
3.3 度量预测模型性能
本节介绍针对预测模型进行性能度量的两个方面。第一个方面是对不同问题使用不同指标(如对回归问题使用 MSE、对分类问题使用误分类率)。在相关文献(以及机器学习竞赛)中,也可以看到使用 ROC 曲线以及曲线下面积(AUC)的评价指标。除了评价,这些指标对于性能优化也很重要。
第二个方面是在预留样本上进行错误估计的技术。预留样本错误是指在新数据上的错误率。如何利用上述技术来进行算法比较和模型选择是实践的重要问题。本章后续会对技术进行详细讨论,并且之后使用的例子也遵照该过程。
3.3.1 不同类型问题的性能评价指标
回归问题使用的性能指标相对比较直观。在回归问题中,真实目标以及预测值都是实数。错误很自然地被定义为目标值与预测值的差异。生成错误的统计摘要对性能比较以及问题诊断都非常有用。最常用的错误摘要是均方误差(MSE)以及平均绝对错误(MAE)。
MSE、MAE 以及根 MSE(也写作 RMSE,即 MSE 的平方根)的比较如代码清单 3-1 所示。
代码清单 3-1 MSE、MAE 以及 RMSE- regressionErrorMeasures.py
__author__ = 'mike-bowles'
#here are some made-up numbers to start with
target = [1.5, 2.1, 3.3, -4.7, -2.3, 0.75]
prediction = [0.5, 1.5, 2.1, -2.2, 0.1, -0.5]
error = []
for i in range(len(target)):
error.append(target[i] - prediction[i])
#print the errors
print("Errors ",)
print(error)
#ans: [1.0, 0.60000000000000009, 1.1999999999999997, -2.5,
#-2.3999999999999999, 1.25]
#calculate the squared errors and absolute value of errors
squaredError = []
absError = []
for val in error:
squaredError.append(val*val)
absError.append(abs(val))
#print squared errors and absolute value of errors
print("Squared Error")
print(squaredError)
#ans: [1.0, 0.3600000000000001, 1.4399999999999993, 6.25,
#5.7599999999999998, 1.5625]
print("Absolute Value of Error")
print(absError)
#ans: [1.0, 0.60000000000000009, 1.1999999999999997, 2.5,
#2.3999999999999999, 1.25]
#calculate and print mean squared error MSE
print("MSE = ", sum(squaredError)/len(squaredError))
#ans: 2.72875
from math import sqrt
#calculate and print square root of MSE (RMSE)
print("RMSE = ", sqrt(sum(squaredError)/len(squaredError)))
#ans: 1.65189285367
#calculate and print mean absolute error MAE
print("MAE = ", sum(absError)/len(absError))
#ans: 1.49166666667
#compare MSE to target variance
targetDeviation = []
targetMean = sum(target)/len(target)
for val in target:
targetDeviation.append((val - targetMean)*(val - targetMean))
#print the target variance
print("Target Variance = ", sum(targetDeviation)/len(targetDeviation))
#ans: 7.5703472222222219
#print the the target standard deviation (square root of variance)
print("Target Standard Deviation = ", sqrt(sum(targetDeviation)
/len(targetDeviation)))
#ans: 2.7514263977475797
本例从一组构造的目标值与预测值开始。首先,通过简单相减来计算错误;然后给出了 MSE、MAE 以及 RMSE 的计算方法。注意到 MSE 在量级上与 MAE 及 RMSE 都明显不同。这是因为 MSE 是平方级别。从这个角度讲,RMSE 是一个可用性更好的指标。代码清单最后是方差的计算(与均值的均方误差)以及标准差计算(方差的开方)。这些量与预测错误指标 MSE 以及 RMSE 进行比较非常有意义。例如,如果预测错误的 MSE 同目标方差几乎相等(或者 RMSE 与目标标准差几乎相等),这说明预测算法效果并不好,通过简单对目标值求平均来替换预测算法就能达到几乎相同的效果。代码清单 3-1 中所示的预测错误 RMSE 大约是实际目标标准差的一半。这已经是一个相当不错的性能。
除了计算错误的摘要统计量以外,查看错误的分布直方图、长尾分布(使用分位数或者等分边界)以及正态分布程度等对于分析错误原因以及错误程度也非常有用。有时这些探索会对定位错误原因以及提升潜在性能带来启发。
分类问题需要不同对待。分类问题的评价方法一般围绕误分类率展开,即错分的样本所占的比例。例如,预测网站访问者是否会点击链接是一个分类问题。分类算法可以给出预测概率,而不是硬的决策(输出结果只有点击以及未点击)。本书讨论的算法都会输出概率。
下面展示为什么概率是有用的。如果点击或者不点击的预测结果以概率的方式给出,假设 80% 的情况下会点击(对应的 20% 的情况不点击),数据科学家可以选择 50% 作为一个阈值来决定是否呈现链接。在一些情况下,设置更高或者更低的阈值会给出更好的预测结果。
假设问题是欺诈检测(对于信用卡、自动票据交换(支票)、保险索赔等)。判断是否欺诈需要有电话座席员人工介入交易来放行。不同决策对应不同代价:如果产生了电话,就会有电话费以及客户响应的代价;如果没有电话,就存在被欺诈的代价。如果采取行动的代价相对于不采取行动的代价非常低,此时可以使用低的阈值来决定是否采取行动,从而欺诈代价就比较低,但同时会有更多的人工介入。
那么在什么时候应该介入客户提现,要求其必须致电信用卡服务中心来完成后续操作?当算法得到此笔交易存在欺诈的概率为 20%、50% 或者 80% 的概率时,开始介入交易?如果设置介入的阈值为 20%,你会更加频繁地介入,避免更多的欺诈交易,但同时也会激怒更多客户以及增加坐席代表工作负担。或许将阈值设高(如 80%)来容忍更多的欺诈是一个更好的策略。
对于这种情况,一般使用混淆矩阵(confusion matrix)或者列联表(contingency table)来安排可能的结果输出。图 3-9 为混淆矩阵的一个例子。混淆矩阵中的数字表示基于指定阈值进行决策所产生的性能值。图 3-9 中的混淆矩阵是基于特定的阈值对 135 个测试样例进行预测后的结果。矩阵中的 2 列代表可能的预测值,2 行表示每个样本可能取到的真实值。所以测试集中的每个样本可以被分配到表中 4 个单元中的一个。图 3-9 的 2 类对应于“点击”以及“未点击”,该分类结果用于选择是否呈现广告。2 类也可以对应于“欺诈”以及“非欺诈”,或者其他结果对,这取决于要解决的问题。
| 预测类 | |||
| 实际类 | 正例(点击) | 负例(未点击) | |
正(点击) | 真正(TP) | 假负(FN) | |
负(未点击) | 假正(FP) | 真负(TN) | |
图 3-9 混淆矩阵的样例
左上角的单元格包含预测结果为点击并且预测标签与真实类别标签一致的样本。这些样本称作真正例,一般简写为 TP。左下部分的单元格对应预测是正的(点击),但是实际答案是负的(未点击)。这些样本称作假正例,简写为 FP。矩阵右侧的列包含预测结果为未点击的样本。右上角样本的正确答案是点击因此被称作假负例或者 FN。右下角的样本被预测为未点击,与正确答案一致,称作真负例或者 TN。
如果决策阈值改变会发生什么?考虑一种极端情况。将决策阈值设为 0.0,不论模型预测的概率是多少,结果都会被认为是点击。此时所有样本都会挤到左边一列。右边一列只有 0。TP 的数量会变为 17。FP 的数量会变为 118。如果对 FP 没有惩罚,TN 没有奖励,这种方案还说得下去,但如果假设样本都是点击的话,就不需要预测算法了。类似地,如果对 FN 没有惩罚,对 TP 没有奖励,阈值可以设为 1.0,这样所有的样本被分类为未点击。通过这些极端例子可以帮助我们理解决策阈值的作用,但对实际应用用处不大。下面我们将展示在岩石 - 水雷数据集上构建分类器的过程。
岩石 - 水雷数据集对应的问题是使用声纳数据来判断海底物体是岩石还是水雷(如果想全面讨论或者探究数据集,参照第 2 章)。代码清单 3-2 为在岩石 - 水雷数据集上训练简单分类器的 Python 代码。
代码清单 3-2 在岩石 - 水雷数据集上度量分类器性能
__author__ = 'mike-bowles'
#use scikit learn package to build classified on rocks-versus-mines data
#assess classifier performance
import urllib2
import numpy
import random
from sklearn import datasets, linear_model
from sklearn.metrics import roc_curve, auc
import pylab as pl
def confusionMatrix(predicted, actual, threshold):
if len(predicted) != len(actual): return -1
tp = 0.0
fp = 0.0
tn = 0.0
fn = 0.0
for i in range(len(actual)):
if actual[i] > 0.5: #labels that are 1.0 (positive examples)
if predicted[i] > threshold:
tp += 1.0 #correctly predicted positive
else:
fn += 1.0 #incorrectly predicted negative
else: #labels that are 0.0 (negative examples)
if predicted[i] < threshold:
tn += 1.0 #correctly predicted negative
else:
fp += 1.0 #incorrectly predicted positive
rtn = [tp, fn, fp, tn]
return rtn
#read in the rocks versus mines data set from uci.edu data repository
target_url = ("https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data")
data = urllib2.urlopen(target_url)
#arrange data into list for labels and list of lists for attributes
xList = []
labels = []
for line in data:
#split on comma
row = line.strip().split(",")
#assign label 1.0 for "M" and 0.0 for "R"
if(row[-1] == 'M'):
labels.append(1.0)
else:
labels.append(0.0)
#remove lable from row
row.pop()
#convert row to floats
floatRow = [float(num) for num in row]
xList.append(floatRow)
#divide attribute matrix and label vector into training(2/3 of data)
#and test sets (1/3 of data)
indices = range(len(xList))
xListTest = [xList[i] for i in indices if i%3 == 0 ]
xListTrain = [xList[i] for i in indices if i%3 != 0 ]
labelsTest = [labels[i] for i in indices if i%3 == 0]
labelsTrain = [labels[i] for i in indices if i%3 != 0]
#form list of list input into numpy arrays to match input class
#for scikit-learn linear model
xTrain = numpy.array(xListTrain); yTrain = numpy.array(labelsTrain)
xTest = numpy.array(xListTest); yTest = numpy.array(labelsTest)
#check shapes to see what they look like
print("Shape of xTrain array", xTrain.shape)
print("Shape of yTrain array", yTrain.shape)
print("Shape of xTest array", xTest.shape)
print("Shape of yTest array", yTest.shape)
#train linear regression model
rocksVMinesModel = linear_model.LinearRegression()
rocksVMinesModel.fit(xTrain,yTrain)
#generate predictions on in-sample error
trainingPredictions = rocksVMinesModel.predict(xTrain)
print("Some values predicted by model", trainingPredictions[0:5],
trainingPredictions[-6:-1])
#generate confusion matrix for predictions on training set (in-sample
confusionMatTrain = confusionMatrix(trainingPredictions, yTrain, 0.5)
#pick threshold value and generate confusion matrix entries
tp = confusionMatTrain[0]; fn = confusionMatTrain[1]
fp = confusionMatTrain[2]; tn = confusionMatTrain[3]
print("tp = " + str(tp) + "\tfn = " + str(fn) + "\n" + "fp = " +
str(fp) + "\ttn = " + str(tn) + '\n')
#generate predictions on out-of-sample data
testPredictions = rocksVMinesModel.predict(xTest)
#generate confusion matrix from predictions on out-of-sample data
conMatTest = confusionMatrix(testPredictions, yTest, 0.5)
#pick threshold value and generate confusion matrix entries
tp = conMatTest[0]; fn = conMatTest[1]
fp = conMatTest[2]; tn = conMatTest[3]
print("tp = " + str(tp) + "\tfn = " + str(fn) + "\n" + "fp = " +
str(fp) + "\ttn = " + str(tn) + '\n')
#generate ROC curve for in-sample
fpr, tpr, thresholds = roc_curve(yTrain,trainingPredictions)
roc_auc = auc(fpr, tpr)
print( 'AUC for in-sample ROC curve: %f' % roc_auc)
# Plot ROC curve
pl.clf()
pl.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
pl.plot([0, 1], [0, 1], 'k–')
pl.xlim([0.0, 1.0])
pl.ylim([0.0, 1.0])
pl.xlabel('False Positive Rate')
pl.ylabel('True Positive Rate')
pl.title('In sample ROC rocks versus mines')
pl.legend(loc="lower right")
pl.show()
#generate ROC curve for out-of-sample
fpr, tpr, thresholds = roc_curve(yTest,testPredictions)
roc_auc = auc(fpr, tpr)
print( 'AUC for out-of-sample ROC curve: %f' % roc_auc)
# Plot ROC curve
pl.clf()
pl.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
pl.plot([0, 1], [0, 1], 'k–')
pl.xlim([0.0, 1.0])
pl.ylim([0.0, 1.0])
pl.xlabel('False Positive Rate')
pl.ylabel('True Positive Rate')
pl.title('Out-of-sample ROC rocks versus mines')
pl.legend(loc="lower right")
pl.show()
代码第一部分将 Irvine 数据集读入并将其解析为包含标签与属性的记录。下一步将数据划分为 2 个子集:测试集包含 1/3 的数据,训练集包含剩下 2/3 的数据。标注为 test 的数据集不能用于训练分类器,但会被保留用于评估训练得到的分类器性能。这一步用来模拟分类器在新数据样本上的行为。稍后本章将会讨论用于预留数据的方法,并在新数据集上对性能进行评估。
分类器的训练通过将标签 M(代表水雷)以及标签 R(代表岩石)转换为 2 个数值:
1.0 对应于矿产,0.0 对应于岩石,然后使用最小二乘法来拟合一个线性模型。上面方法理解实现起来都非常简单,性能也接近于后续讨论的更加复杂的方法。代码清单 3-2 中的程序使用 scikit-learn 中的线性回归包来训练普通的最小均方模型。训练的模型用于在训练集和测试上生成预测。
代码会打印一些预测值的样例。线性回归模型产生的预测大部分集中在 0.0 到 1.0,然而也并非全部。这些预测不只是概率。仍然可以将它们与决策阈值进行比较来生成分类标签。函数 confusionMatrix() 生成了混淆矩阵,类似于图 3-9。该函数以预测值、对应的实际标签以及决策阈值作为输入。函数将预测值与决策阈值进行比较来决定为每个样本赋“正值”或者“负值”,预测值对应于混淆矩阵中的列。函数再根据样本的实际标签将样本放在对应的行中。
每个决策阈值的错误率都可以从混淆矩阵中计算得到。总的错误数为FP与FN的加和。
样例代码分别在训练集以及测试集上计算混淆矩阵,并且打印出来。在训练集上误分类率为 8%,在测试集上误分类率为 26%。一般来讲,测试集上的性能要差于训练集上的性能。
在测试集上的结果更能代表错误率。
当决策阈值改变的话,误分类率也会改变。表 3-2 显示随着决策阈值的变化,误分类率的变化情况。表中数字基于测试集计算得到。书中后续所有性能描述都是基于测试集的结果。如果错误基于训练集,书中会有提示:“警告:这些是在训练集上得到的错误”。如果目标是最小化误分类错误,那么最佳的决策阈值应该设为 0.25。
表 3-2 决策阈值对误分类率的影响
决策阈值 | 误分类率 |
0 | 28.6% |
0.25 | 24.3% |
0.5 | 25.7% |
0.75 | 30.0% |
1.0 | 38.6% |
最佳决策阈值应该是能够最小化误分类率的值。然而,不同类错误对应的代价可能是不同的。例如,对于岩石 - 水雷预测问题,如果将岩石预测为水雷,可能会花费 $100 请潜水员下水确认;如果将水雷预测为岩石,那么未爆炸的水雷不移除的话可能会导致 $1,000美元的人身财产损失。一个 FP 的样本代价为 100,一个 FN 的样本代价为 1,000。有了这样的假设,不同决策阈值生成的错误代价如表 3-3 所示。将水雷误分类为岩石(不对其进行处理可能会威胁到健康安全)的高代价会使最优决策阈值趋向于 0。这意味着会产生更多 FN,因为 FN 的代价不高。一项完整的分析应该包括移除水雷的代价以及随着移除带来的 1,000 美元的好处。如果这些数值已经知道(或者接近于合理近似),它们理应在计算阈值时考虑。
表 3-3 不同决策阈值的错误代价
决策阈值 | 假负例的代价 | 假正例的代价 | 总代价 |
0.0 | 1000 | 1900 | 2900 |
0.25 | 3000 | 1400 | 4400 |
0.5 | 9000 | 900 | 9900 |
0.75 | 18000 | 300 | 18300 |
1.00 | 26000 | 100 | 26100 |
注意到总的 FP 以及 FN 的相对代价取决于数据集中正例与负例的比例。岩石 - 水雷数据集有相同数量的正例与负例(岩石和水雷)。这些都是实验中的常用假设。实际遇到的正例数和负例数可能完全不同。在系统部署场景下,如果正负例数目不同,就可能要基于实际应用比例做一些调整。
数据科学家可能并没有关于正负样本误分的具体代价值,但仍然想使用除了误分类率外的其他刻画错误的方法。一种常见的指标被称作接收者操作曲线或者 ROC 曲线(http://en.wikipedia.org/wiki/Receiver_operating_characteristic)。
ROC 从其初始应用中继承了对应的名字:通过处理雷达信号来判断是否有敌机出现。
ROC 曲线使用一个图来展示不同的列联表,图中绘制的是真正率(简写为 TPR)随假正率(FPR)的变化情况。TPR 代表被正确分类的正样本比例(参见公式 3-8)。FPR 是 FP 相对于实际负样本的比例(参见公式 3-9)。从列联表的元素来看,这些值通过下面的公式计算得到。
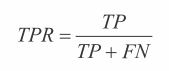
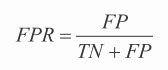
简单想一下,如果决策阈值使用非常小的值,那么每个样本都会被预测为正例。
此时,TPR=1.0。因为每个样本都被分类为正例,没有假负例(FN=0.0)。FPR=1.0 因为没有例子被分类为负例(TN=0.0)。然而当决策阈值设得很高,TP=0,那么 TPR=0,FP=0,因为没有样本被分类为正例。因此,FPR=0。图 3-10 和图 3-11 使用 pylab roc_curve() 以及auc() 函数。图 3-10 为基于训练集得到的 ROC 性能曲线。图 3-11 为测试集上的 ROC 性能曲线。
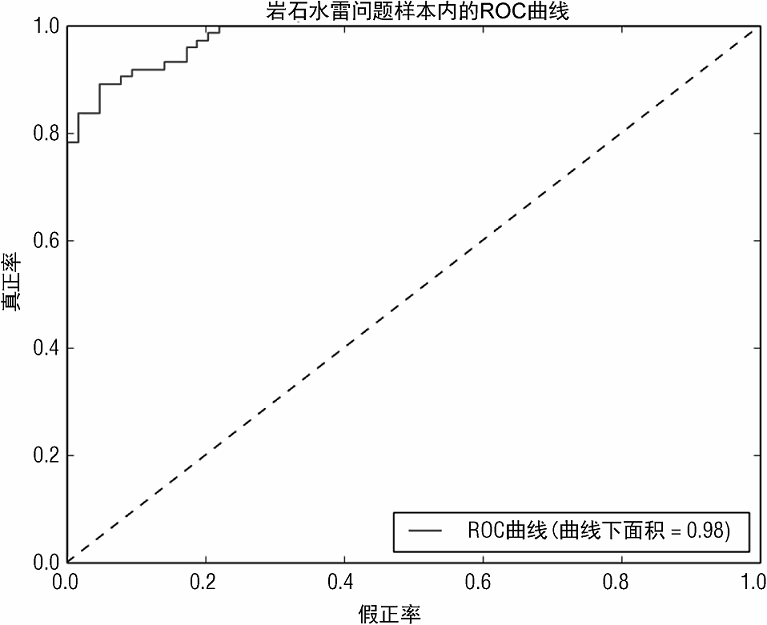
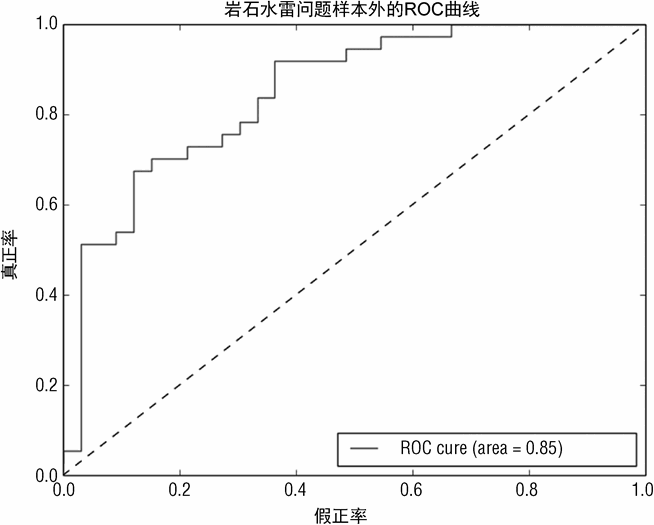
如果分类器(针对岩石 - 水雷问题)为随机分类,ROC 的样子为一条从左下角到右上角的对角线。这条对角线一般画在图里作为参照点。对于一个完美的分类器,ROC 曲线应该是直接从(0,0)上升到(0,1),然后横着连到(1,1)的直线。显然,图 3-10(在测试集上的结果)要比图 3-11 更接近于完美答案。分类器越接近于左上角,效果越好。
如果 ROC 曲线掉到对角线下边,这一般表示数据科学家有可能把预测符号弄反了,此时应该认真检查代码。
图 3-10 和图 3-11 同样展示了曲线下的面积值(AUC)。AUC 正如名字所表达的,指的是 ROC 曲线下的面积。一个完美分类器的 AUC=1.0,随机猜测分类器对应的 AUC 为0.5。图 3-10 和图 3-11 的 AUC 证明基于训练集进行错误估计往往会高估性能。训练集上的 AUC=0.98,测试集上的 AUC=0.85。
一些用于估算 2 分类问题性能的方法同样适用于多分类问题。误分类错误仍然有意义,混淆矩阵也同样适用。有许多将 ROC 曲线以及 AUC 指标推广到多分类应用的工作。
3.3.2 部署模型的性能模拟
前一节的例子展示了性能评估不能基于训练集进行计算。例子将数据切分为 2 个子集。
第一个子集称作训练集,包含 2/3 的可用数据,用于拟合一个普通的最小均方模型。第 2个子集包含剩下 1/3 的数据,称作测试集,用于评估性能(不在模型训练中使用)。对于机器学习,以上步骤是一个标准流程。
尽管目前没有明确规则来确定测试集的大小,一般测试集可以占所有数据的25% ~ 35%。要记住模型训练的性能随着训练集规模的减小而下降。将过多数据从训练集中去掉会影响模型性能估计。
另一种预留数据的方法被称作 n 折交叉验证。图 3-12 展示了如何基于 n 折交叉验证来对数据进行切分。数据集被等分为 n 份不相交的子集。训练和测试需要多次遍历数据。图 3-12中的 n=5。第一次遍历是,数据的第一块被预留用于测试,剩下 n-1 块用于训练。第 2 遍,第 2 块被预留做测试,剩下 n-1 块用于训练。
该过程继续,直到所有数据都被预留一遍(对于图 3-12,5 折交叉验证的样例中,数据会被扫描 5 次)。
n 折交叉验证可以估计预测错误:在多份样本上估计错误来估计错误边界。通过为训练集分配更多样本,生成的模型会产生更低的泛化错误,具备更好的预测性能。例如,如果选择 10 折交叉验证,每次训练只需要留出 10% 的数据进行预测。n 折交叉验证是以更多的训练时间作为代价。保留一个固定的集合作为测试集可以有更快的训练速度,因为它只需要扫描一遍训练数据。当使用 n 折交叉验证的训练时间不可忍受时,使用预留测试集是一个更好的选择,而且如果训练数据很多的话,留一些数据出来不会对模型性能造成太大影响。
另一件值得注意的是测试样本应该能代表整个数据集。上一节例子使用的抽样样本不完全是一个随机样本。它是每隔 3 个样本选 1 个作为测试样本。类似上面方法,通过均匀采样一般足够用了。但必须避免采样过程给训练集和测试集引入偏差。例如,给一类数据,该数据每天生成一个,数据按照采样日期排列,那么 7 折交叉验证使用每隔 7 个点抽样一个点的方法就不正确。
如果研究现象有特殊的统计特征,抽样过程可能要更加小心。此时需要注意在测试样本中保留统计特征。这类例子包括对稀疏事件(如欺诈或者广告点击)进行预测。要建模的事件出现频率非常少,随机抽样可能导致有过多或者过少的样本出现在测试集中,同时导致对性能的错误估计。分层抽样(http://en.wikipedia.org/wiki/Stratified_sampling)将数据切分为不同子集,分别在子集中进行抽样然后组合。如果类别标签对应罕见事件,可能需要分别从欺诈样本以及合法样本中抽样,然后组成测试集。更重要的是,这样的数据就是模型最终要运行的数据。
模型经过训练和测试,那么还应该将训练集和测试集再合并为一个更大的集合,重新在该集合上训练模型。样本外测试已经可以给出预测错误的期望结果。这就是为什么要预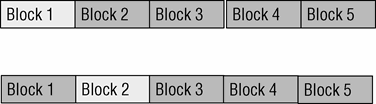
留一部分数据的原因。如果能在更多数据上进行训练,模型效果会更好,泛化能力也更好。
真正要部署的模型应该在所有数据上进行训练。本节将提供一些工具来量化模型的预测性能。针对模型以及问题复杂度,下一节将介绍如何使用数值比较来替换图形比较。这种替换使得模型选择过程变得规范。





本书评论