
13.4 通过正则化减少方差
问题描述
希望减少线性回归模型的方差。
解决方案
使用包含惩罚项(也称为正则化项)的学习算法,如岭回归(ridge regression)和套索回归(lasso regression):


讨论
在标准线性回归中,通过最小化真实值(yi)和预测值(ŷi)的平方误差来训练模型,这个平方误差值也被称为残差平方和(RSS,Residual Sum Of Squares):
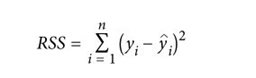
正则化的回归模型与其相似,但是它在优化对象RSS上加入了对系数值的惩罚,该惩罚项被称为收缩惩罚(shrinkage penalty),因为它试图“缩小”模型。线性回归有两种常见的正则化优化方法:岭回归和套索回归。二者的差异在于所使用的收缩惩罚项不同。在岭回归中,收缩惩罚项是可调超参数与所有系数的平方和的乘积:
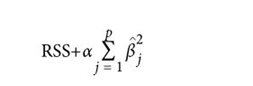
其中,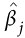 Th是总计p个特征中第j个特征的系数,α是超参数(下面会
Th是总计p个特征中第j个特征的系数,α是超参数(下面会
讨论)。套索回归与此相似,只不过收缩惩罚项变成了可调超参数与所
有系数绝对值之和的乘积:
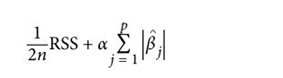
其中,n是样本的数量。那么在使用时我们应该选择哪一种?根据经验,岭回归通常比套索回归产生的结果稍好,但是套索回归(将在13.5节中讨论)产生的模型更容易解释。如果想在岭回归和套索回归的惩罚项之间折中,可以使用弹性网络(elastic net),它是一种同时包含了两种惩罚项的回归模型。无论使用哪一种惩罚项,岭回归和套索回归都可以通过在损失函数中加入来惩罚大型或复杂模型。
超参数α用来控制对Th的惩罚强度,α值越大,生成的模型就越简单。α的理想值应该是像其他超参数一样通过调试获得的。在scikit-learn中,使用alpha参数来设置α。
scikit-learn包含一个RidgeCV方法,可以使用它来选择理想的值:
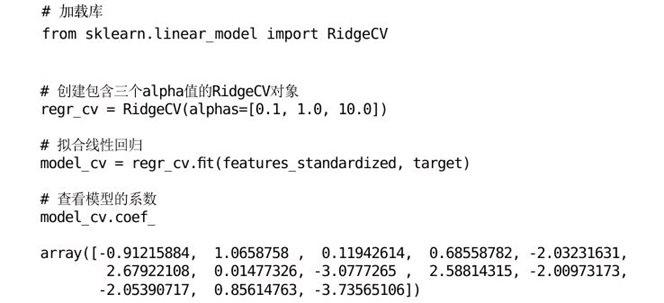
还可以查看最优模型的值:

最后要注意一点:在线性回归中系数的值受特征的范围(scale)的影响,而在正则化模型中所有系数会被加在一起,所以在训练模型之前必须确保特征已经标准化。





本书评论