
14.10 通过boosting提高性能
问题描述
需要一个比决策树或随机森林性能更好的模型。
解决方案
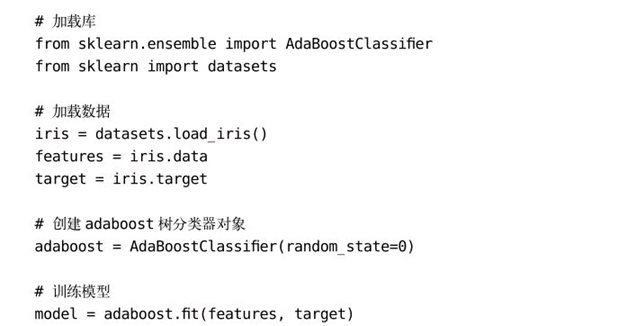
使用AdaBoostClassifier或AdaBoostRegressor训练一个boosting模型:
讨论
在随机森林中,用一组随机决策树对目标向量进行预测。而一种替代的且更强大的学习方法称为boosting。有一种形式的boosting算法叫作AdaBoost,它迭代地训练一系列弱模型(通常是一个浅层决策树,有时称为树桩),每次迭代都会为前一个模型预测错的样本分配更大的权重。AdaBoost算法的具体步骤如下:
1.为每个样本xi分配初始权重值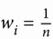 ,其中n是数据中样本的总数。
,其中n是数据中样本的总数。
2.用数据训练弱模型。
3.对于每一个样本:
(1)如果弱模型对x i的预测是正确的,则w i减少。
(2)如果弱模型对x i的预测是错误的,则w i增大。
4.训练一个新的弱模型,样本拥有更大的w i,优先级更高。
5.重复步骤3和4,直到数据被完美预测或已经训练完预定数量的弱模型。
最终结果是一个组合模型,里面的不同弱模型聚焦于(从预测角度来看)更复杂的样本。在scikit-learn中,我们可以使用AdaBoostClassifier或AdaBoostRegressor实现AdaBoost。其最重要的参数是base_estimator、n_estimators和learning_rate。
● base_estimator表示训练弱模型的学习算法。这个参数几乎不需要改变,因为到目前为止决策树(默认值)是AdaBoost最常用的学习算法。
● n_estimators是需要迭代训练的模型数量。
● learning_rate是每个弱模型的权重变化率,默认值为1。减小这个参数值意味着权重变化的幅度变小,这会使模型的训练速度变慢(但有时会使模型的性能更好)。
● loss是AdaBoostRegressor独有的参数,它设置了在更新权重时所用的损失函数。其默认值为线性损失函数,但是可以改为平方(square)或指数函数(exponential)。
延伸阅读
●《AdaBoost介绍》(Robert E.Schapire,http://bit.ly/2FCS30E)





本书评论