
2.2 创建仿真数据集
问题描述
生成一个仿真数据集。
解决方案
scikit-learn提供了很多创建仿真数据集的方法。其中有三个方法非常有用。如果需要用一个仿真数据集来做线性回归,make_regression是一个不错的选择:

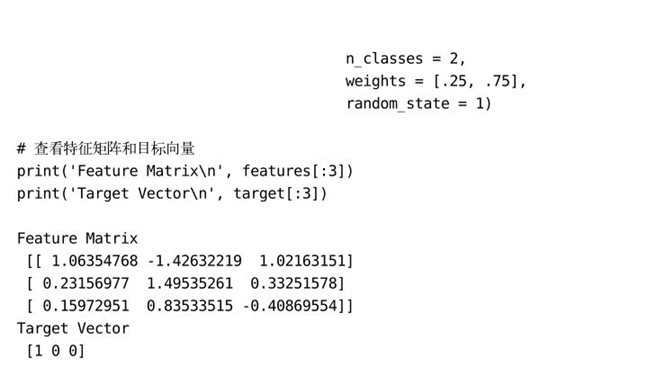
如果需要创建一个仿真数据集来做分类,可以使用make_classification:

最后,如果你想要一个适合做聚类处理的数据集,scikit-learn提供了make_blobs:

讨论
从上述解决方案能看到,make_regression返回一个浮点数的特征矩阵和一个浮点数的目标向量,而make_classification和make_blobs返回的是一个浮点数的特征矩阵和一个代表分类的整数目标矩阵。
scikit-learn的仿真数据集提供了很多选项以控制所生成数据的类型。
scikit-learn文档对所有参数都有完整的描述,但是有几个参数值得在这里特别说明。
在make_regression和make_classification中,n_informative确定了用于生成目标向量的特征的数量。如果n_informative的值比总的特征数(n_features)小,则生成的数据集将包含多余的特征,这些特征可以通过特征选择技术识别出来。
另外,make_classification包含了一个weights参数,可以利用它生成不均衡的仿真数据集。举个例子,如果我们设置weights = [.25, .75],那么生成的数据集中,25%的观察值属于第一个分类,75%的观察值属于第二个分类。
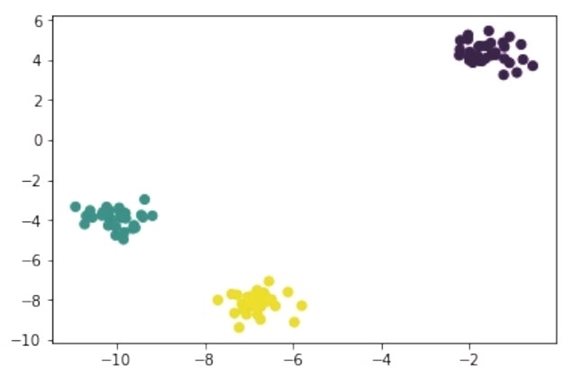
对于make_blobs来说,centers参数决定了要生成多少个聚类。使用matplotlib可视化库,能将make_blobs生成的聚类可视化地显示出来,如下图所示。

延伸阅读
● make_regression的文档(http://bit.ly/2FtIBwo)
● make_classification的文档(http://bit.ly/2FtIKzW)
● make_blobs的文档(http://bit.ly/2FqKMAZ)





本书评论