
8.13 为机器学习创建特征
问题描述
将图像转换为机器学习算法可用的样本数据。
解决方案
使用NumPy的flatten方法将包含图像信息的多维数组转换成包含样本值的特征向量:

讨论
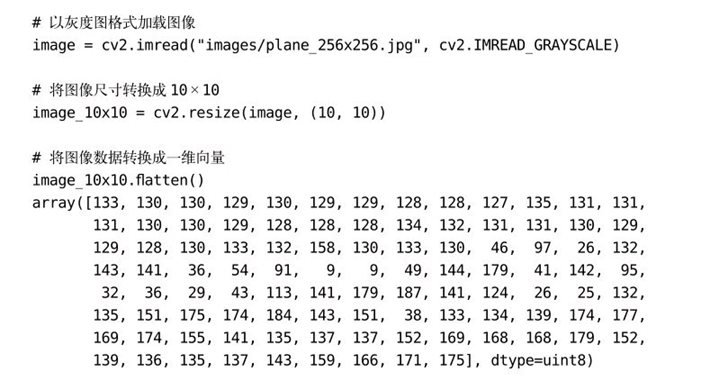
图像是用像素点的网格来表示的。如果是灰度图,则每个像素用一个值表示(即像素强度,白色为255,黑色为0)。假设我们有一张10×10像素的图像:
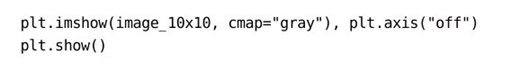

在这种情况下,图像数据的维度是10×10:

如果使用flatten方法将数组展开,会得到一个长度为100(10×10)的向量:

这就是图像的特征向量,它可以与其他图像的特征向量结合,生成可供机器学习算法使用的数据。
如果是彩色图像,每个像素就不是用一个值表示的了,而是用多个值(最常见的是3个),分别表示每个通道(红、绿、蓝等)的强度,这些色彩分量混合后可以表示对应像素点的颜色。因此,如果我们的10×10像素的图像是彩色的,每个样本将有300个特征值:

由于图像中的每个像素点都是一个特征,所以随着图像尺寸变大,特征的数量也快速增多,这是图像处理和计算机视觉中的一个主要挑战:

如果图像是彩色的,特征的数量还会进一步增加:


正如输出结果所示,即使是一张小的彩色图像也有近20万个特征,在我们训练模型时,这会产生问题,因为特征的数量可能远远超过样本的数量。
这个问题也引发了后面章节对维度策略的讨论:如何在减少特征数量的同时不丢失过多的信息。





本书评论