
10.4 删除与分类任务不相关的特征
问题描述
根据分类的目标向量,删除信息量较低的特征。
解决方案
对于分类型特征,计算每个特征和目标向量的卡方统计量( X²,chi-squared):

对于数值型特征数据,则计算每个特征与目标向量之间的方差分析F值(ANOVA F-value):

除了选择固定数量的特征,还可以通过SelectPercentile方法来选择前n%的特征:

讨论
卡方统计可以检查两个分类向量的相互独立性。也就是说,卡方统计量代表了观察到的样本数量和期望的样本数量(假设特征与目标向量无关)之间的差异。
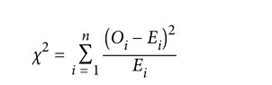
其中,Oi是第i个分类的样本数量;Ei是假设特征i和目标向量无关时,我们期望的第i个分类的样本数量。
卡方统计的结果是一个数字,它代表观察值和期望值(假设特征与目标向量无关时的值)之间的差异。通过计算特征和目标向量的卡方统计量,我们可以得到对两者之间独立性的度量值。如果两者相互独立,就代表特征与目标向量无关,特征中不包含分类所需要的信息。相反,如果特征和目标向量高度相关,则代表特征中包含训练分类模型所需的很多信息。
为了使用卡方统计进行特征选择,首先需要计算每个特征和目标向量之间的卡方统计量,然后选择卡方统计量最大的特征。在scikit-learn中,可以使用SelectKBest方法来选择最好的特征。其中的参数k决定了要保留的特征数量。
需要注意的是,卡方统计量只能在两个分类数据之间进行计算,所以使用卡方统计进行特征选择时,目标向量和特征都必须是分类数据。对于数值型特征,可以将其转换为分类特征后再使用卡方统计。最后,使用卡方统计方法时,所有值都必须是非负的。
除此之外,对于数值型特征还可以使用f_classif来计算每个特征和目标向量间的ANOVA F值。在根据目标向量对数值型特征分类时,该值可以用来判断每个分类的特征均值之间的差异有多大。例如,如果有一个二元目标向量(性别)和一个数值型特征(考试分数),那么ANOVA F值可以用来判断男性的平均得分是否与女性的相同。如果相同,那么考试分数并不能帮助我们预测性别,因此这个特征与目标向量是无关的。





本书评论