
4.7 处理异常值
问题描述
处理数据中的异常值。
解决方案
通常有三种方式来处理异常值。第一种方式,丢弃它们:

第二种方式,将它们标记为异常值,并作为数据的一个特征:

最后,对有异常值的特征进行转换,降低异常值的影响:

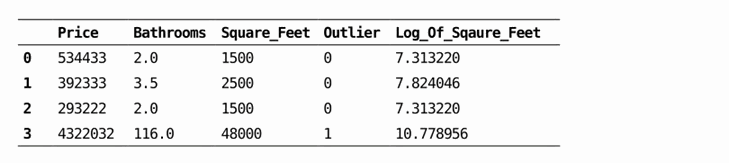
讨论
和识别异常值一样,处理异常值时也不存在一个绝对准则。应该基于两个方面来考虑对异常值的处理。第一,要弄清楚是什么让它们成为异常值的。如果你认为它们是错误的观察值,比如它们来自一个坏掉的传感器或者是被记错了的值,那么就要丢弃它们或者用NaN来替换异常值,因为我们无法信任这些值。但是,如果你认为这些异常值真的就是极端值(例如一幢大宅子有200间卧室),那么把它们标记为异常值或者对它们的值进行转换,是更合理的做法。
第二,应该基于机器学习的目标来处理异常值。例如,如果想要基于房屋的特征来预测其价格,那么可以合理地假设有100间卧室的大宅子的价格是由不同于普通家庭住宅的特征驱动的。此外,如果使用一个在线住房贷款的Web应用的部分数据来训练一个模型,那么就要假设潜在用户中不存在想要买一栋有几百间卧室的豪宅的亿万富翁。
所以,对于异常值到底要如何处理呢?首先,想一想它们为什么是异常值,然后对于数据要有一个最终的目标。最重要的是,要记住“决定不处理异常值”本身就是一个有潜在影响的决定。
另外,如果数据中有异常值,那么采用标准化方法做缩放就不太合适了,因为平均值和方差受异常值的影响很大。这种情况下,需要针对异常值使用一个鲁棒性更高的缩放方法,比如RobustScaler。
延伸阅读
● RobustScaler文档(http://bit.ly/2DcgyNT)





本书评论