
14.6 识别随机森林中的重要特征
问题描述
想知道随机森林模型中最重要的特征。
解决方案
计算并可视化每个特征的重要性(Feature importance):


讨论
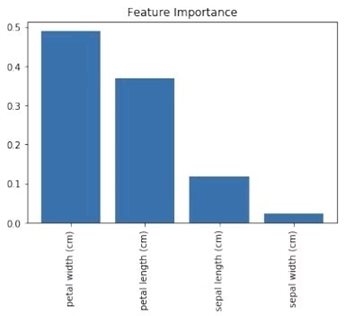
决策树的可解释性是它的优点之一,对决策树模型可视化是很容易的(参见13.3节)。然而,一个随机森林模型由数十、数百甚至数千棵决策树组成,很难对随机森林模型生成简易直观的可视化结果。不过,我们还可以用另一种方式可视化随机森林:比较(和可视化)每个特征的相对重要性。
在13.3节中,我们对决策树分类器模型进行了可视化,并且看到仅基于花瓣宽度的决策规则就能够将大部分样本正确分类,这意味着花瓣宽度是分类器中的一个重要特征。更准确地说,不纯度(比如分类器中的基尼不纯度或熵,以及回归模型中的方差)的平均减少量较大的分裂特征是更重要的特征。
关于特征的重要性有两点需要注意。首先,scikit-learn需要将nominal型分类特征分解为多个二元特征,使得特征的重要性分散到各个二元特征中。这样的话,即使原来的分类特征非常重要,分解后的特征往往也就没那么重要了。其次,如果两个特征高度相关,并且其中一个有很高的重要性,就会使另一个特征的重要性显得稍低,如果不考虑这种情况,模型的效果会受到影响。
在scikit-learn中,决策树和随机森林的分类及回归模型都可以通过feature_importances_查看模型中每个特征的重要程度:

数值越大,说明该特征越重要(所有特征的重要性分数相加等于1)。
绘制这些值的图形有助于解释随机森林模型。





本书评论