
7.3 如何开发一个交易策略
我们首先专注于技术方面,以此开始策略的研发。来看看在过去的几年中,标准普尔500 指数的表现。我们将使用 pandas 的功能来导入数据。这让我们可以访问多个股票数据来源,包括 Yahoo!和 Google。
首先,需要安装 datareader 包。这可以使用命令行通过 pip 安装:pip install pandas_datareader。
然后,我们将继续设置包的导入,如下所示。
import pandas as pd
from pandas_datareader import data, wb
import matplotlib.pyplot as plt
%matplotlib inline
pd.set_option('display.max_colwidth', 200)
现在,我们将获取 SPY ETF 的数据。它代表了标准普尔 500 的股票。我们将拉取从 2010年初到 2016 年 3 月初的数据。
import pandas_datareader as pdr
start_date = pd.to_datetime('2010-01-01')
stop_date = pd.to_datetime('2016-03-01')
spy = pdr.data.get_data_yahoo('SPY', start_date, stop_date)
上述代码生成图 7-1 的输出。
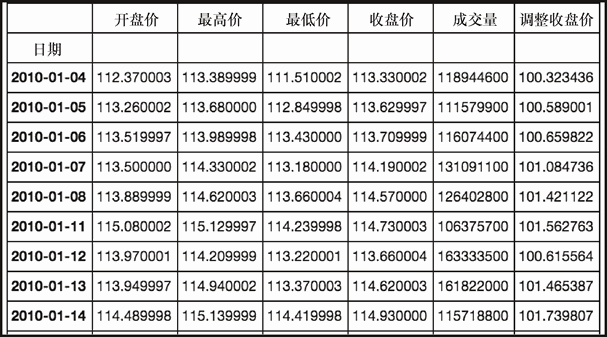
现在可以绘制这些数据了。我们只选择收盘价,如下所示。
spy_c = spy['Close']
fig, ax = plt.subplots(figsize=(15,10))
spy_c.plot(color='k')
plt.title("SPY", fontsize=20)
上述代码生成图 7-2 的输出。
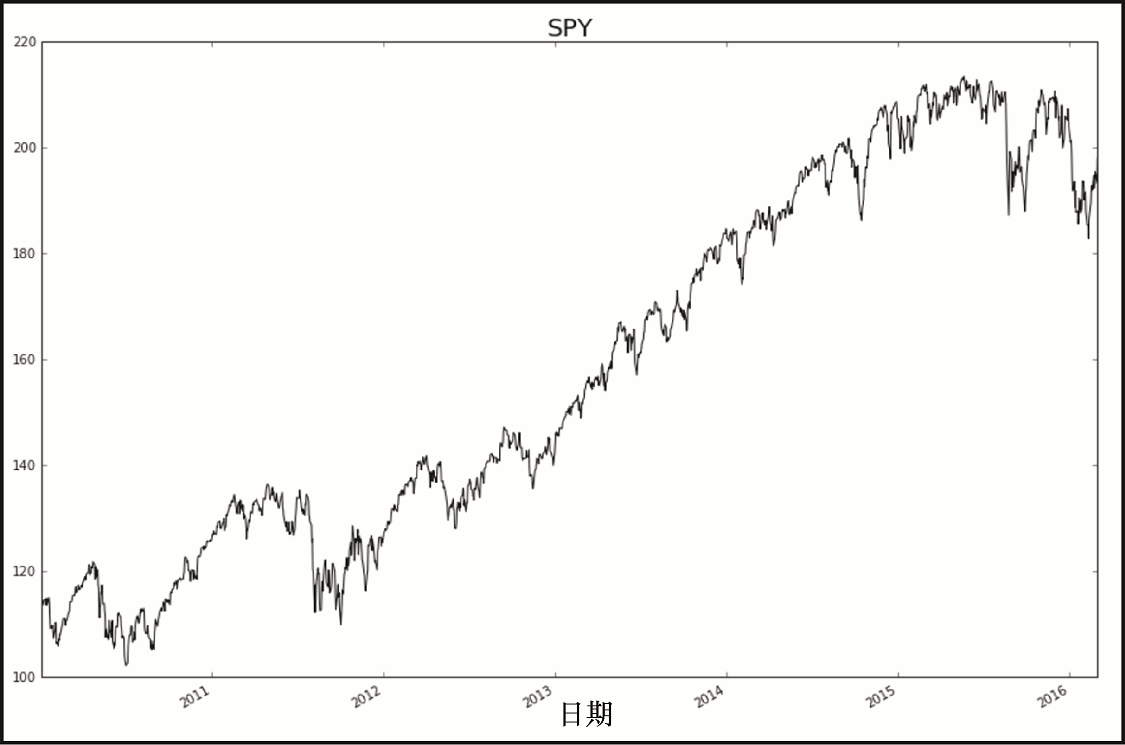
在图 7-2 中,我们看到了选定时期内,标准普尔 500 指数日收盘价的价格图。让我们进行一点分析,看看如果投资这个 ETF,该期间内的回报将是多少。
我们先拉取首个开盘日的数据。
first_open = spy['Open'].iloc[0]
first_open
上述代码生成图 7-3 的输出。
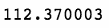
接下来,让我们得到该期间最后一天的收盘价。
last_close = spy['Close'].iloc[-1]
last_close
这将导致图 7-4 的输出。
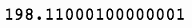
最后,让我们看看整个时期的变化。
last_close - first_open上述代码生成图 7-5 的输出。
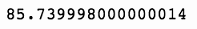
因此,看起来在这个时期开始的时候,购入 100 股股票会花费我们大约 11,237 美元,该时期结束时,相同的 100 股股份价值约为 19,811 美元。这笔交易将给我们带来超过 76%的收益。相当不错了。
现在让我们看看同一时期内,盘中交易的收益。这个操作假设我们在每日开盘时买入股票,并在当天收盘时卖出股票。
spy['Daily Change'] = pd.Series(spy['Close'] - spy['Open'])
这行代码将提供每天从开盘到收盘的变化。让我们来看看。
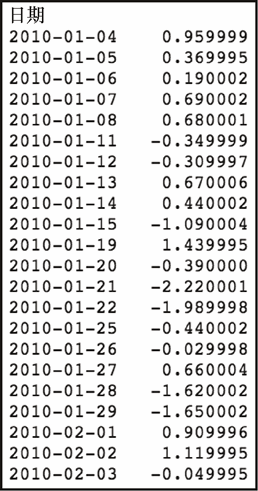
spy['Daily Change']
上述代码生成图 7-6 的输出。
现在让我们将这段时期的变化加和。
spy['Daily Change'].sum()
上述代码生成图 7-7 的输出。
所以,你可以看到,我们的收益已经从超过 85 点的增长,下降到刚刚过 41 点的增长。
哎哟!一半以上的市场收益来自于这段时期内整日整夜地持有股票。
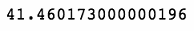
隔夜交易的回报率优于盘中交易的回报率,但是波动性又如何呢?人们总是在风险调整的基础上判断回报的,所以让我们来看看基于标准差,隔夜交易和盘中交易相比较各自表现如何。
我们可以使用 NumPy 来计算盘中交易的标准差,具体如下。
np.std(spy['Daily Change'])
上述代码生成图 7-8 的输出。
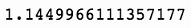
现在,让我们计算隔夜交易的标准差。
spy['Overnight Change'] = pd.Series(spy['Open'] - spy['Close'].shift(1))
np.std(spy['Overnight Change'])
上述代码生成图 7-9 的输出。
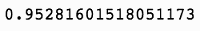
因此,隔夜交易与盘中交易相比具有较低的波动性。然而,并不是所有的波动性都是相等的。让我们比较两种策略,在下跌交易日的平均变化。
首先,让我们来看看下跌交易日的每日变化。
spy[spy['Daily Change']<0]['Daily Change'].mean()
上述代码生成图 7-10 的输出。
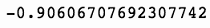
现在,我们来看看下跌交易日的隔夜变化。
spy[spy['Overnight Change']<0]['Overnight Change'].mean()
上述代码生成图 7-11 的输出。
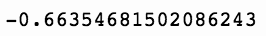
再次,我们看到隔夜交易策略的平均下降幅度小于盘中交易策略的。
到目前为止,我们都是观测的数据点,现来看看回报。这将有助于在更现实的背景下讨论我们的收益和损失。继续前面的三个策略 ①,我们将为每个场景构建一个pandas数据序列:每日回报(昨日收盘到今日收盘的价格变化)、盘中回报(当日开盘到收盘的价格变化)和隔夜回报(昨日收盘到今日开盘的价格变化),具体如下。
(①译者注:这里存在笔误,之前只提到了两个策略。)
daily_rtn = ((spy['Close'] – spy['Close'].shift(1))/spy['Close'].shift(1))*100
id_rtn = ((spy['Close'] - spy['Open'])/spy['Open'])*100
on_rtn = ((spy['Open'] - spy['Close'].shift(1))/spy['Close'].shift(1))*100
我们所做的是使用 pandas.shift()方法以当天的数据序列减去前面一天的数据序列。例如,对于前面代码中的第一个 Series,每天我们从当日收盘价中减去前一日的收盘价。由于是计算差价,所以新的 Series 所包含的数据点会少一个。如果打印出新的Series,你可以看到以下内容。
daily_rtn
上述代码生成图 7-12 的输出。
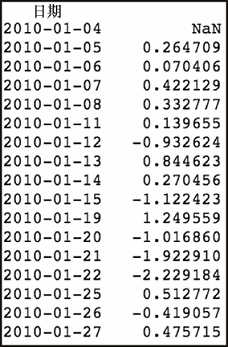
现在来看看所有三个策略的统计信息。我们将创建一个函数,它将接收每个回报的数据序列,然后打印出摘要性的结果。我们要得到每一次获利、亏损和盈亏平衡交易的统计数据,以及名为夏普比率(Sharpe ratio)的东西。我之前说过,回报是根据风险调整后的基础来判断的。这正是夏普比率将要提供给我们的。它是一种考虑回报的波动性,来比较回报的方法。这里,我们使用调整过的夏普比率来计算年化比率。
def get_stats(s, n=252):
s = s.dropna()
wins = len(s[s>0])
losses = len(s[s<0])
evens = len(s[s==0])
mean_w = round(s[s>0].mean(), 3)
mean_l = round(s[s<0].mean(), 3)
win_r = round(wins/losses, 3)
mean_trd = round(s.mean(), 3)
sd = round(np.std(s), 3)
max_l = round(s.min(), 3)
max_w = round(s.max(), 3)
sharpe_r = round((s.mean()/np.std(s))*np.sqrt(n), 4)
cnt = len(s)
print('Trades:', cnt,\
'\nWins:', wins,\
'\nLosses:', losses,\
'\nBreakeven:', evens,\
'\nWin/Loss Ratio', win_r,\
'\nMean Win:', mean_w,\
'\nMean Loss:', mean_l,\
'\nMean', mean_trd,\
'\nStd Dev:', sd,\
'\nMax Loss:', max_l,\
'\nMax Win:', max_w,\
'\nSharpe Ratio:', sharpe_r)
现在让我们在每个策略上运行相关的代码并查看统计信息。这里将从买入并持有的策略(每日回报)开始,然后再切换到另外两个,具体如下。
get_stats(daily_rtn)
上述代码生成图 7-13 的输出。
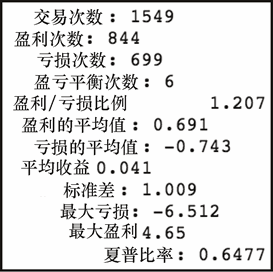
get_stats(id_rtn)
上述代码生成图 7-14 的输出。
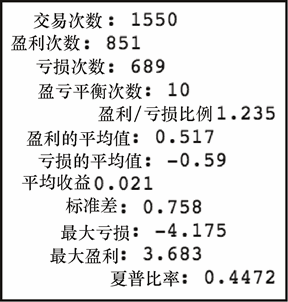
get_stats(on_rtn)
上述代码生成图 7-15 的输出。
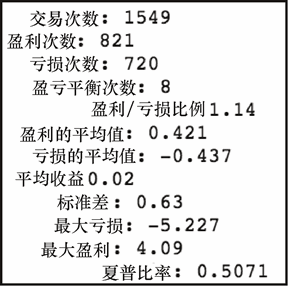
如你所见,在三个策略中,买入并持有的策略具有最高的平均回报率以及最高的回报率标准差。它也包含了最大的单日下跌(亏损)。还有一点值得注意的是,即使隔夜策略和盘中策略有着几乎相同的平均回报,其波动性明显较小。因此,隔夜策略的夏普比率要高于盘中策略的。
到目前阶段,我们拥有一个相当不错的基准线了,可以用它来比较我们后续的策略。
现在,我要告诉你一个新的策略,它将绝对性地击败目前所有的三个策略。
让我们来看看这个新的神秘策略的统计数据,如图 7-16 所示。
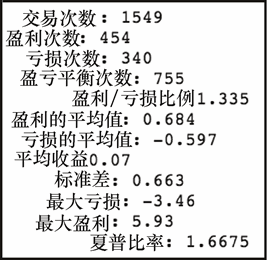
有了这个策略,我的夏普比率几乎是买入并持有策略的三倍,并明显地降低了波动性,增加了最大收益,并将最大损失降低近一半。
我是如何设计这种战胜市场的策略的?请稍等一下……在测试的时间段内,对于隔夜策略我生成了 1,000 次随机信号(买入或者不买入),然后选择表现最好的一个。这给了我最好的 1000 次随机信号组合。
这显然不是战胜市场的方式。那么,为什么我这样做呢?我这样做是为了证明,如果你测试足够多的策略,事实是你偶然会遇到一些似乎是很棒的策略。这就是所谓的数据挖掘谬误,是交易策略开发中的真正风险。这就是为什么某个策略和现实世界的行为相对应是如此的重要——而行为,由于一些现实的约束而产生了系统性的偏差。如果你想在交易中占有优势,不要和市场进行交易,而是与市场的参与者进行交易。
我们要占优势,就要深入地理解人们对某些情况如何做出反应。
7.3.1 延长我们的分析周期
现在延伸我们的分析。首先,从标准普尔 500 指数拉取自 2000 年开始的数据。
start_date = pd.to_datetime('2000-01-01')
stop_date = pd.to_datetime('2016-03-01')
sp = pdr.data.get_data_yahoo('SPY', start_date, stop_date)
让我们看看这个图表。
fig, ax = plt.subplots(figsize=(15,10))
sp['Close'].plot(color='k')
plt.title("SPY", fontsize=20)
上述代码生成图 7-17 的输出。
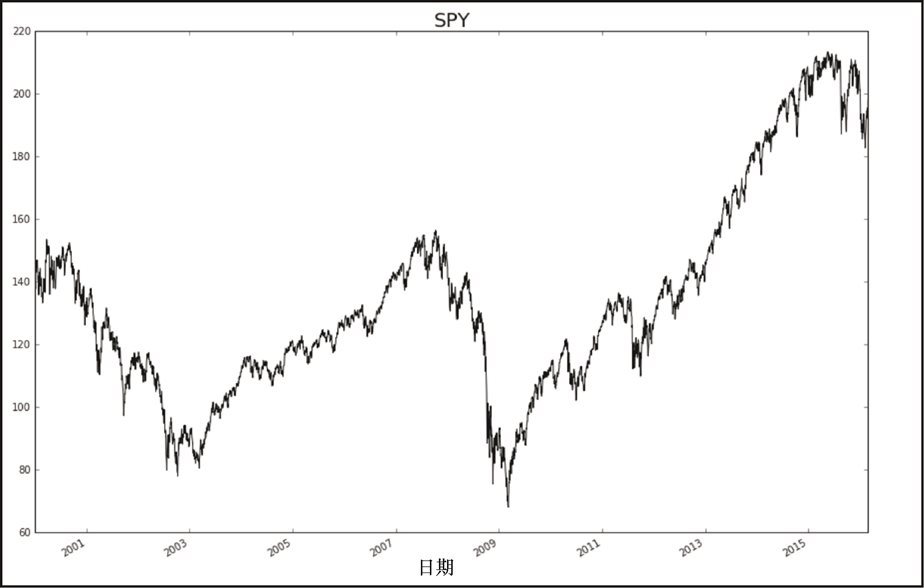
在图 7-17 中,我们看到了从 2000 年开始到 2016 年 3 月 1 日期间,SPY 的价格变化。
当时一定存在很多波动,市场同时经历了相对的高点和低点。
让我们在这个新扩展的时间段内,获取三个基本策略的基准线。
首先,让我们为每个策略设置变量,如下所示。
long_day_rtn = ((sp['Close'] –
sp['Close'].shift(1))/sp['Close'].shift(1))*100
long_id_rtn = ((sp['Close'] - sp['Open'])/sp['Open'])*100
long_on_rtn = ((sp['Open'] –
sp['Close'].shift(1))/sp['Close'].shift(1))*100
现在,让我们看看每个策略的总体数据。
1.首先是每日回报。
(sp['Close'] - sp['Close'].shift(1)).sum()
上述代码生成图 7-18 的输出。
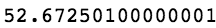
2.然后是盘中回报。
(sp['Close'] - sp['Open']).sum()
上述代码生成图 7-19 的输出。
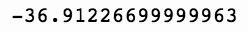
3.最后是隔夜回报。
(sp['Open'] - sp['Close'].shift(1)).sum()
上述代码生成图 7-20 的输出。
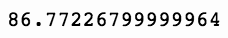
现在,让我们看看每种策略的统计数据。
4.首先,我们得到每日回报的统计量。
get_stats(long_day_rtn)
上述代码生成图 7-21 的输出。
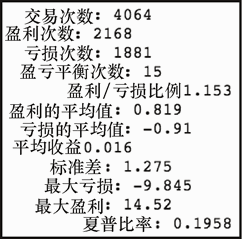
5.接下来,我们获取盘中回报的统计量。
get_stats(long_id_rtn)
上述代码生成图 7-22 的输出。
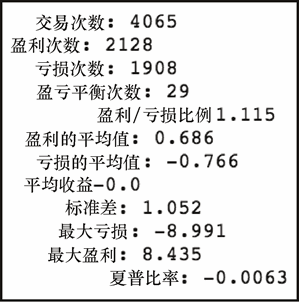
6.最后,我们得到隔夜回报的统计量。
get_stats(long_on_rtn)
上述代码生成图 7-23 的输出。
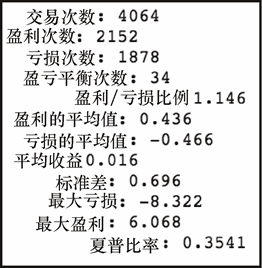
我们可以看到,在更长的考察时间内,三者之间的差异更加显著。如果我们在过去 16年间,只在白天持有标准普尔ETF,那么我们会亏钱。如果我们只在夜间持有ETF,回报就会得到超过 50%的改善!①当然,这里假设没有交易成本、没有税收,每次买入卖出都是完美衔接,但无论如何,这是一个了不起的发现。
①译者注:此处作者的意思是,和购买并持有相比,如果每天晚间买入并且在每天早上卖出,你将获得额外的50%盈利。
7.3.2 使用支持向量回归,构建我们的模型
现在我们有一个基线用于比较,接下来构建第一个回归模型。我们将从一个非常基本的模型开始,只使用股票的前一天的收盘价值来预测第二天的收盘价。我们将使用支持向量回归来构建此模型。有了这些,下面开始建立模型。
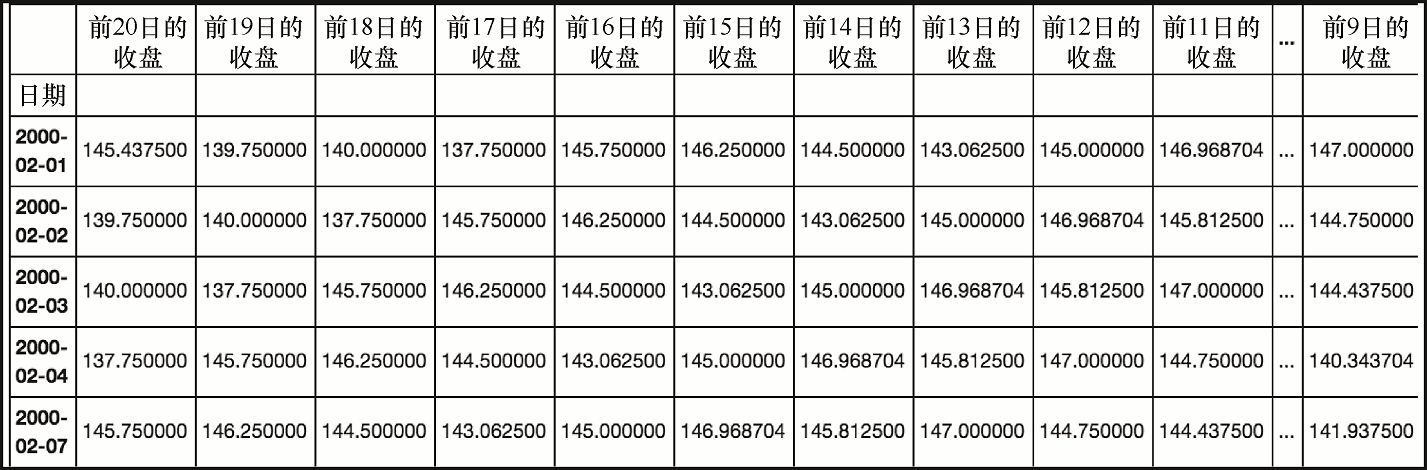
第一步是为包含每一天价格的历史记录设置 DataFrame 对象。在这个模型中,我们将包含过去的 20 个收盘,如下所示。
for i in range(1, 21, 1):
sp.loc[:,'Close Minus ' + str(i)] = sp['Close'].shift(i)
sp20 = sp[[x for x in sp.columns if 'Close Minus' in x or x == 'Close']].iloc[20:,]
sp20
上述代码生成图 7-24 的输出。
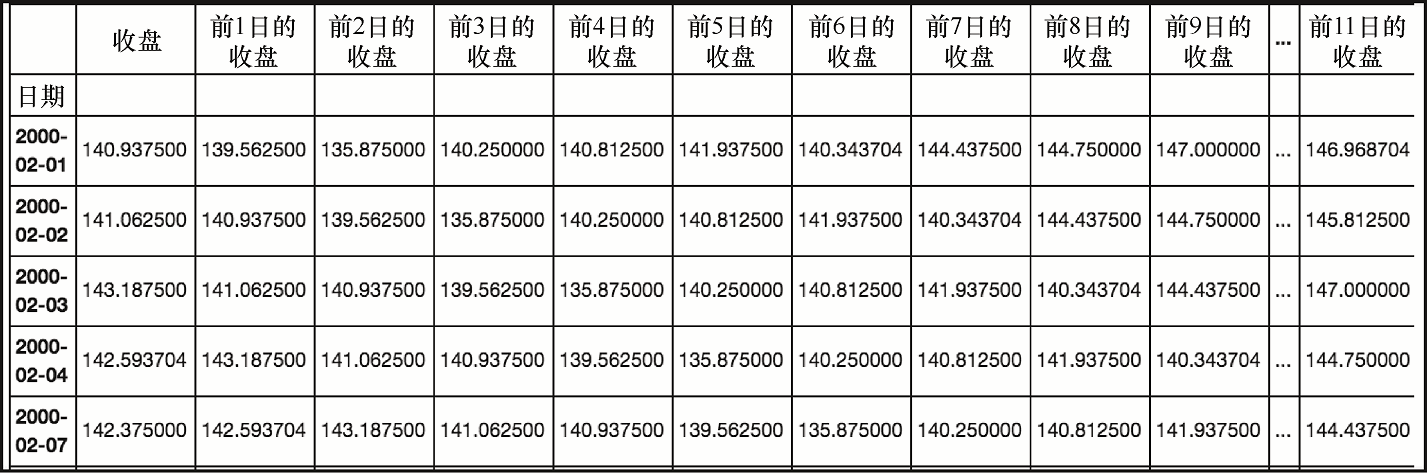
这个代码在同一行给出了每天及其前 20 个交易日的收盘价。
这将形成我们为模型所提供的 X 数组的基础。但是,在完全就绪之前,还有几个额外的步骤。
首先,我们将颠倒这些列,这样从左到右就是最早时间到最晚时间的顺序,如下所示。
sp20 = sp20.iloc[:,::-1]
sp20
上述代码生成图 7-25 的输出。
现在,让我们导入支持向量机,并设置训练和测试矩阵,以及每个数据点的目标向量。
from sklearn.svm import SVR
clf = SVR(kernel='linear')
X_train = sp20[:-1000]
y_train = sp20['Close'].shift(-1)[:-1000]
X_test = sp20[-1000:]
y_test = sp20['Close'].shift(-1)[-1000:]
我们只有 4000 多个数据点可以使用,并选择使用最后的 1000 个作为测试。现在让我们拟合模型,并使用它来测试样本之外的数据,具体如下。
model = clf.fit(X_train, y_train)
preds = model.predict(X_test)
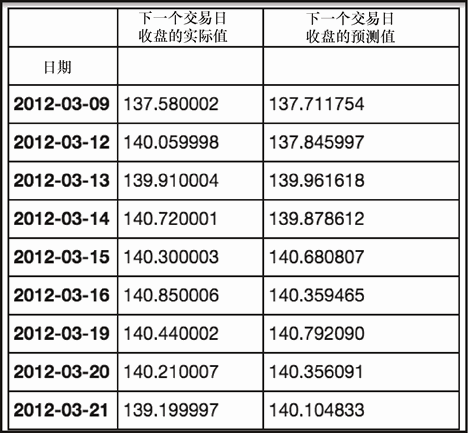
现在我们有自己的预测了,将它们与实际的数据进行比较。
tf = pd.DataFrame(list(zip(y_test, preds)), columns=['Next Day Close', 'Predicted Next Close'], index=y_test.index)
tf
上述代码生成图 7-26 的输出。
评估模型的性能
让我们来看看模型的性能。如果预测的当日收盘价高于当日开盘价,那么我们就会在当天开盘时买入。然后我们会在当天收盘时卖出。
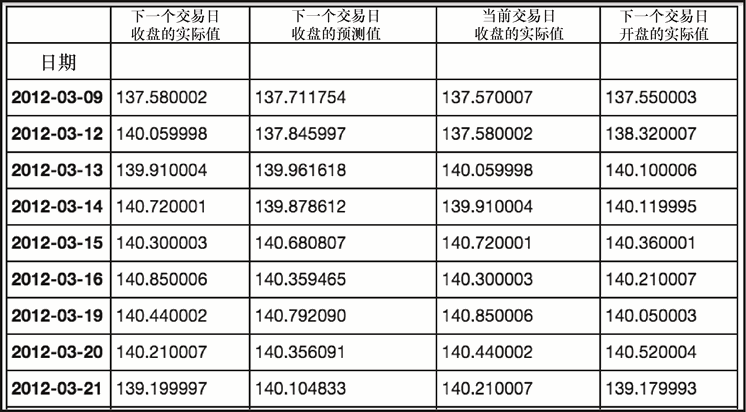
接下来,我们将向 DataFrame 对象添加一些额外的数据点来计算结果,如下所示。
cdc = sp[['Close']].iloc[-1000:]
ndo = sp[['Open']].iloc[-1000:].shift(-1)
tf1 = pd.merge(tf, cdc, left_index=True, right_index=True)
tf2 = pd.merge(tf1, ndo, left_index=True, right_index=True)
tf2.columns = ['Next Day Close', 'Predicted Next Close', 'Current Day
Close', 'Next Day Open']
tf2
上述代码生成图 7-27 的输出。
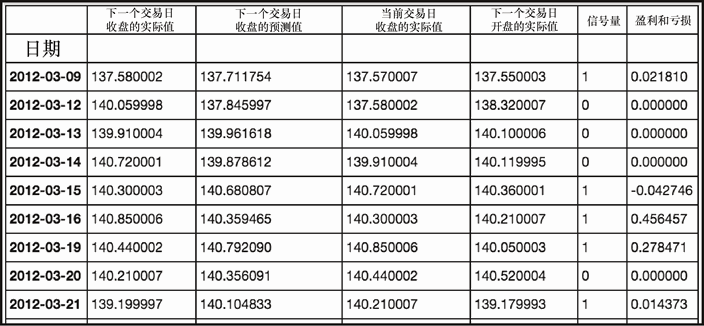
在这里,我们将添加以下代码来获取收益和亏损的信号量。
def get_signal(r):
if r['Predicted Next Close'] > r['Next Day Open']:
return 1
else:
return 0
def get_ret(r):
if r['Signal'] == 1:
return ((r['Next Day Close'] - r['Next Day Open'])/r['Next
Day Open']) * 100
else:
return 0
tf2 = tf2.assign(Signal = tf2.apply(get_signal, axis=1))
tf2 = tf2.assign(PnL = tf2.apply(get_ret, axis=1))
tf2
上述代码生成图 7-28 的输出。
现在来看看,我们是否能够只使用价格的历史来成功地预测第二天的价格。我们先从计算所获得的信号量点数开始,如下所示。
(tf2[tf2['Signal']==1]['Next Day Close'] - tf2[tf2['Signal']==1]['Next Day Open']).sum()
上述代码生成图 7-29 的输出。
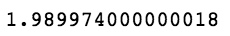
目前为止看上去不太妙。但是,和被测试的时期有关吗?我们从不独立地评估模型。
在最近的 1,000 天中,基本的盘中策略生成了有多少点?
(sp['Close'].iloc[-1000:] - sp['Open'].iloc[-1000:]).sum()
上述代码生成图 7-30 的输出。
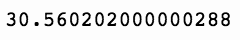
因此,看起来我们的新策略失败了,甚至没有比过基本的盘中买入策略。让我们拿到完整的统计数据来比较两者。
首先,这段时期的基本盘中策略统计如下。
get_stats((sp['Close'].iloc[-1000:] –
sp['Open'].iloc[-1000:])/sp['Open'].iloc[-1000:] * 100)
上述代码生成图 7-31 的输出。
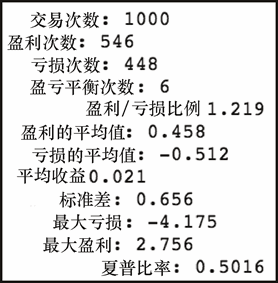
现在,我们模型的结果如下。
get_stats(tf2['PnL'])
上述代码生成图 7-32 的输出。
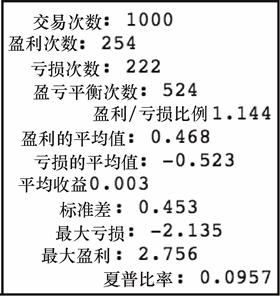
这看起来很糟糕。如果我们修改交易策略怎么样?如果只有在预测值比开盘值高出一定的程度之上,才进行买入交易,那又会怎么样?这样做有帮助吗?让我们试试看。我们将使用修改的信号量重新运行策略如下。
def get_signal(r):
if r['Predicted Next Close'] > r['Next Day Open'] + 1:
return 1
else:
return 0
def get_ret(r):
if r['Signal'] == 1:
return ((r['Next Day Close'] - r['Next Day Open'])/r['Next
Day Open']) * 100
else:
return 0
tf2 = tf2.assign(Signal = tf2.apply(get_signal, axis=1))
tf2 = tf2.assign(PnL = tf2.apply(get_ret, axis=1))
(tf2[tf2['Signal']==1]['Next Day Close'] - tf2[tf2['Signal']==1]['Next Day
Open']).sum()
上述代码生成图 7-33 的输出。
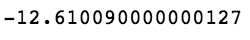
现在的统计如下。
get_stats(tf2['PnL'])
上述代码生成图 7-34 的输出。
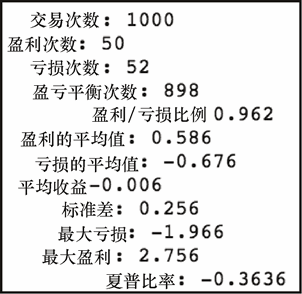
我们已经从糟糕到更糟糕了。看来,如果过去的价格历史表明好事要来临了,你可以做恰恰相反的预期。我们似乎已经使用这个模型开发了一个逆向的指标。如果我们继续探索会怎样?让我们看看如果翻转这个模型,收益会是什么样子,也就是说当模型预测强劲的收益时,我们不交易,相反,当模型预测亏损时,我们反而进行交易,具体如下。
def get_signal(r):
if r['Predicted Next Close'] > r['Next Day Open'] + 1:
return 0
else:
return 1
def get_ret(r):
if r['Signal'] == 1:
return ((r['Next Day Close'] - r['Next Day Open'])/r['Next Day Open']) *
100
else:
return 0
tf2 = tf2.assign(Signal = tf2.apply(get_signal, axis=1))
tf2 = tf2.assign(PnL = tf2.apply(get_ret, axis=1))
(tf2[tf2['Signal']==1]['Next Day Close'] - tf2[tf2['Signal']==1]['Next Day
Open']).sum()
上述代码生成图 7-35 的输出。
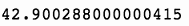
让我们获取统计数据。
get_stats(tf2['PnL'])
这将输出图 7-36 的结果。
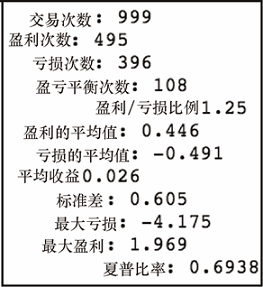
看起来我们确实拥有一个逆向指标。当我们的模型预测下一交易日会有收益的时候,市场表现明显不佳(至少在我们的测试期间内)。在大多数情况下这是否都成立?不见得。
市场倾向于从逆转的体系转变到趋势持续的体系。让我们在不同的时期,重新运行模型来进一步测试它。
X_train = sp20[:-2000]
y_train = sp20['Close'].shift(-1)[:-2000]
X_test = sp20[-2000:-1000]
y_test = sp20['Close'].shift(-1)[-2000:-1000]
model = clf.fit(X_train, y_train)
preds = model.predict(X_test)
tf = pd.DataFrame(list(zip(y_test, preds)), columns=['Next Day Close', 'Predicted Next Close'], index=y_test.index)
cdc = sp[['Close']].iloc[-2000:-1000]
ndo = sp[['Open']].iloc[-2000:-1000].shift(-1)
tf1 = pd.merge(tf, cdc, left_index=True, right_index=True)
tf2 = pd.merge(tf1, ndo, left_index=True, right_index=True)
tf2.columns = ['Next Day Close', 'Predicted Next Close', 'Current Day
Close', 'Next Day Open']
def get_signal(r):
if r['Predicted Next Close'] > r['Next Day Open'] + 1:
return 0
else:
return 1
def get_ret(r):
if r['Signal'] == 1:
return ((r['Next Day Close'] - r['Next Day Open'])/r['Next
Day Open']) * 100
else:
return 0
tf2 = tf2.assign(Signal = tf2.apply(get_signal, axis=1))
tf2 = tf2.assign(PnL = tf2.apply(get_ret, axis=1))
(tf2[tf2['Signal']==1]['Next Day Close'] - tf2[tf2['Signal']==1]['Next Day
Open']).sum()
上述代码生成图 7-37 的输出。
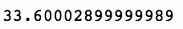
因此,我们可以看到,新的模型和新的测试时间段返回的分数超过了 33 点。让我们将此结果与相同时间段的盘中策略进行比较。
(sp['Close'].iloc[-2000:-1000] - sp['Open'].iloc[-2000:-1000]).sum()
这将产生图 7-38 的输出。
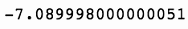
因此,在新的测试时段中,我们的逆向模型似乎表现出明显的优势。
到了现阶段,我们还可以对这个模型做一些扩展。我们甚至还没有开始使用技术指标或者模型中的基本数据,而且我们将交易限制在一天。所有这些都可以进行调整和扩展。
然而,这里我想介绍另一个使用完全不同算法的模型。该算法称为动态时间规整(dynamic time warping)。它所做的事情是向你提供一个表示两个时间序列之间相似性的度量。
7.3.3 建模与动态时间扭曲
开始之前,我们需要从命令行使用 pip 安装 fastdtw 库,命令是 pip install fastdtw。
完成后,我们将导入需要的附加库,如下所示。
from scipy.spatial.distance import euclidean
from fastdtw import fastdtw
接下来,我们将创建一个函数,该函数将接受两个序列并返回它们之间的距离。
def dtw_dist(x, y):
distance, path = fastdtw(x, y, dist=euclidean)
return distance
现在,我们将 16 年的时间序列数据分成不同的期间,每个期间长度为 5 天。我们为每个期间配上一个附加的点。这将用于创建我们的 x 和 y 数据,具体如下。
tseries = []
tlen = 5
for i in range(tlen, len(sp), tlen):
pctc = sp['Close'].iloc[i-tlen:i].pct_change()[1:].values * 100
res = sp['Close'].iloc[i-tlen:i+1].pct_change()[-1] * 100
tseries.append((pctc, res))
我们可以看看第一个序列,了解数据的样子。
tseries[0]
上述代码生成图 7-39 的输出。
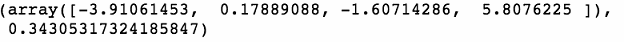
现在有了每个序列,我们就可以通过算法运行它们,来获得每个序列相对于其他序列的距离度量。
dist_pairs = []
for i in range(len(tseries)):
for j in range(len(tseries)):
dist = dtw_dist(tseries[i][0], tseries[j][0])
dist_pairs.append((i,j,dist,tseries[i][1], tseries[j][1]))
一旦我们有了这些,就可以将其放入一个 DataFrame 对象。我们将删除相互距离为零的序列,因为它们代表了相同的序列。我们还会根据序列的日期进行排序,只观测第一个序列在时间上排第二个序列之前的那些。
dist_frame = pd.DataFrame(dist_pairs, columns=['A','B','Dist', 'A Ret', 'B Ret'])
sf = dist_frame[dist_frame['Dist']>0].sort_values(['A','B']).reset_index(drop=1)
sfe = sf[sf['A']
最后,我们将交易限制到相互距离小于 1,而第一个序列的回报为正的情况。
winf = sfe[(sfe['Dist']<=1)&(sfe['A Ret']>0)]
winf
上述代码生成图 7-40 的输出。
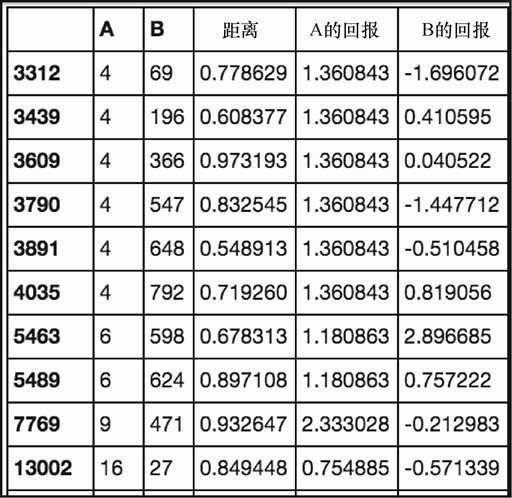
让我们看看排名靠前的模式,在绘制后是什么样子。
plt.plot(np.arange(4), tseries[6][0])
上述代码生成图 7-41 的输出。
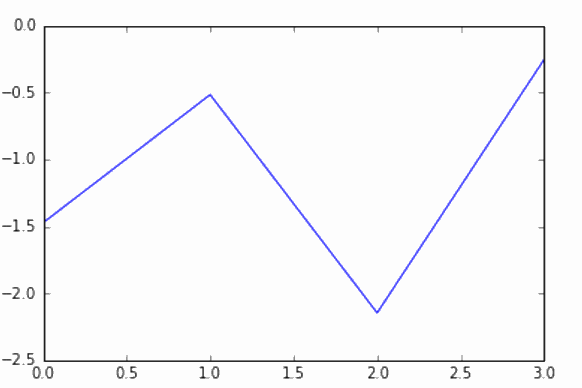
现在,我们将绘制第二个。
plt.plot(np.arange(4), tseries[598][0])
上面的代码将生成图 7-42 的输出。
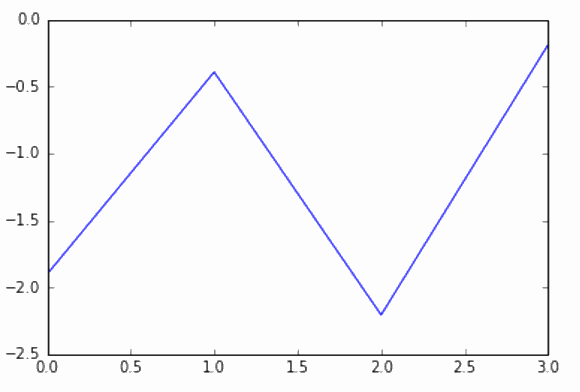
从图 7-41 和图 7-42 中可以看出,曲线几乎相同,这正是我们想要的。我们打算尝试找到所有在第二天获得正收益的曲线。然后,一旦我们发现某个曲线与这些有利可图的曲线之一非常相似,我们就会买入,以期待另一次盈利。
现在构造一个函数来评估我们的交易。对于相似的历史曲线,只要能返回正向的盈利,我们就会买入。如果发生无法盈利的情况,我们将删除它们。
excluded = {}
return_list = []
def get_returns(r):
if excluded.get(r['A']) is None:
return_list.append(r['B Ret'])
if r['B Ret'] < 0:
excluded.update({r['A']:1})
winf.apply(get_returns, axis=1);
现在所有交易的回报都存储于 return_list,让我们评估最终的结果。
get_stats(pd.Series(return_list))
上述代码生成图 7-43 的输出。
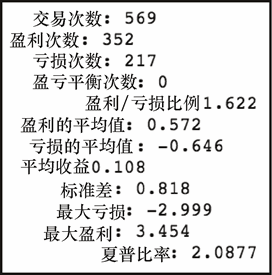
这些结果是迄今为止我们看到的最好结果。盈利/亏损比例和平均值远高出其他的模型。看来,这个新模型可能行得通,特别是与之前的模型相比。
现在,为了进一步检视该模型,我们应该通过其他的时间段来探索其鲁棒性。周期超过四天是否会改善模型?我们是否应该总是排除产生亏损的模式?还有很多额外的问题可以探索,但我会将它作为练习留给读者。如果你确实使用了这些技术,就知道我们只是浅尝辄止,还需要更多额外的周期测试,以适当地检验这些模型。





本书评论