
3.1 基本问题:理解函数逼近
本书涵盖的算法解决一类特定的预测问题。这类预测问题包括两种变量:
(1)第一种变量是尝试要预测的变量(比如网站的访问者是否会点击广告这样的变量)。
(2)第二种变量是用来进行预测的变量(比如网站访问者在人口统计方面的背景或者访问者在网站留下的历史访问行为这样的变量)。
这类问题称作函数逼近问题,因为目标是构建以第二类变量作为输入的函数来预测第一类变量。
在一个函数逼近问题中,模型设计者一般是从带有标记的历史样本集合开始研究。例如,网络日志文件会表明访问者是否会点击呈现的广告。数据科学家接着要从中找到可以用于构建预测模型的特征。例如,为了预测网站访问者是否会点击广告,数据科学家可能尝试使用访问者在看到广告前浏览过的其他页面。如果用户在网站注册过,那么历史购买数据或网页浏览记录都可用于预测。
要预测的变量一般有多种正式名称,如目标、标签、结果。用于构建预测的输入变量也有多种名称,如预测因子、回归因子、特征以及属性。这些词在下文中可能会换着使用,在实际应用中也不互相区分。决定使用哪种属性进行预测被称作特征工程。数据清洗以及特征工程占据了数据科学家 80% ~ 90% 的时间。
特征工程一般需要通过一个由人工参与的、迭代的过程来完成特征选择,决定可能最优的特征,并且尝试不同的特征组合。本书涵盖的算法将为每个属性赋一个重要度得分。
这些得分表明了属性在构建预测时的相对重要性,从而帮助加速特征工程。
3.1.1 使用训练数据
数据科学家往往是从一个训练集开始进行算法开发。训练集包括结果以及由数据科学家选择的特征集合。训练集包括 2 类数据:
✦ 要预测的结果
✦ 用于预测的特征
表 3-1 展示了训练集中的一个样本。最左侧一列为实际结果(网站访问者是否点击了链接);后两列是预测访问者是否会在将来点击链接的特征。
表 3-1 样例训练集
结果:是否点击链接 | 特征 1:用户性别 | 特征 2:用户在网站上的花销 | 特征 3:年龄 |
是 | 男 | 0 | 25 |
否 | 女 | 250 | 32 |
是 | 女 | 12 | 17 |
预测因子(即特征、属性等)可以使用矩阵的形式来表示(见公式 3-1)。本书约定使用的记号如下所示。预测因子构成的表使用 X 来表示。

回到表 3-1 中的数据集,x11 对应 M(用户性别),x12 对应 0.00(网站上的花费),x21对应 F(性别),等等。
有时使用单个符号来指代一个特定样本的所有属性会很方便。比如 x(使用单个索引) i对应 X 的第 i 行。对于表 3-1 中的数据集,x2 是指包含值 F,250,32 的行向量。
严格来讲,X 不是矩阵,因为预测因子的数据类型可能不完全相同(一个合理矩阵包含的变量需要是相同类型,然而预测因子是不同类型)。以广告点击预测为例,预测因子可能包含网站访问者的人口背景数据,如婚姻状态、年收入等。年收入是个实数值,婚姻状态是一个类别变量。这意味着婚姻状态并不能进行数值运算,如相加、相乘,并且单身、结婚、离异也不存在大小顺序关系。对于 X 中的列,数据类型相同,但对不同的列,数据类型可能不同。
对于婚姻状态、性别或者居住状态这类属性有统一的名称,如因子属性或者类别属性。
类似于年龄或者收入的属性称作数值型或者实数型属性。这两类属性区别很重要,因为一些算法可能只能处理其中的一类属性。例如,线性方法包括本书提到的算法,需要使用数值属性(第 4 章涵盖了线性方法,介绍了将类别属性转换为数值属性的方法,以便将线性方法应用到包含类别属性的问题中)。
X 每一行对应的预测目标值排列起来可以用列向量 Y 来表示(参见公式 3-2),表示如下:
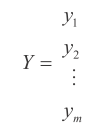
预测目标 yi 对应于输入 xi- 即 X 的第 i 行中的预测结果。参照表 3-1 中的数据,y1 表示“是”,y2 表示“否”。
预测目标也可能有多种数据类型。一种是实数类型,如预测消费者会花多少钱。当预测目标是实数时,这类问题称作回归问题。线性回归是指使用线性方法来解决回归问题(本书同时涵盖了线性以及非线性方法)。
如果预测目标只包含 2 个值,如表 3-1 所示,那么对应问题称作 2 分类问题。预测用户是否会点击广告是一个 2 分类问题。如果预测目标包含多个不同的离散值,那么该问题称作多分类问题。在有多个广告的情况下,预测用户会点击哪个广告就是一个多分类问题。
回归问题的目标是寻找一个预测函数 pred(),该函数使用属性来预测输出结果(参照公式 3-3)。
yt ~ pred(xt)
公式 3-3 构建预测的基本公式
函数 pred() 使用属性 xi 来预测 yi。本书将介绍目前几种构建 pred()函数的最佳方法。
3.1.2 评估预测模型的性能
好的性能意味着使用属性 xi 来生成一个接近真实 yi 的预测,这种“接近”对不同问题含义不同。对于回归问题,yi 是一个实数,性能使用均方误差(MSE)或者平均绝对误差(MAE)来度量(参见公式 3-4)。
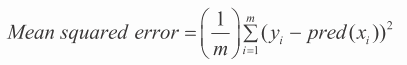
因为在一个回归问题中,预测目标(yi)以及预测函数输出 pred(xi)都是实数,所以通过它们的数值差异来描述错误是合理的。MSE 的计算公式 3-4 对误差求平方,然后平均来生成对错误的整体度量。MAE 对误差的绝对值求平均(参照公式 3-5)而不是对误差平方求平均。
|
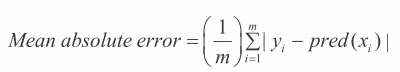
如果问题是一个分类问题,那么需要使用不同的性能指标。最常用的性能指标是误分类率,即计算 pred() 函数预测错误的样本比例。3.3.1“不同类型问题的性能评价指标”介绍了如何计算误分类率。
对于预测函数 pred(),需要评估其在新样本(未见过的)上的错误程度。算法在新数据上(这些数据在生成预测函数 pred() 时并没有使用)的表现如何?本章将介绍用于评估算法在新数据上性能的最佳方法。
本节介绍了预测问题的基本类型,阐明构建预测模型为何等同于构建将属性(或者特征)映射为输出的函数。还介绍了评估预测错误的方法。以上步骤涉及若干难点,下面内容将对这些难点一一描述并且解决,介绍如何在问题及数据限制的情况下达到最佳效果。





本书评论