
20.2 设计一个神经网络
问题描述
设计一个神经网络。
解决方案
使用Keras的Sequential模型:

讨论
神经网络是由多层神经元组成的,神经元层的类型以及它们组成神经网络的方式非常多。现阶段尽管有很多被广泛使用的架构模式(我们会在本章讲到),但真相却是,选择正确的架构更像是一门艺术,需要我们做很多研究工作。
要在Keras中构建一个前馈神经网络,我们需要对网络架构和训练过程做许多选择。记住,隐藏层的每个神经元都会经历如下步骤:
1.接收一些输入。
2.给每个输入乘以一个参数作为权重。
3.对所有加权过的输入求和,再加上偏差(一般是1)。
4.接下来,将这个值应用到某个函数上(又叫作激活函数)。
5.把输出传递给下一层的神经元。
第一,对隐藏层和输出层中的每一层,我们都必须定义神经元的数量和它的激活函数。总的来说,一个层中神经元越多,神经网络就越能学习复杂的模式。尽管如此,神经元过多可能会使神经网络对训练数据过拟合,影响其在测试数据上的表现。
对隐藏层来说,一个流行的激活函数是矫正的线性单元(Rectified Linear Unit,ReLU):
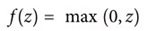
这里z是加权过的输入和偏差之和。我们可以看到,如果z大于0,激活函数就返回z值;否则返回0。这个简单的激活函数有许多可贵的特性(本书不讨论这些特性),使它成为神经网络中受欢迎的激活函数。不过,你也要知道还存在很多其他的激活函数。
第二,我们需要决定神经网络中隐藏层的数量。层数越多,神经网络能学习的关系就越复杂,但是计算开销也会越大。
第三,我们必须决定输出层的激活函数(如果有的话)的结构。输出函数的本质经常由神经网络的目标决定。这里列出一些常见的输出层的模式:
二元分类
一个有sigmoid激活函数的神经元。
多元分类
k个神经元(这里k是目标分类的个数)和一个softmax激活函数。
回归
一个没有激活函数的神经元。
第四,我们需要定义一个损失函数(用来衡量预测值和真实值的符合程度)。这个函数也经常是由问题的类型所决定的:
二元分类
二分交叉熵(Binary Cross-entropy)。
多元分类
分类交叉熵(Categorical cross-entropy)。
回归
均方误差。
第五,我们需要定义一个优化器,它可以被直观地理解为我们的策略“绕过了”损失函数,并且找到了产生最小误差的那些参数值。常用的优化器有:随机梯度下降、动量随机梯度下降、均方根传播和自适应矩估计(关于这些优化器的更多信息,可以查看本节末尾的“延伸阅读”中列出的资料)。
第六,我们可以选择一个或者多个指标来评估神经网络的性能,比如准确率。
Keras提供了两种创建神经网络的方法。Keras的sequential模型通过把神经元层堆叠起来以创建神经网络。另一种创建神经网络的方法叫作函数式API,但是这种方法更适合研究人员使用而不适合商用。
在解决方案中,我们使用Keras的sequential模型创建了一个两层的神经网络(计算层数的时候,我们不会把输入层算在内,因为它没有任何参数需要学习)。每一层都是“紧密的”(又叫作全连接的),这意味着前一层的所有神经元都和下一层的所有神经元相连。在第一个隐藏层中,我们设定units = 16,表示这一层有16个神经元,每个神经元都有ReLU激活函数(activation='relu')。在Keras中,任何神经网络的第一个隐藏层都必须包含一个input_shape参数,它表示特征数据的形状。比如,(10,)就告诉我们,第一层期望每个观察值都有10个特征值。第二层和第一层一样,只不过不需要加上input_shape参数。我们的神经网络是设计来做二元分类的,所以输出层仅包含一个带sigmoid激活函数的神经元,它将输出限制在0和1之间(表示一个观察值属于分类1的概率)。
最后,在训练模型之前,还需要告诉Keras,我们想让网络如何学习。
我们用compile方法,加上优化算法(RMSProp)、损失函数(binary_crossentropy),以及一个或者多个性能衡量标准来告诉Keras如何学习。
延伸阅读
● Keras文档:损失函数(https://keras.io/losses/)
● 分类的损失函数(Wikipedia,http://bit.ly/2FwpCkM)
●《分类问题中深度神经网络的损失函数》(Katarzyna Jano cha, Wojciech Marian Czarnecki,https://arxiv.org/abs/1702.05659)





本书评论