1 及图 4-2 的 x)。
这就是系数平方和的惩罚项与绝对值和的惩罚项之间的区别。公式 4-6 以及公式 4-8的最小值往往会落在惩罚常数曲线与预测错误曲线的切点上。图 4-1 与图 4-2 为相切的 2个例子。重要一点是在图 4-1 中,随着 λ 变化以及最小点的移动,平方惩罚项产生的切点一般不会落在坐标轴上。β₁ 与 β₂ 都不为 0。相比之下,在图 4-2 中,绝对值和惩罚项产生的切点落在了 β₂ 的轴上。在 β₂ 轴上,β₁=0。
一个稀疏的系数向量相当于算法告诉你可以忽略一些因变量。当 λ 足够小时,β₂ 与 β₁的最优值会远离 β₂ 轴,这 2 个值都是非 0 值。较小的惩罚项会使得 β₁ 不等于 0,给出了β₂ 与 β₁ 的顺序。从某种意义上讲,β₂ 要比 β₁ 重要,因为随着 λ 变大,β₂ 的值不等于 0。
回想一下这些系数会乘以属性。如果对应于属性的系数为 0,算法告诉你该属性的重要性要差于非 0 的属性。通过从大到小遍历 λ 值,就可以根据重要性对属性进行排序。下一节会通过一个具体例子来说明,并提供 Python 代码比较属性的重要性,而属性重要性是公式 4-8 求解的一部分。
4.2.5 ElasticNet 惩罚项包含套索惩罚项以及岭惩罚项
在了解如何计算这些系数之前,需要知道惩罚回归问题的泛化定义,即 ElasticNet 形式化。惩罚回归问题的 ElasticNet 形式是使用一个可调节的岭回归以及套索回归的混合。
ElasticNet 引入一个额外参数 α 用于控制岭惩罚项以及套索惩罚项的比例。α =1 表示只使用套索惩罚,不使用岭惩罚。使用 ElasticNet 形式,在求解线性模型系数之前,λ 以及 α必须提前确定。一般来讲,确定 λ 以及 α 参数的方法是先确定 α 值,然后尝试使用不同的λ 值。会在后续看到这样计算的原因。
在许多情况下,对 α =1、α =0 或者一些中间值的 α,算法性能差异并不大。但有时差异会很明显,这就需要选择不同的 α 值来确保不必要的性能牺牲。





本书评论