
9.1 使用主成分进行特征降维
问题描述
对于给定的一组特征,在保留信息量的同时减少特征的数量。
解决方案
使用scikit-learn库中的主成分分析工具(PCA):

讨论
主成分分析法(Principal Component Analysis,PCA)是一种流行的线性降维方法。PCA将样本数据映射到特征矩阵的主成分空间(主成分空间保留了大部分的数据差异,一般具有更低的维度)。PCA是一种无监督学习方法,也就是说它只考虑特征矩阵而不需要目标向量的信息。
在本节最后的“延伸阅读”中列出了关于PCA原理的数学描述的文章。这里我们用一个简单的例子来介绍PCA的原理。下图的数据包含两个特征x₁和x₂。从图中可以清楚地看到,样本的分布像一支侧放的雪茄烟,其长度远大于高度。在这里,可以用主成分(Principal Component)的方向来代替长度和高度,用特征变化最大的方向作为第一个主成分,变化第二大的方向作为第二个主成分,依此类推。
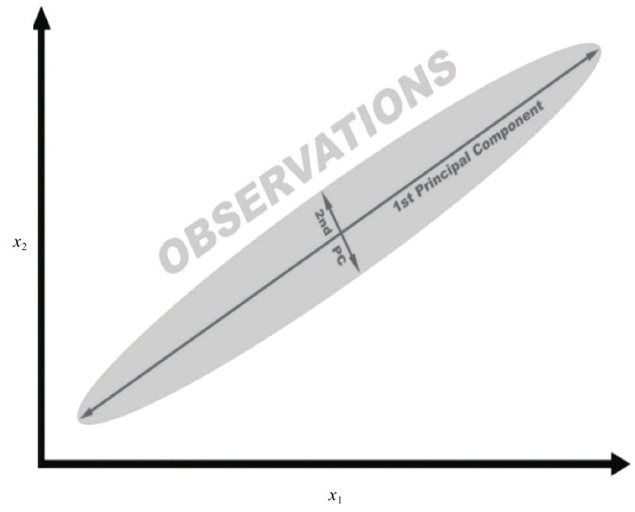
如果想降低特征的维度,可以将二维空间的样本映射到一维的主成分空间。这样做会损失第二个主成分携带的一些信息,你需要做出权衡,但在某些情况下这是可以接受的。这就是PCA的原理。
在scikit-learn中,PCA由方法pca实现。参数n_components有两种含义,由具体的参数值决定。如果值大于1,则n_components将会返回和这个值相同数量的特征,但这也带来一个问题,即如何选择最合适的特征数量。幸运的是, 如果n_components的值在0和1之间,pca就会返回维持一定信息量(在算法中,用方差代表信息量)的最少特征数。通常情况下,n_components取值为0.95或0.99,意味着保留95%或99%的原始特征信息量。参数whiten=True,表示对每一个主成分都进行转换以保证它们的平均值为0、方差为1。另一个参数是svd_solver="randomized",代表使用随机方法找到第一个主成分(这种方法通常速度很快)。
解决方案的输出结果显示,PCA保留了特征矩阵99%的信息,同时将特
征的数量减少了10个。
延伸阅读
● 关于PCA的scikit-learn文档(http://bit.ly/2FrSvyx)
●《选择主成分的数量》(http://bit.ly/2FrSGtH)
●《使用线性代数进行主成分分析》(http://bit.ly/2FuzdIW)





本书评论