
15.2 创建一个KNN分类器
问题描述
对于分类未知的观察值,基于邻居的分类来预测它的分类。
解决方案
如果数据集不是特别大,就直接用KNeighborsClassifier:


讨论
在KNN算法中,如果给定一个分类未知的观察值,第一步会先基于某个距离指标(比如欧氏距离)找到最近的k个观察值(有时候称为x u 的邻域),然后这k个观察值基于它们自己的分类来“投票”,得票最多的那个分类就是预测的分类。更正式一点的表述是,属于某个分类j的概率是:
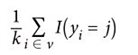
这里v是x u 的邻域内的k个观察值,yi是第i个观察值的分类,I是一个指示函数(即函数值为1就是真,为0就是假)。在scikit-learn中,我们可以使用predict_proba来查看这些概率:

概率最高的分类就是我们的预测分类。举个例子,在上面的输出结果中,第一个观察值应该属于分类1(Pr = 0.6),而第二个观察值应该属于分类2(Pr = 1),如下所示:

KNeighborsClassifier中有一些参数值得注意。第一个是metric,它可以用来设定使用何种距离指标(详见14.1节)。第二个是n_jobs,它控制可以使用多少个CPU内核。做预测需要计算一个点到数据集中所有点的距离,所以笔者强烈建议使用多个内核。第三个是algorithm,它用来设定计算最近邻居的算法。尽管不同的算法之间有很大的区别,但是KNeighborsClassifier默认会自动选择最合适的算法,所以一般不太需要为怎么选择这个参数而操心。默认情况下KNeighborsClassifier就是像我们前面描述的那样工作的,邻域内的每个观察值都可以投一票,用来确定预测分类,但是如果我们给distance设定了weights参数,那么距离近的观察值的投票比距离远的观察值的投票会有更高的权重。这种设定从直观上来说是有道理的,因为距离更近的邻居可能会告诉我们更多关于观察值分类的信息。
最后,正如15.1节中讨论的,因为计算距离时所有的特征被认为是在同一单位下的,所以在使用KNN分类器之前标准化特征是很重要的。





本书评论