
14.8 处理不均衡的分类
问题描述
在高度不均衡的数据上训练随机森林模型。
解决方案
用参数class_weight="balanced"训练决策树或随机森林模型:


讨论
在现实中用学习算法训练模型时,很容易遇到不均衡的分类问题。如果不解决这个问题,不均衡的分类就会降低模型的性能。我们在17.5节将
讨论在数据预处理过程中处理不均衡分类的一些策略。不过在scikit-learn中,很多学习算法都带有用于纠正不均衡分类的内置方法。为
RandomForestClassifier设置参数class_weight就可以纠正不均衡分类的问题。如果将分类名和所需的权重以字典形式提供(如{"male": 0.2,"female": 0.8}), RandomForestClassifier将为各个分类相应地加权。不过参数balanced通常更有用,它根据各个分类在数据中出现频率的倒数自动计算权重值:
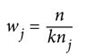
其中,wj是分类j的权重,n是样本数量,nj是分类j中样本的数量,k是分类的总数。举例来说,前面的解决方案中有两种分类(k),110个样本(n),每个分类中的样本数分别为10和100(nj)。如果使用参数class_weight="balanced",就能够增大较小分类的权重(减小较大分类的权重):

较大分类的权重值比较小:






本书评论