
3.2 影响算法选择及性能的因素——复杂度以及数据
有几个因素影响预测算法的整体性能。这些因素包括问题的复杂度、模型复杂度以及可用的训练数据量。下面将介绍这些因素是如何一起来影响预测性能的。
3.2.1 简单问题和复杂问题的对比
前面小节的内容介绍了性能评估的几种方式,强调模型在新数据上的性能表现更为重要。设计预测模型的目标是在新样本上(如网站新用户)预测准确。应用数据科学家需要对算法性能进行评估,从而为客户提供合理的期望并且对算法进行比较。对模型进行评估的最佳经验是从训练数据集中预留部分数据。
这些预留的数据包含类别标签,从而可以与模型生成的预测结果进行比对。统计学家将这种比对结果称作样本外误差,因为计算误差的样本并没有在训练中用到(3.3 节会深入讨论该过程的运行机制)。记住只有在新样本上计算得到的性能才能算是模型的性能。
影响性能的一个因素是问题复杂度。图 3-1 展示了一个简单的 2 分类问题,输入包含2 个维度。有 2 组数据点:深色的点和浅色的点。深色数据点是随机从二维高斯分布中抽样,中心在(1,0),方法是 2 个方向的单位方差。浅色的点也是从高斯分布中抽样,有相同的方差,但是中心在(0,1)。问题的输入属性对应图 3-1 中的 2 个坐标轴:x1 以及 x2。分类任务对应于在 x1,x2 的二维平面上画一条分界线来分离浅色点以及深色点。在这种情况下,最好的解决方案是在图中画一个 45 度线,即 x1=x2 的直线。从概率意义上讲,这是最好的分类器。因为一条直线尽可能地分离了浅色点以及深色点。本书要介绍的线性方法将会很好地解决该问题。
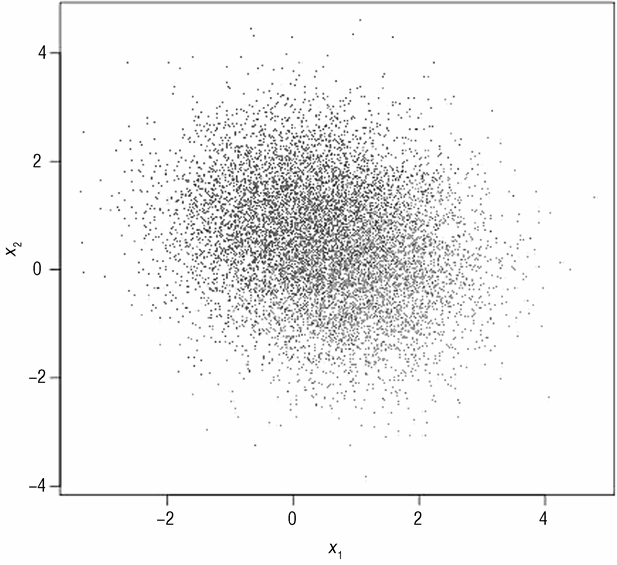
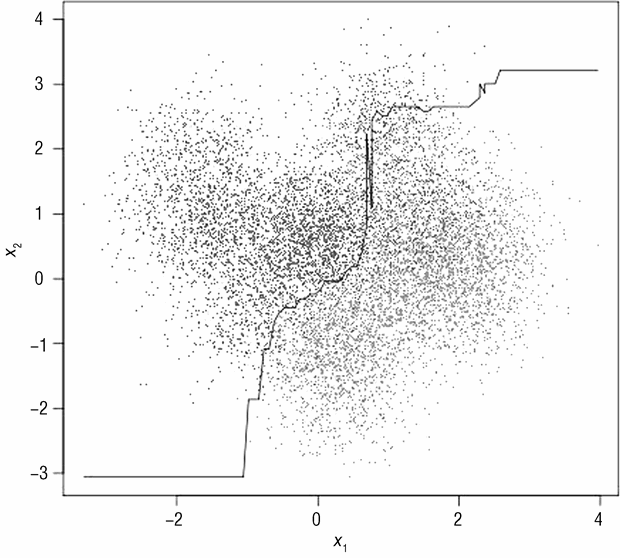
图 3-2 展示了一个更加复杂的问题。图中的点通过随机抽样来生成。与图 3-1 中的随机抽样不同,图 3-2 中的点从多个浅色点以及深色点的分布中抽样,这种生成数据的模型被称作混合模型。不过这两个问题的总体目标是相同的:在 x1,x2 的平面上画一条边界来分离浅色点与深色点。在图 3-2 中,很明显一条线性边界不能将点分离,一条曲线也不能分离。第 6 章中提到的集成方法可以很好地解决该问题。
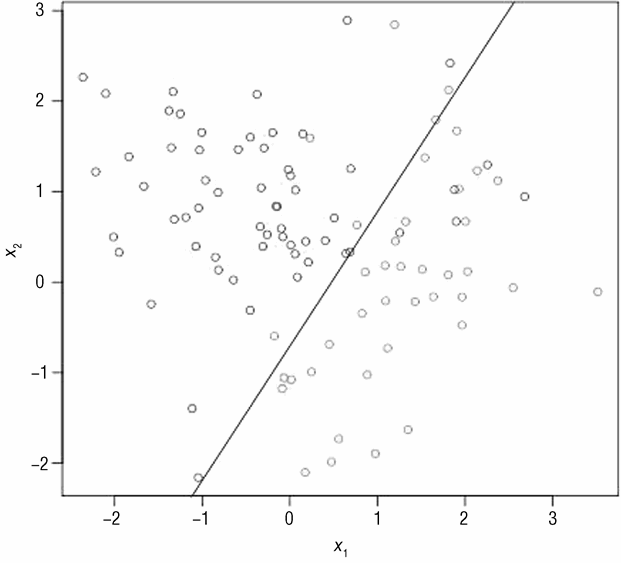
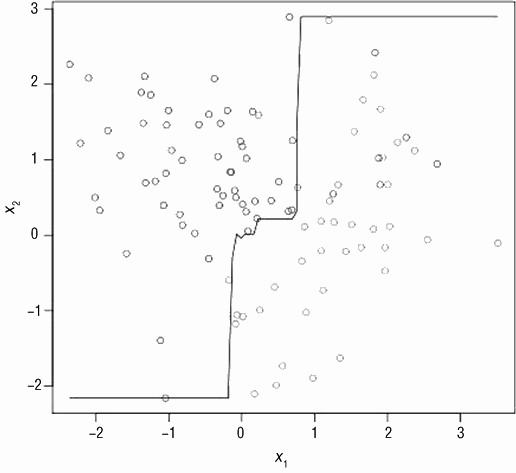
然而决策边界的复杂性并不是唯一决定使用线性方法还是非线性方法的因素。另一个重要因素是数据集的大小。图 3-3 展示了数据集大小对性能的影响。图 3-3 中的点从图 3-2中抽样得到,抽样比例为 1%。
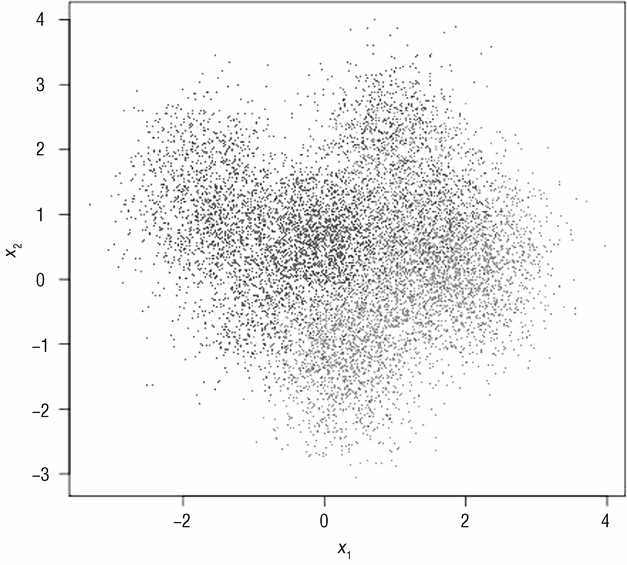
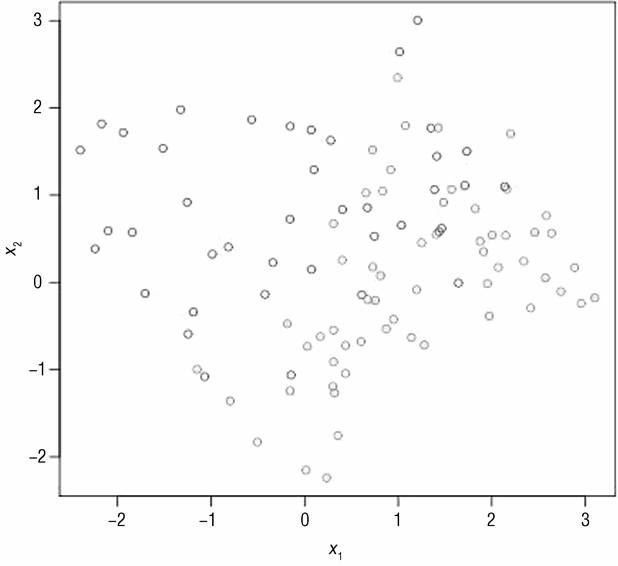
图 3-2 包含充足的数据,人们可以通过视觉来确定边界,这些边界很好地区分了浅色点以及深色点。如果没有这么多数据点,不同类别就很难在视觉上进行区分,此时,相比非线性模型,一个线性模型可以给出相同甚至更好的性能。如果数据少的话,边界很难通过视觉确定,所以也更难进行计算。本例通过图像展示了数据量对于分类的重要性。
如果问题很复杂(如对不同购物者提供个性化的服务),一个拥有大量数据的复杂模型可以生成精确结果。然而,如果真实模型不复杂(见图 3-1)或者没有足够多的数据(见图 3-3),一个线性模型可能是最好的答案。
3.2.2 一个简单模型与复杂模型的对比
前面介绍了简单问题和复杂问题在视觉上的差异。本节将描述能够解决这些问题的不同模型是如何工作的以及它们之间的差异。直观上,一个复杂的模型应该解决复杂的问题,但是上一节的可视化的例子表明在数据有限情况下,对于复杂问题,简单模型可能要好于复杂模型。
另一个重要概念是现代机器学习算法往往生成模型族,不只是单个模型。本书提到的每个算法可以生成成百上千个不同的模型。一般来讲,第 6 章提到的集成方法可以产生比第 4 章中提到的线性方法更多的复杂模型,但是两种方法都可以生成不同复杂度的多个模型(通过第 4 章和第 6 章对线性方法和集成方法的深入讨论,该结论会更加清晰)。
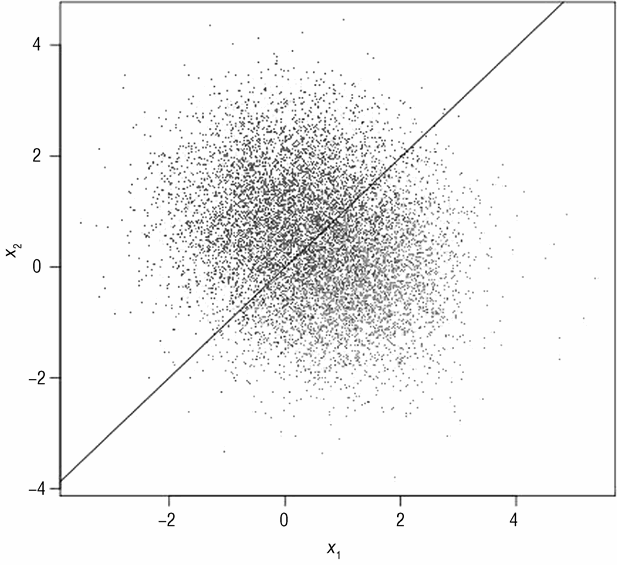
图 3-4 为上一章中用于拟合简单问题的线性模型。图 3-4 中的线性模型使用 glmnet 算法(第 4 章会提到)生成。拟合这些数据的线性模型将数据粗暴地分为 2 份。图 3-4 中的分界线对应于公式 3-6。
x₂ = -0.01 + 0.99xi
公式 3-6 适用于简单问题的线性模型
该分界线非常接近于 x₂=x₁ 的分界线,从概率意义上讲,x₂=x₁ 是最佳可能的分界线。
该边界从视觉角度讲也是合理的。针对该简单问题拟合一个更加复杂的模型不能进一步提升预测效果。
一个拥有更多决策边界的复杂的问题为复杂模型提供了超越简单线性模型的机会。
图 3-5 为拟合数据后的线性模型,线性模型效果表现不尽人意,表明该问题实际需要非线性的决策边界。在这种情况下,线性模型会将浅色点错分为深色点,反之亦然。
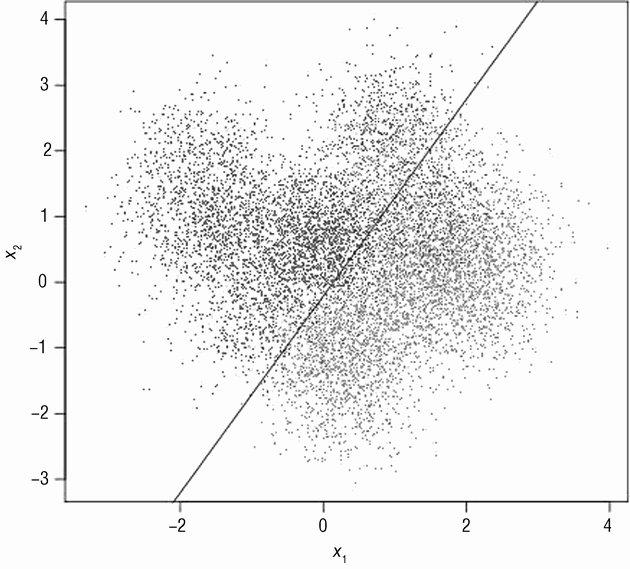
图 3-6 展示了复杂模型如何更好地处理复杂数据。用于生成该决策边界的模型是一个包含 1 000 棵二分类决策树的集成模型,该模型通过梯度提升算法训练得到(第 6 章会详细介绍梯度提升决策树)。非线性决策边界用于更好地划分深色和浅色区域。
虽然倾向于得到如下结论:即最好的办法是用复杂模型解决复杂问题,用简单模型解决简单问题,但是必须考虑问题的另一维度。正如在前面章节中提到的,必须考虑数据规模,图 3-7 以及图 3-8 为从复杂问题抽样的 1% 的数据。图 3-7 为一个拟合数据的线性模型,图 3-8 为一个拟合数据的集成模型。统计误分类的点数,目前数据集中共有 100 个点。图 3-7中的线性模型误分类了 11 个点,错误率为 11%。复杂模型误分类了 8 个点,错误率为 8%。
它们的性能基本一样。
3.2.3 影响预测算法性能的因素
上面结果说明了大数据对于预测的重要性。对于复杂问题进行精确预测需要大量数据,但到底需要多少数据其实很难准确描述。数据的分布形状也很重要。
公式 3-1 将数据描绘为一个矩阵,该矩阵包含大量的行(高)和列(宽)。矩阵中的元素个数是行数与列数的乘积。当数据用于预测模型时,行数与列数的多少会对预测产生重要影响。添加一列意味着添加一个新的属性,添加一行意味着添加一条使用当前属性表示的新样本。为了理解添加一个新行与一个新列的不同,考虑一个线性模型,该线性模型使用来自公式 3-1 的属性以及来自公式 3-2 的标签。
假设模型的表示形式如下(参见公式 3-7)。
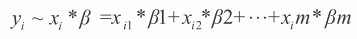
这里,xi 是一行属性,β 是一列要学习的系数。添加一列对应于新添加一个要学习的参数。这里系数个数也称作自由度。增加额外的自由度会使模型变复杂。前面例子表明复杂模型需要更多的数据。这种情况可以通过行数与列数比例来考虑,即长宽比。
生物数据集以及自然语言处理数据集一般是包含大量列的数据集,这些数据集虽然有很多样本,但往往也不足以训练好一个复杂模型。在生物学里,基因数据集很容易就包含10,000 ~ 50,000 个属性。即使通过成百上千次的单个实验(数据的行),基因数据也不足以训练一个复杂的集成模型。线性模型可以给出等价甚至更好的性能。
基因数据很昂贵。一次实验(数据行)就可能花费 $5,000 美元,整个数据集花费可能会达到 5,000 万美元。文本相对容易收集和存储,但属性个数可能要比基因数据中的属性个数更多。对于一些自然语言处理问题,属性是词,每一行对应一篇文档。属性矩阵中的每一个元素表示词在文档中的出现次数。列的数目对应于文档的词汇量大小。根据预处理情况(如移除常见的词,如 a、and 以及 of),最后的词汇量可能会从几千到数万。
如果考虑 n-gram,文本的属性矩阵会更加庞大。n-gram 是相邻的 2 个、3 个或者 4 个词,这些词的位置足够紧密甚至可以构成短语。在这种情况下,线性模型相对于复杂的集成方法,可能会产生相同甚至更好的性能。
3.2.4 选择一个算法:线性或者非线性
刚刚看到的可视化例子说明了使用线性或者非线性模型应该做的权衡考虑。对于列比行多的数据集或者相对简单的问题,倾向于使用线性模型。对于行比列多很多的复杂问题,倾向于使用非线性模型。另一个考虑因素是训练时间。线性方法要比非线性方法训练时间短(当你读完第 4 章以及第 6 章并且实际操作过一些例子时,你会有更多的经验来选择方法)。
选择一个非线性模型(如集成方法)对应于训练大量不同复杂度的模型。例如,生成图 3-6所示的决策边界的集成模型在训练时大约会生成 1000 个不同的模型。这些模型有不同的复杂度。一些模型会给出非常粗粒度的近似边界,这些边界如图 3-6 所示。之所以选择图 3-6 中的决策边界,是因为对应模型在预留数据集上的效果最好。以上过程对许多现代的机器学习算法同样适用。3.4.1 节会给出具体例子。
通过本节使用的数据集以及分类器进行可视化,读者能够直观地看到影响预测模型性能的因素。通常来讲,一般使用数值评价指标来度量性能而非依赖于图形展示。下一章将介绍基于数值指标的评价方法、使用评价指标要考虑的因素以及如何使用评价指标来评估部署模型的性能。





本书评论